Chapter 4 疗效和安全性分析
4.1 单臂疗效分析(只评估治疗后的结局,结局为分类或连续性资料)
4.1.2 软件功能
该模块提供了一个用于生成单组疗效分析统计表的交互式界面。它可以处理分类变量和连续性变量,并计算疗效指标的均值及95%可信区间(CI)或中位数及其95%CI。对于连续性变量,还能计算百分比及其可信区间。
4.1.4 操作步骤
- 选择要分析的变量:
- 在侧边栏中选择需要进行统计分析的变量。可选择多个变量,且选择的顺序会影响它们在结果表中的显示顺序。
- 选择连续变量的统计方法:
- 根据需要选择连续变量的统计方法(例如均值和标准差或中位数和四分位距)。
- QQ图查看(高级选项):
- 如果需要,可以查看QQ图,以判断数据的正态分布情况。
- 指定每个变量的统计方式(高级选项):
- 对于特定的连续性变量,可以单独指定其统计方式。
- 设置统计结果的显示方式:
选择如何在表格中标注连续性变量的统计方法(例如在表格底部统一注释或在每个字段旁边分别标注)。
决定是否在结果表中显示95%置信区间列。
- 调整小数位数:
- 设置百分比等统计数值的小数位数。
- 生成统计表:
- 点击相应按钮以生成或更新基线统计表。
- 查看和定制结果表格:
在主面板中查看生成的表格。
选择表格的外观风格(例如蓝色、绿色或灰色风格等),以适应不同的呈现需求。
- 描述性文本生成(可选):
- 如需,生成用于论文或报告中
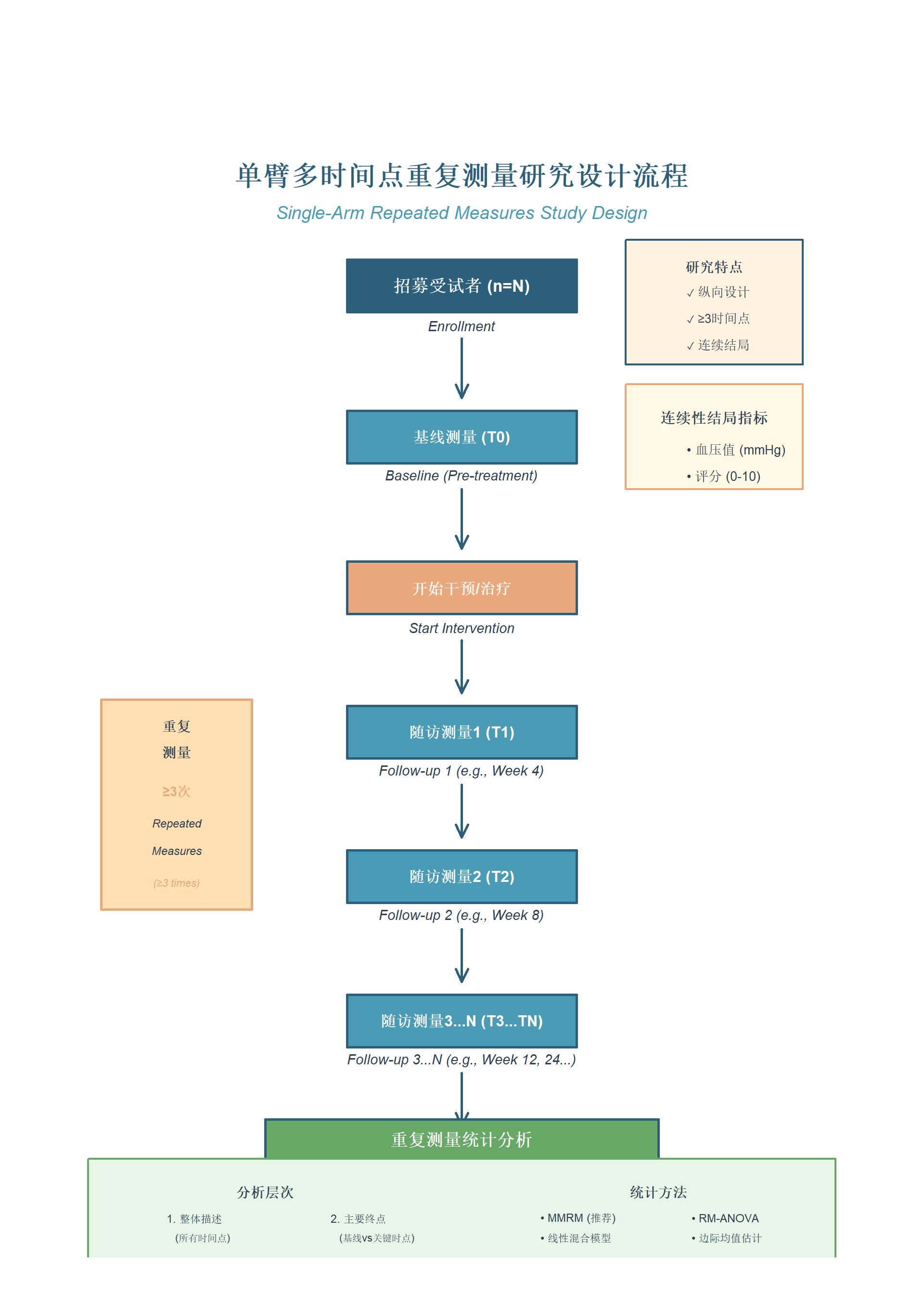
4.2 单臂疗效比较(连续性结局,三次及以上重复测量,如:血压值、评分等)
功能: 本工具用于单臂(单组)研究设计中,对同一组受试者在三个或更多时间点的连续性结局指标进行重复测量分析。支持MMRM、重复测量方差分析、线性混合效应模型等方法,自动生成出版级别的描述统计表、森林图和趋势图。特别强调: 本模块支持一键生成中英文论文初稿(包括摘要、引言、方法、结果、讨论和参考文献),基于您的分析结果和研究信息,AI自动撰写完整稿件,便于快速起草SCI论文。
结局类型: 疗效结局为连续性变量,如血压值、疼痛评分、生物标志物水平、实验室指标等数值型数据。
研究设计: 单臂多时间点重复测量设计(repeated measures design),即对同一组受试者在基线及多个随访时间点(≥3个)测量同一连续性结局指标。没有对照组,通过不同时间点的变化趋势评估治疗效果。适用于前瞻性或回顾性研究。
主要特点:
- 支持宽表格式(一个患者一行)和长表格式(一个患者多行),灵活适配不同数据结构。
- 提供三种统计方法:MMRM(临床试验金标准)、重复测量方差分析(经典方法)、线性混合效应模型(最灵活)。
- 自动处理缺失值(MAR假设下),无需删除不完整数据。
- 分层分析策略:整体描述→主要终点→次要终点,符合临床试验报告规范。
- 支持多重比较校正(Bonferroni、Holm、Dunnett等多种方法)。
- 一键生成出版级别表格和森林图,参数可实时调整预览。
- 用户界面友好,全程指导,帮助理解重复测量分析的核心概念。
- 自动生成统计方法注解和Word报告,符合CONSORT和ICH指南。
- 一键查看和下载分析的 R 源代码,避免黑箱化,可溯源和复用。
- 论文生成功能: 基于分析结果,AI智能生成中英文论文初稿,包括Pubmed文献检索的背景和讨论,支持自定义研究信息(如人群、干预、终点),生成的稿件可直接修改投稿。
一键自动生成以下图表示例:

(Table 1: 基线特征表,仅宽表格式可生成)
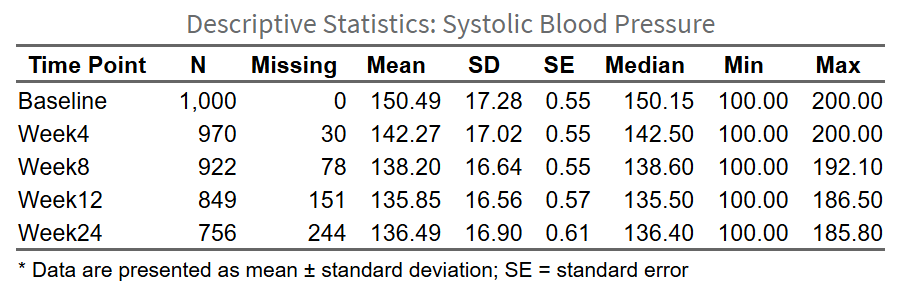
(所有时间点描述统计表)
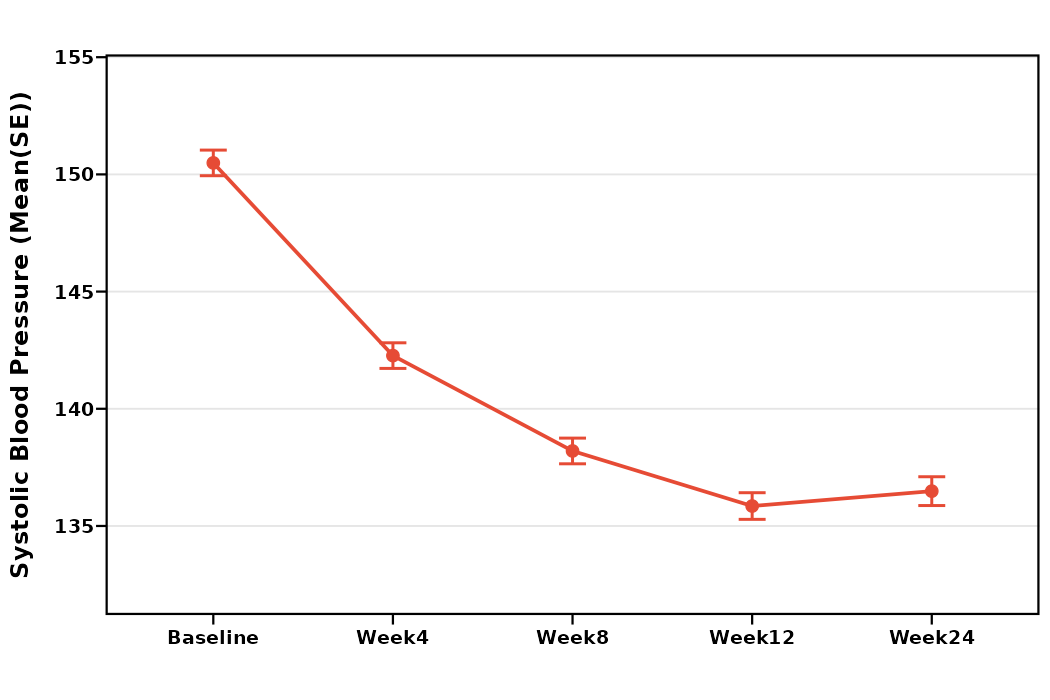
(多时间点趋势折线图)
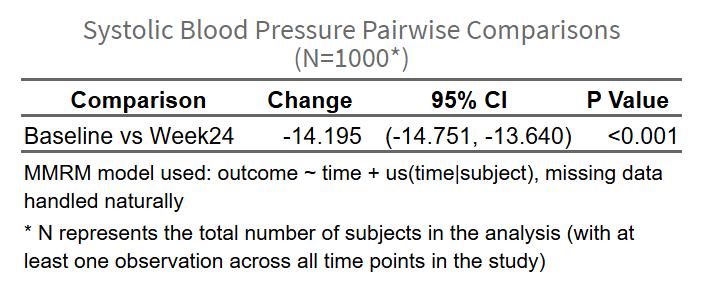
(主要终点分析表)

(主要终点森林图)
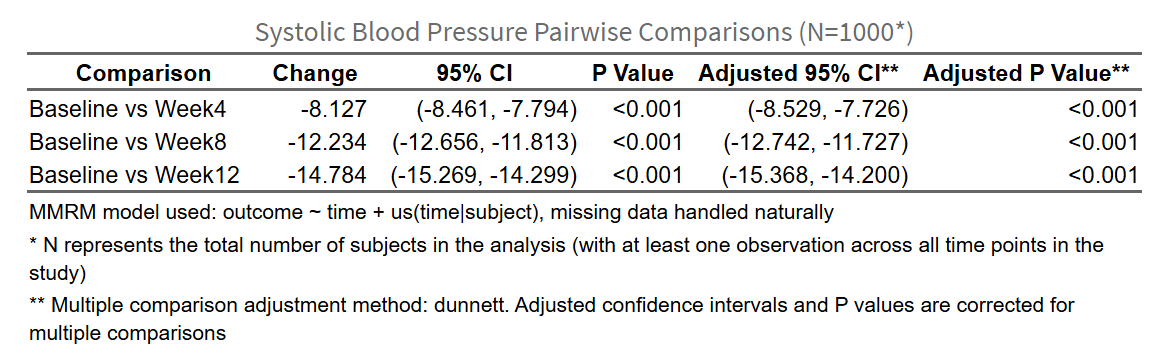
(次要终点两两比较表)

(次要终点森林图)
4.2.1 基础知识
4.2.1.1 设计概述
单臂多时间点重复测量研究(single-arm repeated measures study)是临床研究中常见的纵向设计,特点如下:
- 无对照组:仅包含一组受试者,患者作为自身对照
- 重复测量:在多个时间点(≥3)对同一患者进行测量
- 连续性结局:结局变量为数值型数据(如血压、评分、浓度等)
- 时间相关性:同一患者的多次观测值存在相关性,违反独立性假设
- 专门统计方法:需使用考虑个体内相关性的混合效应模型或重复测量方差分析
4.2.1.2 适用场景
- 药效学研究:评估药物对生理指标的时间效应曲线
- 慢性病管理:观察长期治疗过程中指标的变化趋势
- 康复研究:评估康复训练对功能评分的持续改善
- 剂量递增研究:探索不同剂量阶段的效应变化
- 初步探索性研究:在进行大型RCT前评估干预的可行性
4.2.2 设计的优势与局限
4.2.3 三种统计方法详解
本模块提供三种重复测量分析方法,各有特点:
4.2.3.1 MMRM(Mixed Model for Repeated Measures)⭐推荐
原理:
使用混合模型,将时间点作为固定效应,允许不同时间点间有不同的协方差结构(通常用非结构化协方差矩阵)。模型形式: \[
Y_{ij} = \mu + \alpha_j + u_i + \epsilon_{ij}
\] 其中 \(Y_{ij}\) 是受试者 \(i\) 在时间点 \(j\) 的观测值,\(\alpha_j\) 是时间点固定效应,\(u_i \sim N(0, \sigma_u^2)\) 是随机截距,\(\epsilon_{ij}\) 是残差。协方差结构 \(\text{Cov}(Y_{ij}, Y_{ik})\) 可自由估计。
适用场景: - 临床试验(特别是FDA/EMA监管的研究) - 存在缺失值(MAR假设下无偏) - 需要灵活的协方差结构建模
优点: - FDA/EMA指南推荐,业界金标准 - 有效处理MAR缺失数据,无需删除或填补 - 提供稳健的标准误估计 - 允许不平衡数据(各受试者测量次数可不同)
缺点: - 计算复杂度较高 - 对协方差结构设定敏感(本模块自动选择合适结构)
R包: mmrm
4.2.3.2 重复测量方差分析(Repeated Measures ANOVA)
原理:
经典的方差分析扩展,考虑组内设计(受试者作为区组)。假设球形性(各时间点方差相等且协方差相等)。模型形式: \[
Y_{ij} = \mu + \alpha_j + u_i + \epsilon_{ij}
\] 与MMRM类似,但协方差结构更严格(复合对称或球形假设)。
适用场景: - 完整数据或缺失很少 - 球形假设满足(Mauchly检验,本工具自动检验并校正) - 追求经典方法的研究
优点: - 文献中应用广泛,易于理解 - 计算效率高,结果稳定 - 教科书常见方法,审稿人熟悉
缺点: - 对缺失值敏感,采用列表删除(失去效率) - 球形假设可能不满足(需Greenhouse-Geisser或Huynh-Feldt校正) - 不如MMRM灵活
R包: afex
4.2.3.3 线性混合效应模型(Linear Mixed-Effects Model, LMM)
原理:
最灵活的方法,可同时建模固定效应和随机效应。支持随机斜率、复杂嵌套结构等。模型形式: \[
Y_{ij} = \beta_0 + \beta_1 \text{Time}_j + u_{0i} + u_{1i} \text{Time}_j + \epsilon_{ij}
\] 其中 \(u_{0i}\) 是随机截距,\(u_{1i}\) 是随机斜率(可选),允许每个受试者有不同的变化速率。
适用场景: - 需要建模个体差异(如探索哪些患者改善更快) - 复杂数据结构(如多中心、嵌套设计) - 研究方法学问题(如协方差选择、缺失机制)
优点: - 灵活性最强,可扩展到广义线性混合模型(GLMM) - 可处理不平衡和缺失数据 - 可建模时间趋势(线性、二次等)
缺点: - 模型复杂,需要统计学背景 - 收敛问题较常见(尤其随机效应多时) - 结果解释需谨慎
R包: lmerTest(提供p值)或 lme4
4.2.4 边际均值与对比检验原理
什么是边际均值(Estimated Marginal Means, EMMs)?
边际均值是基于拟合模型预测的、已调整其他变量影响后的各时间点平均值。与原始算术平均值相比: - 原始均值: 直接计算各时间点观测值的平均数,未考虑模型结构和缺失值 - 边际均值: 通过模型估计,考虑了个体随机效应或协方差结构,在数据不平衡或有缺失时更准确反映总体真实水平
例如:
假设某研究中部分患者只测量了基线和4周,另一部分测量了基线、4周和12周。原始均值会因样本构成不同而有偏差,而边际均值通过模型调整,给出更可靠的估计。
对比检验(Contrasts):
对比检验用于比较不同时间点的边际均值差异。本模块支持以下比较策略:
相邻比较(Consecutive): 比较相邻时间点,如 T2 vs T1, T3 vs T2 等。适合探索每个阶段的变化。
基线比较(Baseline): 所有后续时间点与基线比较,如 T2 vs T1, T3 vs T1, T4 vs T1。最常用,符合临床逻辑(治疗后vs治疗前)。
全部两两比较(All Pairwise): 所有可能的时间点组合,如 T2 vs T1, T3 vs T1, T3 vs T2, T4 vs T1, T4 vs T2, T4 vs T3。适合探索性分析。
自定义比较(Custom): 用户指定特定的时间点对,如只比较 T1 vs T4(主要终点)。
每个对比输出: - 变化值(Change): 边际均值的差值,如 EMM(T2) - EMM(T1) - 标准误(SE): 差值的标准误 - 95%置信区间(CI): 差值的可信范围 - P值: 检验差值是否显著不为0
4.2.5 多重比较校正详解
为什么需要多重比较校正?
当进行多个统计检验时(如多个时间点两两比较),即使原假设为真,每次检验犯I型错误的概率为 \(\alpha\)(通常0.05)。但整体错误率会累积: \[ \text{整体错误率} \approx 1 - (1-\alpha)^m \] 其中 \(m\) 是检验次数。例如,10次独立检验的整体错误率约 \(1 - 0.95^{10} \approx 0.40\),远高于名义的0.05。
何时需要校正?
- 确认性分析: 用于支持主要结论、监管申报时,必须校正
- 多个次要终点: 次要终点的两两比较通常需要校正
- 正式统计推断: 当需要控制整体错误率时
何时可以不校正?
- 预先指定的主要分析: 如只比较基线与特定关键时点(主要终点),无需校正
- 探索性分析: 仅用于生成假设,不作为最终结论依据
- 描述性统计: 仅描述趋势,不强调p值
常见校正方法:
本模块支持以下校正方法(通过 emmeans 包的 p.adjust 参数实现):
| 方法 | 原理 | 特点 | 推荐场景 |
|---|---|---|---|
| 无(none) | 不校正 | 最宽松,功率最高 | 预先指定的单一比较 |
| Bonferroni | \(\alpha' = \alpha/m\) | 最保守,严格控制FWER | 检验次数少(≤5次) |
| Holm | 逐步Bonferroni | 比Bonferroni功率高,仍控制FWER | 需要严格控制FWER |
| Dunnett | 专为多组与对照比较设计 | 功率最高,适合基线比较 | 推荐:所有时点vs基线 |
| BH (Benjamini-Hochberg) | 控制FDR而非FWER | 比Bonferroni宽松,功率高 | 探索性研究,关注发现 |
| FDR | 同BH | FDR ≤ α | 大量检验时 |
FWER vs FDR: - FWER(Family-Wise Error Rate): 至少犯一次I型错误的概率,严格控制 - FDR(False Discovery Rate): 假阳性占所有阳性发现的比例,相对宽松
推荐: - 如果次要终点分析是”所有后续时点vs基线”,强烈推荐使用 Dunnett法,它专门为此设计,功率最高。 - 如果是全部两两比较且需要严格控制,用 Holm法。 - 如果是探索性分析,可用 BH法 或 不校正,但在论文中注明。
4.2.6 准备数据
4.2.6.1 数据格式选择
本模块支持两种数据格式:
1. 宽表格式(Wide Format) ⭐推荐
- 每行代表一个患者 - 每列代表一个时间点的结局值 - 优点:可生成完整的基线特征表(Table 1)和疗效分析 - 示例:
| PatientID | Age | Sex | Baseline | Week4 | Week8 | Week12 | Week24 |
|---|---|---|---|---|---|---|---|
| P0001 | 54 | Male | 148.3 | 140.5 | 133.8 | 135.1 | 132.4 |
| P0002 | 62 | Female | 153.7 | 145.2 | 138.6 | 136.9 | NA |
| P0003 | 47 | Male | 145.1 | 137.8 | 130.4 | 131.7 | 129.8 |
2. 长表格式(Long Format)
- 每行代表一次测量 - 需要患者ID列、时间点列、结局值列 - 缺点:无法生成基线特征表(因为人口学变量重复出现) - 示例:
| PatientID | Timepoint | SBP | Age | Sex |
|---|---|---|---|---|
| P0001 | Baseline | 148.3 | 54 | Male |
| P0001 | Week4 | 140.5 | 54 | Male |
| P0001 | Week8 | 133.8 | 54 | Male |
| P0001 | Week12 | 135.1 | 54 | Male |
| P0001 | Week24 | 132.4 | 54 | Male |
| P0002 | Baseline | 153.7 | 62 | Female |
| P0002 | Week4 | 145.2 | 62 | Female |
| P0002 | week8 | 138.6 | 62 | Female |
| P0002 | Week12 | 136.9 | 62 | Female |
| P0002 | Week24 | NA | 62 | Female |
4.2.6.2 数据准备要点
宽表格式: - 每个时间点变量必须是数值型(numeric) - 时间点变量名要有意义(如 Baseline, Week4 而非 V1, V2) - 缺失值用 NA 表示 - 基线特征变量(Age、Sex等)每个患者一行
长表格式: - 患者ID列:唯一标识每个患者 - 时间点列:可以是字符型或因子型,用有意义的标签(如 “Baseline”, “Week4”) - 结局值列:必须是数值型 - 每个患者的时间点值应完整(缺失的时间点直接省略该行)
常见问题: - 变量名无意义: 如果您的数据用 V1, V2, V3 表示时间点,请在”重编码”模块中改为有意义的名称(Baseline, Week4, Week8等) - 时间点顺序: 确保按照时间顺序选择变量(软件会按您选择的顺序分析) - 结局变量不是numeric: 返回”定义字段”模块,将结局变量定义为数值型
4.2.7 进入模块
点击软件顶部菜单的”疗效和安全性分析”,然后点击”单臂疗效比较(连续性结局,三次及以上重复测量)“进入模块。
模块分为三个tab: 1. 使用说明:本指南 2. 疗效比较分析:数据分析操作界面 3. 下载Word文件:生成报告和论文初稿
4.2.8 疗效比较分析
4.2.8.1 第一步:选择数据格式和统计方法
在页面顶部,您会看到两个关键选择:
1. 数据格式选择: - 宽表格式(推荐): 一个患者一行,可进行完整分析(包括基线特征表) - 长表格式: 一个患者多行,仅进行疗效分析(无法生成基线特征表)
选择后,下方会显示相应的说明和示例数据链接。
2. 统计方法选择: - MMRM(推荐): 临床试验金标准,适合有缺失值的情况 - 重复测量方差分析: 经典方法,适合完整数据 - 线性混合效应模型: 最灵活,适合复杂探索
点击方法名称旁边的 ⓘ 图标,可查看各方法的详细说明和选择建议。

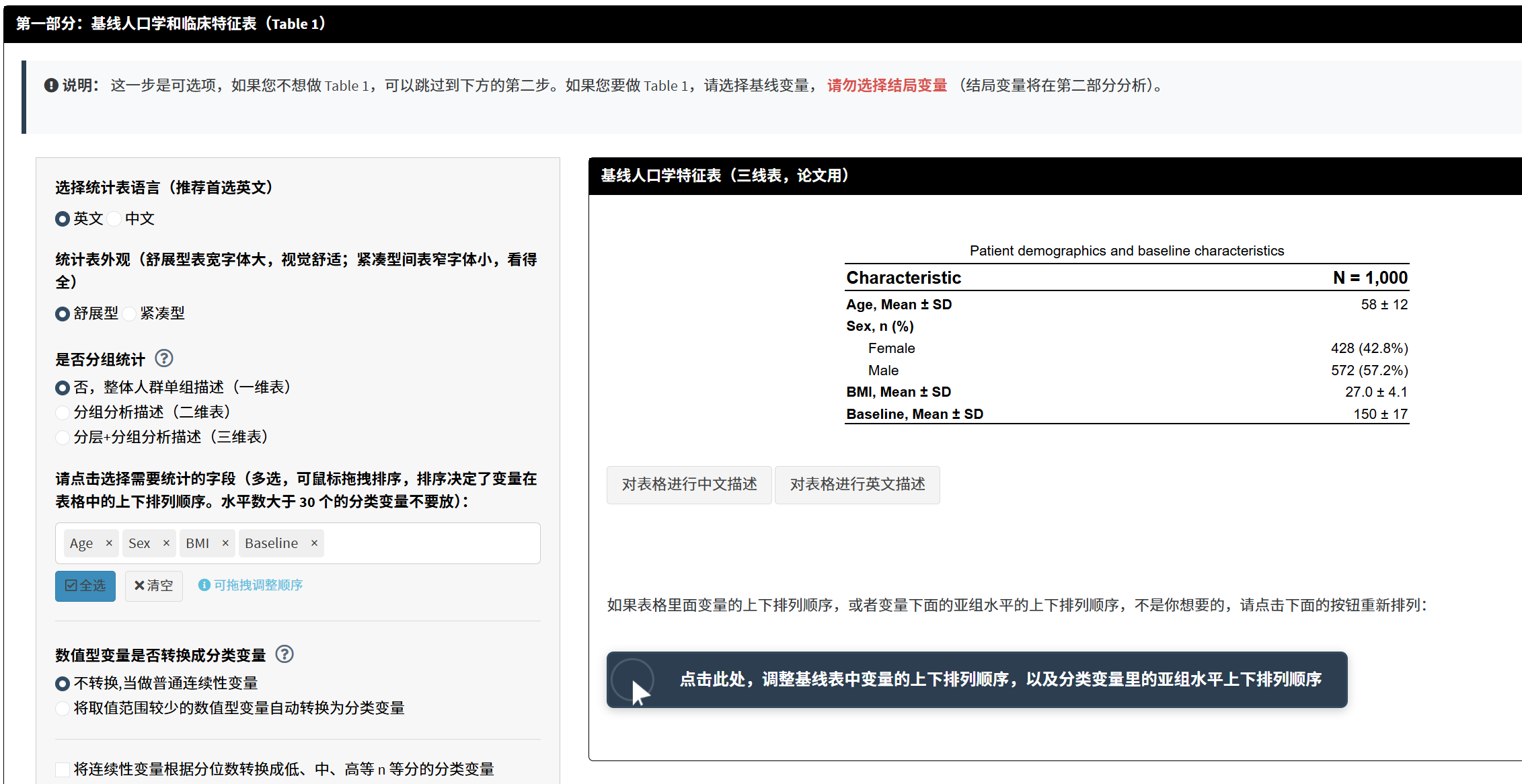
4.2.8.2 第二步:基线特征表(Table 1)- 仅宽表格式
注意: 如果您选择了长表格式,此部分不会显示,直接跳到第三步。
目的: 描述研究人群的基线特征(年龄、性别、BMI等),用于论文的”材料与方法”或”结果”部分。
操作步骤:
在”选择基线变量”中,选择人口学和临床特征变量
- 例如:Age, Sex, BMI, Comorbidities等
- 重要: 不要选择结局变量(如Baseline、Week4等),结局变量在后面分析
点击”生成/更新Table 1”
结果显示:
- 描述性统计表:连续变量显示均值±SD或中位数(IQR),分类变量显示计数(%)
- 可点击”生成表格描述”,AI自动撰写表格描述文字
- 可下载表格图片或复制到Word
统计知识讲解: - 连续变量: 正态分布用均值±SD,偏态分布用中位数(IQR)。软件自动判断分布(Shapiro-Wilk检验) - 分类变量: 报告各类别的频数和百分比 - 单臂研究: 无组间比较,因此不报告p值(p值需要两组)
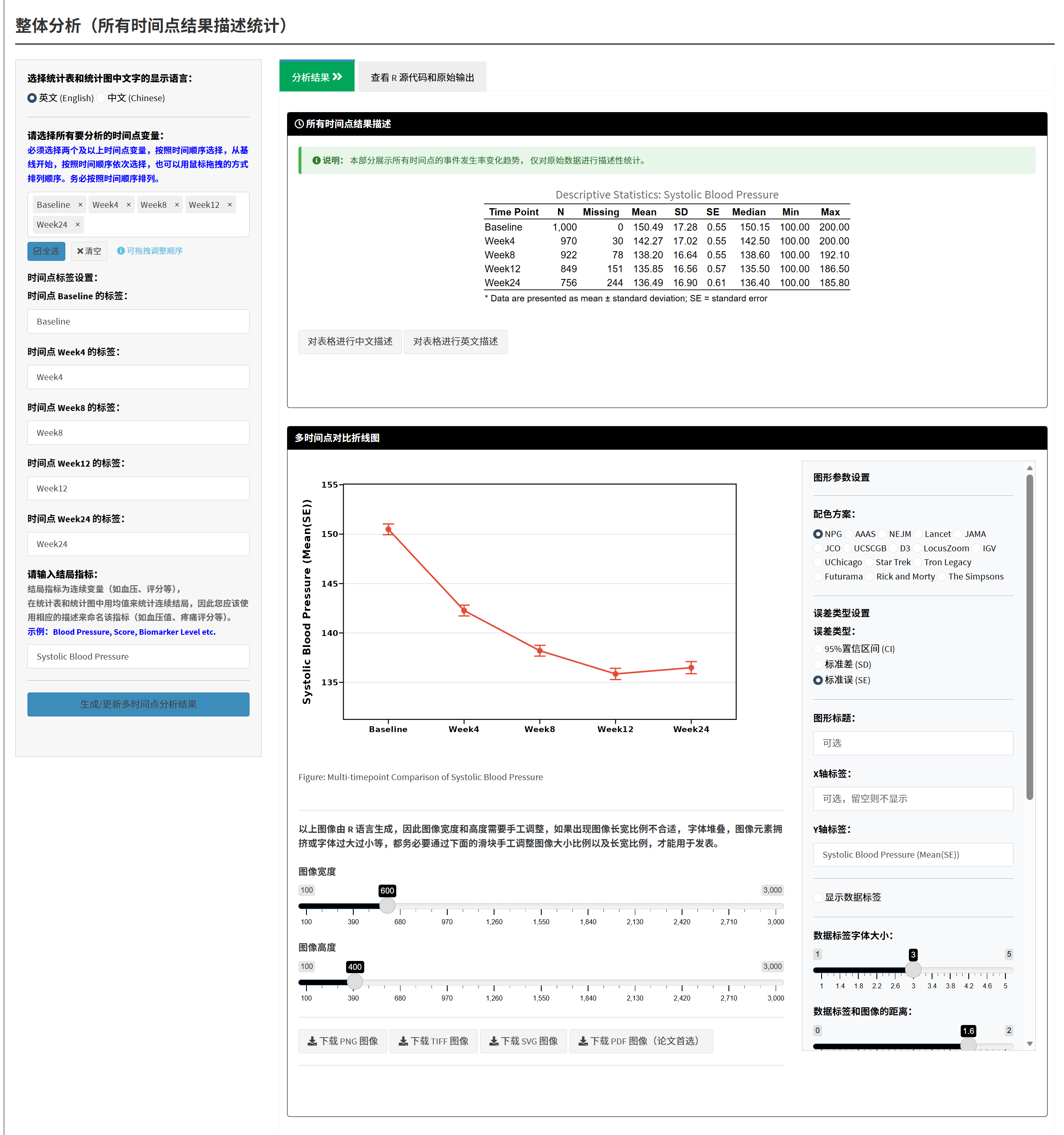
4.2.8.3 第三步:整体分析(所有时间点描述统计)
目的: 描述所有时间点的结局指标变化趋势,为后续分析提供概览。
操作步骤:
1. 变量选择:
如果是宽表格式: - 在”请选择所有要分析的时间点变量”中,选择≥3个时间点变量 - 按时间顺序选择(可拖拽排序):如 Baseline → Week4 → Week8 → Week12 → Week24 - 必须按照真实的时间顺序,否则结果会出错
如果是长表格式: - 选择患者ID变量(如 PatientID) - 选择时间点变量(如 Timepoint) - 选择结局变量(如 SBP,必须是数值型) - 在”请选择所有要分析的时间点水平”中,选择≥2个时间点值,并按时间顺序排列
2. 时间点标签设置: - 为每个时间点设置标签(如”基线”、“第4周”、“第8周”等) - 这些标签将显示在所有表格和图形中,建议使用简短且有意义的名称
3. 结局指标设置: - 输入结局指标名称,如”收缩压”、“疼痛评分”等 - 选择显示语言(英文或中文)
4. 点击”生成/更新多时间点分析结果”
结果展示:
- 描述统计表:
- 显示各时间点的样本量、均值、标准差、标准误
- 可点击”生成表格描述”,AI自动撰写描述文字
- 表格可下载或复制
- 多时间点趋势折线图:
- 显示均值随时间的变化趋势
- 误差线可选择:95%CI、SD或SE
- 右侧参数面板可实时调整:
- 配色方案(NPG、NEJM、Lancet等期刊风格)
- 误差类型(置信区间、标准差、标准误)
- 图形标题和轴标签
- 是否显示数据标签
- Y轴范围和刻度(自动或手动)
- 字体大小和边距
统计知识讲解: - 描述统计: 此部分仅对原始数据进行描述,不进行统计检验。目的是展示数据的整体分布和趋势 - 标准误vs标准差: 标准误(SE)反映均值的不确定性,标准差(SD)反映个体变异程度。科研论文通常用SE或95%CI - 缺失值: 不同时间点的样本量可能不同(因为失访),此时不需要做缺失值填补,后续做重复测量分析的时候如果选MMRM法,软件会自动处理缺失值。
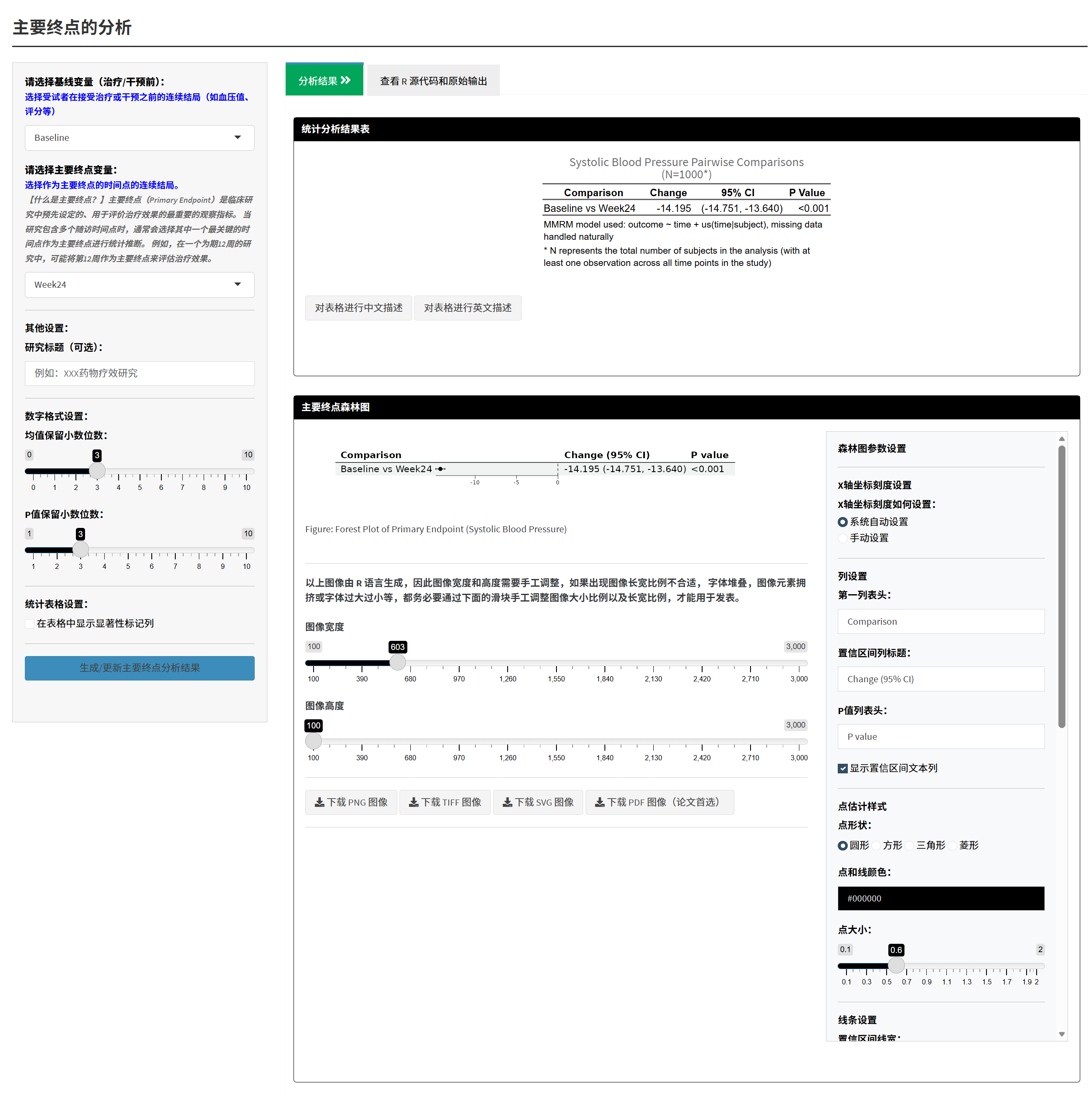
4.2.8.4 第四步:主要终点分析
目的: 比较基线与预先指定的关键随访时间点(主要终点),这是临床研究的主要结论依据。
什么是主要终点?
主要终点(Primary Endpoint)是研究中预先设定的、用于评价疗效的最重要观察指标和时间点。例如,在一个为期24周的降压研究中,可能将”第12周的收缩压”作为主要终点,因为此时疗效稳定且临床意义最大。
操作步骤:
1. 选择基线和主要终点:
如果是宽表格式: - 基线变量:选择治疗前的结局变量(如 Baseline) - 主要终点变量:选择关键的随访时间点(如 Week12)
如果是长表格式: - 基线时间点:选择治疗前的时间点值(如 “Baseline”) - 主要终点时间点:选择关键的随访时间点值(如 “Week12”)
2. 其他设置: - 研究标题(可选) - 数字格式:均值小数位(如3位)、P值小数位(如3位) - 表格设置:是否显示显著性标记(*表示p<0.05)
3. 点击”生成/更新主要终点分析结果”
结果展示:
- 统计分析结果表:
- 显示基线和主要终点的边际均值、标准误、95%CI
- 显示变化值(Change from Baseline)及其95%CI和P值
- 可点击”生成表格描述”,AI自动撰写结果文字
- P<0.05表示主要终点显著改善
- 主要终点森林图:
- 横轴为变化值,纵轴为比较
- 点估计值和95%CI一目了然
- 参考线在0处(表示无变化)
- 右侧参数面板可调整:
- 列标题(如”Comparison”、“Change (95% CI)”)
- 点的形状、颜色和大小
- 线条宽度和样式
- 字体大小和类型
- 表格底纹颜色
统计知识讲解: - 边际均值vs原始均值: 边际均值通过模型调整,考虑了个体差异和缺失值,更准确 - 变化值: 主要终点的边际均值 - 基线的边际均值 - P值: 检验变化值是否显著不为0。P<0.05表示有统计学意义,但需结合临床意义判断(如血压降低5 mmHg是否有临床价值) - 95%CI: 变化值的可信范围。如果CI不包含0,则p<0.05
4.2.8.5 第五步:次要终点分析(两两比较)
注意: 此部分需要先完成主要终点分析。
目的: 探索其他时间点的变化,或进行多个时间点的两两比较,提供更全面的疗效评价。
什么是次要终点?
次要终点(Secondary Endpoints)是辅助性观察指标,用于支持主要终点或探索其他效应。例如,除了第12周(主要终点),还想知道第4周、第8周、第24周的变化情况。
操作步骤:
完成主要终点分析后,“次要终点的对比分析”部分会自动显示
选择比较类型:
- 相邻时间点比较: 比较相邻的时间点,如 Week4 vs Baseline, Week8 vs Week4
- 所有可能的两两比较: 所有时间点的组合,如 Week4 vs Baseline, Week8 vs Baseline, Week8 vs Week4 等
- 后续时间点与基线比较(推荐): 所有随访时点分别与基线比较,如 Week4 vs Baseline, Week8 vs Baseline, Week12 vs Baseline
- 自定义比较: 勾选您想比较的特定时间点对
多重比较校正方法:
- 点击校正方法旁边的 ⓘ 图标,查看详细说明
- 推荐方法:
- 如果选择”后续时间点与基线比较”,推荐 Dunnett法(专为此设计,功率最高)
- 如果选择”所有可能的两两比较”,推荐 Holm法(严格控制FWER)
- 如果是探索性分析,可选 Benjamini-Hochberg (BH)法 或 不校正
点击”生成/更新次要终点分析结果”
结果展示:
- 两两比较统计表:
- 列出所有比较对的变化值、95%CI(已校正)、P值(已校正)
- 如果进行了多重比较校正,表头会注明方法
- 可点击”生成表格描述”,AI自动撰写
- 次要终点森林图:
- 显示所有比较对的变化值和CI
- 参数调整同主要终点森林图
统计知识讲解: - 多重比较问题: 当进行多个检验时,假阳性率累积。例如,5个比较的整体错误率约 1-(0.95)^5 ≈ 23%,远高于5% - 何时校正: - 确认性分析(用于最终结论)必须校正 - 探索性分析可不校正,但需在论文中说明 - 如果研究方案预先指定只比较基线与特定时点,无需校正 - Dunnett法优势: 当所有比较都是”vs基线”时,Dunnett法考虑了比较间的相关性,功率比Bonferroni高得多
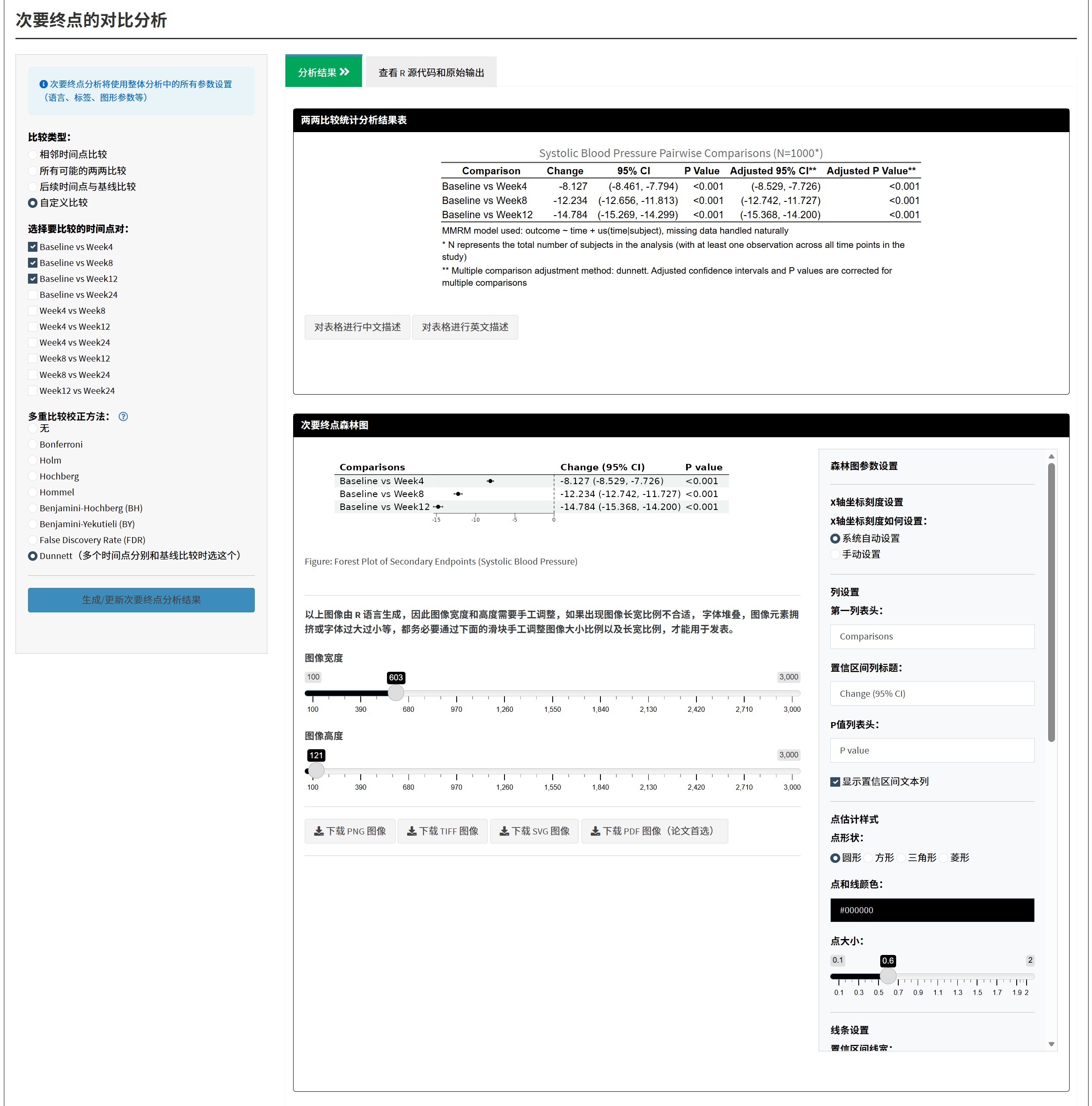
4.2.9 生成 R 源代码
在每个分析结果的右侧标签栏,点击”查看 R 源代码和原始输出”,可以: - 查看本次分析的完整R代码 - 查看模型的原始输出(如模型拟合详情、假设检验等) - 下载分析数据集(.RData格式) - 下载R源代码(带中英文双语注释)
这确保了分析的可重复性和透明性,审稿人和期刊编辑可以验证您的分析过程。
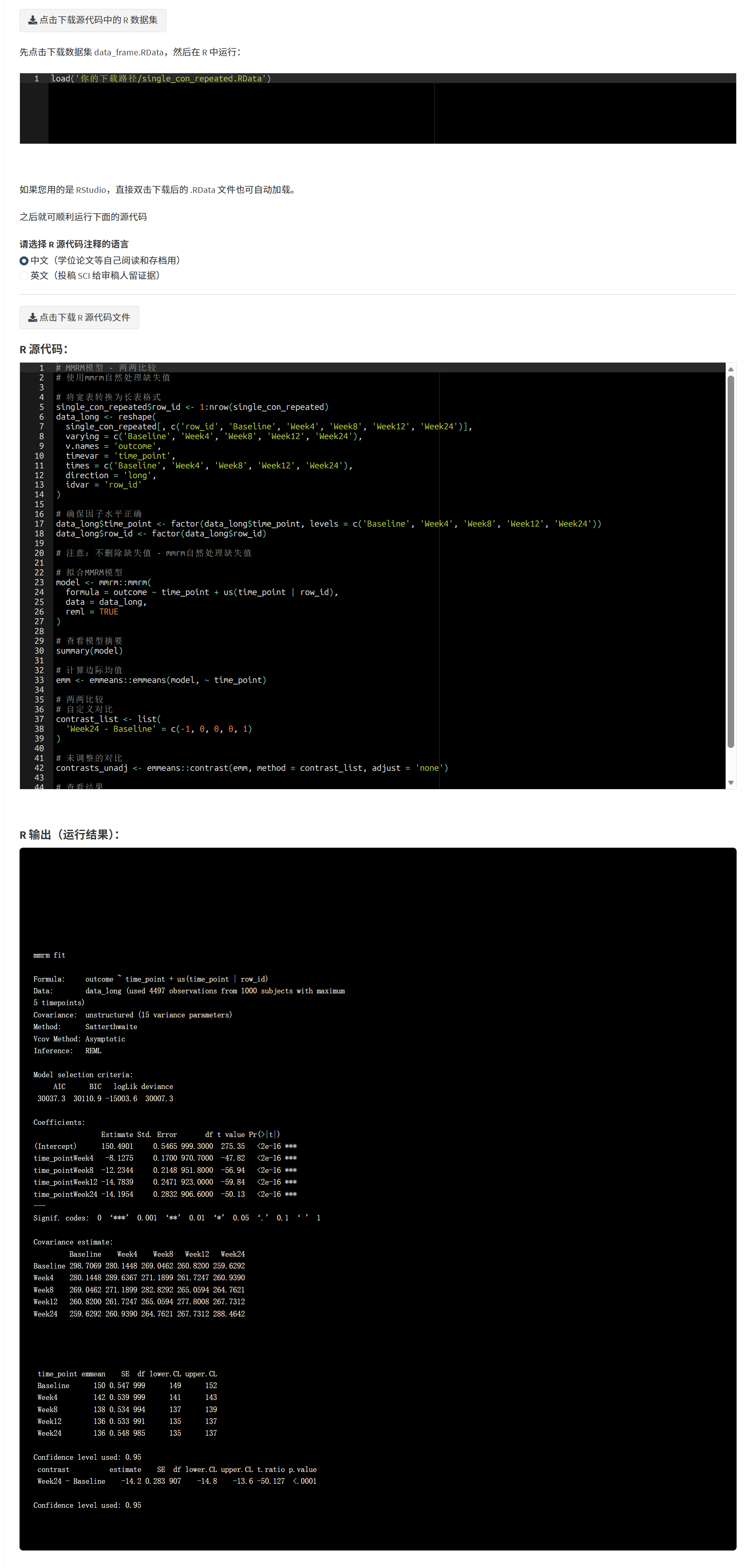
4.2.10 下载Word文件和论文初稿
点击”下载Word文件”tab,进入报告和论文生成界面。
4.2.10.1 选项1:下载分析报告
点击”下载分析报告”,生成包含所有分析结果的Word文档: - Table 1(如果做了) - 多时间点描述统计表和趋势图 - 主要终点分析表和森林图 - 次要终点分析表和森林图(如果做了) - 自动生成的统计方法注释
适合:仅需要分析结果,不需要完整论文的情况。
4.2.10.2 选项2:一键生成论文初稿 ⭐强烈推荐
这是本模块的核心功能之一! AI将基于您的分析结果,自动撰写完整的中英文论文初稿,包括: - 标题:根据研究设计和结局自动生成 - 摘要:结构化摘要(目的、方法、结果、结论)+ 关键词 - 引言:Pubmed数据库检索相关文献,AI综合撰写背景和研究gap - 材料与方法: - 患者资料和入排标准(需您提供) - 干预措施(需您提供) - 随访安排(需您提供) - 统计分析方法(自动生成,基于您使用的方法) - 结果: - 基线特征描述(基于Table 1) - 多时间点结果描述(基于描述统计表和图) - 主要终点结果(基于主要终点分析) - 次要终点结果(基于次要终点分析,如果做了) - 所有表格和图形自动插入 - 讨论:Pubmed数据库检索相关文献,AI综合撰写讨论、局限性和未来方向 - 参考文献:自动标注引用并生成参考文献列表
操作步骤:
点击”一键生成论文初稿”按钮,弹出信息收集表单
逐步填写研究信息(AI需要这些信息来撰写论文):
问题1: 请描述您的研究人群(必填)
- 例如:“高血压患者”、“2型糖尿病合并肾病患者”
- 如果是健康人群,输入”健康人群”
问题2: 请详细描述治疗/干预的具体方案(必填)
- 例如:“amlodipine 5 mg 口服,每日一次”
- 或:“认知行为治疗,每周一次,每次50分钟,共12周”
- 需要包含剂量、频率、疗程等细节
问题3: 请选择研究类型(必填)
- 前瞻性研究:预先设计并前瞻性收集数据
- 回顾性研究:利用已有的病历或数据库
问题4: 请描述研究的主要终点(必填)
- 例如:“从基线到第12周的收缩压变化值”
- 或:“从基线到第24周的疼痛评分变化值”
- 软件会自动填充默认值,您可以修改
确认数据准备(非常重要!):
在生成论文前,必须勾选以下三个确认项:
☑ 数据集中的变量名使用了有意义的英文单词
(例如:Age、Gender、Baseline、Week4,而不是 X1、X2、V1、V2)☑ 分类变量的数据标签使用了有意义的文字
(例如:Male/Female、Yes/No,而不是 0/1、1/2/3)☑ 已完成前面所有必要的统计分析步骤
(包括整体分析、主要终点分析等)为什么这些很重要?
AI需要理解您的数据才能生成高质量论文。如果变量名是 V1、V2 或数据标签是 0、1,AI无法知道它们的含义,生成的论文将充满错误和无意义的描述。如果您的数据尚未符合要求:
- 点击浏览器后退按钮
- 返回”重编码”或”定义字段”模块
- 将所有变量名改为有意义的英文单词
- 将所有分类变量的数字编码改为文字标签
- 重新完成所有分析步骤
- 再回到本页面生成论文
选择语言并生成:
- 点击”下载英文论文”或”下载中文论文”
- AI生成需要5-10分钟,请耐心等待
- 生成过程中会显示进度提示(如”撰写背景部分”、“检索文献”等)
- 请勿关闭浏览器或刷新页面
下载并审阅论文初稿:
- 生成完成后,Word文档自动下载
- 用 Microsoft Office Word 打开(WPS可能出现格式问题)
- 仔细审阅AI生成的内容,特别是:
- 标题是否准确
- 摘要是否概括全文
- 引言和讨论的文献引用是否相关
- 结果描述是否与表格图形一致
- 统计方法描述是否准确
人工修改和完善:
- AI生成的是初稿,需要您根据研究实际情况修改
- 重点修改部分:
- 患者入排标准(AI只给出模板,需补充具体标准)
- 干预措施细节(根据您的实际方案完善)
- 随访安排(补充具体的随访时间点和内容)
- 讨论部分的深度分析(AI提供框架,您需要结合专业知识深化)
- 检查所有数值和表格是否正确嵌入
- 润色语言和表达
AI论文生成的优势: - 节省时间:从零开始写论文可能需要数周,AI初稿仅需10分钟 - 文献检索:自动检索Pubmed相关文献,生成有据可依的背景和讨论 - 规范格式:符合医学论文的标准结构和写作规范 - 双语支持:同时生成中英文版本,便于国内外投稿
注意事项: - AI生成的论文是基于模板和文献检索,需要您的专业知识来完善和验证 - 不要完全依赖AI,必须仔细审阅每一部分 - 如果AI生成失败(网络问题),可以重试 - 论文中的统计方法描述是基于您选择的方法自动生成的,一般无需修改

4.2.11 常见问题解答(FAQ)
Q1: 我的数据缺失很多,还能用这个模块吗?
A: 可以!这正是MMRM和LMM的优势。只要缺失机制是MAR(Missing At Random,即缺失与已观测变量相关,与未观测变量无关),这些方法能给出无偏估计。但如果缺失率超过30%,建议在论文中讨论缺失数据的影响。
Q2: MMRM、RM-ANOVA和LMM应该选哪个?
A: - 如果您的数据有缺失值或不平衡,推荐MMRM(临床试验金标准) - 如果数据完整且想用经典方法,选 RM-ANOVA - 如果需要探索个体差异或复杂模型,选 LMM - 如不确定,选MMRM是最安全的
Q3: 主要终点和次要终点有什么区别?
A: 主要终点是预先指定的、用于评价主要疗效的观察指标和时间点,通常只有一个,用于确认性推断。次要终点是辅助性指标,用于提供更多信息或探索性分析。在论文中,主要终点的结果是核心结论,次要终点提供支持证据。
Q4: 次要终点的两两比较是否必须进行多重比较校正?
A: 不一定。如果研究方案预先指定了不进行校正(如明确为探索性分析),可以不校正。但在正式的确认性分析中,或者用于监管申报时,通常需要校正。建议: - 确认性分析:必须校正,推荐Dunnett(vs基线)或Holm(全部两两) - 探索性分析:可不校正,但需在论文中明确说明
Q5: 为什么我的森林图CI很宽?
A: 置信区间宽度取决于样本量和变异性。如果: - 样本量小(如<30):CI会较宽 - 个体差异大:CI会较宽 - 缺失值多:有效样本减少,CI变宽 这是正常的统计不确定性反映,不必过度担心。
Q6: AI生成的论文可以直接投稿吗?
A: 不可以! AI生成的是初稿,必须经过您的仔细审阅、修改和完善。您需要: - 核对所有数值和分析结果 - 补充具体的入排标准、干预细节、随访安排 - 深化讨论部分,结合您的专业知识 - 检查引用文献的相关性和准确性 - 润色语言表达
把AI初稿当作起点,而非终点。
Q7: 长表格式和宽表格式有什么区别?
A: - 宽表格式:推荐。一个患者一行,每列是一个时间点,可以生成完整的Table 1 - 长表格式:一个患者多行,每行是一次测量,无法生成Table 1(因为人口学变量重复) 如果您有原始数据的控制权,建议整理成宽表格式。
Q8: 为什么边际均值和原始均值不一样?
A: 边际均值是模型调整后的估计,考虑了: - 个体间的随机效应 - 数据的相关结构 - 缺失值的影响 在数据不平衡或有缺失时,边际均值更准确地反映总体真实水平。原始均值只是简单的算术平均,未考虑上述因素。
Q9: 我能同时分析多个结局变量吗?
A: 本模块一次只能分析一个结局变量(单变量分析)。如果您有多个结局变量(如收缩压、舒张压、心率),需要分别运行模块。每个结局变量生成一套完整的分析结果。
Q10: 软件提示”模型不收敛”怎么办?
A: 这通常发生在LMM中。可能原因: - 样本量太小 - 时间点太多相对于样本量 - 数据变异性太大 解决方法: - 尝试更换统计方法(如改用MMRM或RM-ANOVA) - 检查数据是否有极端异常值 - 减少随机效应的复杂度(软件会自动尝试)
如果仍无法解决,请联系技术支持。
4.2.12 结果报告要点
在论文中报告单臂多时间点重复测量分析时,应包括:
1. 描述性统计(整体分析): - 各时间点的样本量、均值、标准差/标准误 - 趋势图展示变化轨迹 - 示例:“收缩压从基线的148.5±12.3 mmHg逐渐下降至第24周的135.2±10.8 mmHg(图1)。”
2. 主要终点分析: - 基线和主要终点的边际均值及95%CI - 变化值及95%CI - P值和统计方法 - 示例:“经MMRM分析,收缩压从基线(EMM: 148.3, 95%CI: 144.5-152.1)到第12周(EMM: 136.7, 95%CI: 132.9-140.5)显著下降,变化值为-11.6 mmHg (95%CI: -14.2 to -9.0, P<0.001)。”
3. 次要终点分析(如果做了): - 各比较对的变化值、95%CI、P值 - 注明是否进行多重比较校正及方法 - 示例:“所有随访时点与基线的比较均显示显著下降(Dunnett校正后,均P<0.01),其中第24周降幅最大(-13.2 mmHg, 95%CI: -16.1 to -10.3)。”
4. 统计方法部分: - 明确说明使用的统计方法(MMRM/RM-ANOVA/LMM) - 描述性统计的计算方法 - 主要终点和次要终点的定义 - 多重比较校正方法(如果有) - 显著性水平(通常P<0.05) - 使用的软件包
报告示例(完整段落):
统计分析
描述性统计采用均值±标准误(SE)表示各时间点的收缩压水平。主要终点定义为基线到第12周的收缩压变化,采用混合模型重复测量(MMRM)分析,模型中时间点作为固定效应,受试者作为随机效应,协方差结构采用非结构化矩阵。通过估计边际均值(Estimated Marginal Means, EMMs)及其95%置信区间(CI)评估各时间点的收缩压水平,并计算变化值及其95%CI。次要终点为所有后续时间点(第4周、第8周、第24周)与基线的两两比较,P值采用Dunnett法校正多重比较。双侧检验,P<0.05认为有统计学意义。所有分析使用R软件(版本4.2.2),MMRM分析使用mmrm包,边际均值估计使用emmeans包。结果
共纳入55例高血压患者,基线收缩压为148.5±12.3 mmHg。图1显示了收缩压随时间的变化趋势,呈持续下降模式。表2展示了各时间点的描述性统计:基线(n=55, mean=148.5, SE=1.7)、第4周(n=53, mean=142.1, SE=1.6)、第8周(n=51, mean=138.3, SE=1.5)、第12周(n=50, mean=136.7, SE=1.6)、第24周(n=48, mean=135.2, SE=1.8)。MMRM分析显示,收缩压从基线(EMM: 148.3, 95%CI: 144.5-152.1)到第12周(EMM: 136.7, 95%CI: 132.9-140.5)显著下降,变化值为-11.6 mmHg (95%CI: -14.2 to -9.0, P<0.001)(表3,图2)。次要终点分析表明,所有随访时点与基线的比较均显著(Dunnett校正后):第4周变化-6.4 mmHg (P<0.001),第8周变化-10.2 mmHg (P<0.001),第24周变化-13.2 mmHg (P<0.001)(表4,图3)。
4.2.13 进一步学习资源
如果您想深入了解重复测量分析的理论和应用,推荐以下资源:
经典教材: 1. Fitzmaurice GM, Laird NM, Ware JH. Applied Longitudinal Analysis (2nd ed). Wiley, 2011. - 纵向数据分析的权威教材,全面覆盖MMRM和LMM 2. Verbeke G, Molenberghs G. Linear Mixed Models for Longitudinal Data. Springer, 2000. - 混合模型理论的经典著作 3. Pinheiro JC, Bates DM. Mixed-Effects Models in S and S-PLUS. Springer, 2000. - 实用性强,含大量R代码示例
方法学论文: 1. Mallinckrodt CH, et al. Recommendations for the primary analysis of continuous endpoints in longitudinal clinical trials. Drug Information Journal, 2008, 42(4):303-319. - MMRM方法在临床试验中的应用指南 2. Molenberghs G, et al. Analyzing incomplete longitudinal clinical trial data. Biostatistics, 2004, 5(3):445-464. - 缺失数据处理方法综述
在线资源: - emmeans包文档:https://cran.r-project.org/web/packages/emmeans/vignettes/ - mmrm包文档:https://openpharma.github.io/mmrm/ - lmerTest包文档:https://cran.r-project.org/web/packages/lmerTest/
统计咨询: 如果您在分析过程中遇到复杂的统计问题,建议咨询专业的生物统计学家。
4.3 单臂疗效比较(结局为二分类资料,前后两次自身对照,如:是否达标/是否缓解等)
功能: 本工具用于单臂(单组)研究设计中,对同一组受试者在治疗前后两个时间点的二分类结局指标进行比较分析,支持McNemar检验、描述性统计、亚组分析,并自动生成出版级别的表格和图形。特别强调: 本模块支持一键生成中英文论文初稿(包括摘要、引言、方法、结果、讨论和参考文献),基于您的分析结果和研究信息,AI自动撰写完整稿件,便于快速起草SCI论文。
结局类型: 疗效结局为二分类变量,如达标/未达标、缓解/未缓解、有效/无效等。
研究设计: 单臂前后测量设计(pre-post design),即对同一组受试者在基线(治疗前)和治疗后测量同一二分类结局指标。没有对照组,通过前后变化评估疗效。适用于前瞻性或回顾性研究。
主要特点:
自动采用McNemar配对卡方检验,考虑配对数据的相关性。
支持可选的基线特征表(Table 1),用于描述研究人群。
支持亚组(分层)分析,探索不同子群(如年龄组、性别)的疗效差异。
一键生成出版级别表格(包括统计表、四格表)和图形(前后对比柱状图、亚组图)。
用户界面友好,避免复杂统计术语;全程指导,帮助用户理解单臂设计和McNemar检验的核心概念。
自动生成统计方法注解和Word报告,符合CONSORT报告规范。
一键查看和下载分析的 R 源代码,避免黑箱化,可溯源和复用。
论文生成功能: 基于分析结果,AI智能生成中英文论文初稿,包括Pubmed文献检索的背景和讨论,支持自定义研究信息(如人群、干预、终点),生成的稿件可直接修改投稿。
在分析过程中,逐步讲解统计知识,使用户逐步掌握临床研究设计和分析理念。
一键自动生成以下图表示例:

(Table 1: 基线特征表,可选)
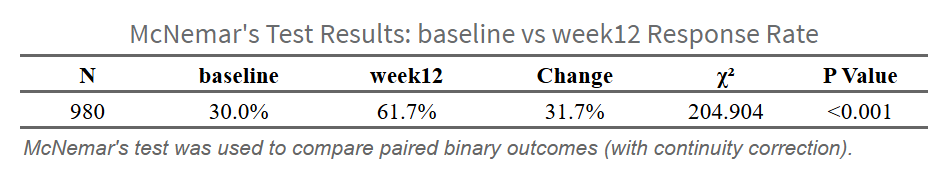
(McNemar检验结果表)

(配对四格表)
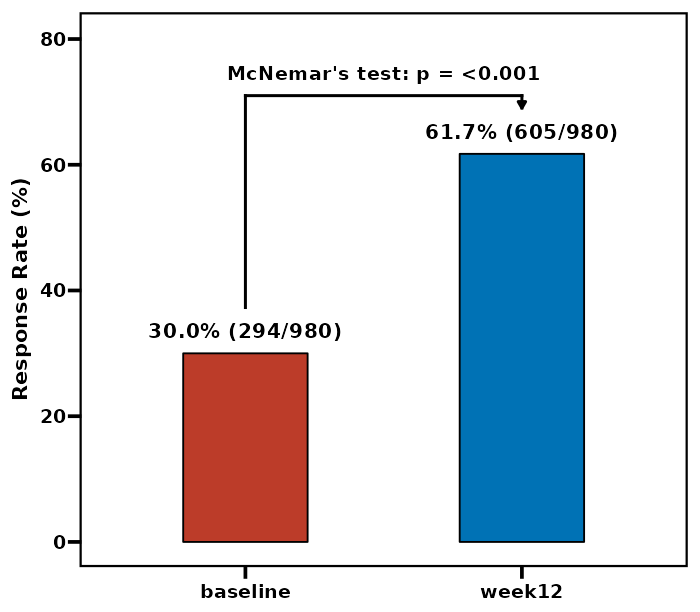
(前后对比柱状图)

(亚组分析表)
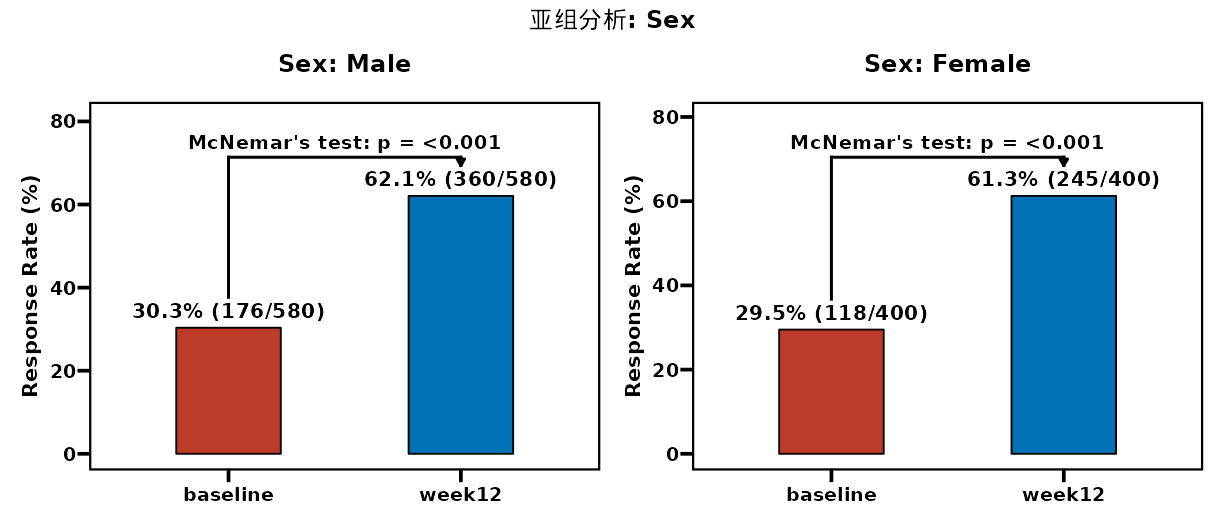
(亚组前后对比图)
4.3.1 基础知识
4.3.1.1 设计概述
单臂前后对照研究(single-arm pre-post study)是一种特殊的临床研究设计,特点如下:
- 无对照组:仅包含一组受试者,患者自身作为对照
- 配对测量:在干预前后对同一患者进行两次测量
- 二分类结局:结局变量为”是/否”、“达标/未达标”等二分类指标
- McNemar检验:专门用于分析配对二分类数据的统计方法
4.3.1.2 适用场景
- 初步探索性研究:评估新疗法的初步疗效和安全性
- 罕见病研究:难以招募足够的对照组患者
- 伦理限制:不设对照组符合伦理(如已有明确有效的治疗)
- 自身对照:控制个体差异,提高统计效能
4.3.3 结果报告要点
研究结果应报告:
- 描述性统计:基线和终点时的达标率
- 变化情况:改善例数、恶化例数、保持不变例数
- McNemar检验结果:χ²值、P值
- 效应量:改善率与恶化率的差异及95%CI
- 临床意义:统计学显著性与临床意义的讨论
报告示例: > 在55例患者中,治疗前血红蛋白达标率为54.5%(30/55),治疗后达标率为72.7%(40/55)。McNemar检验显示,治疗后达标率显著高于治疗前(χ² = 6.4, P = 0.011)。15例患者由未达标转为达标(改善率60.0%),5例由达标转为未达标(恶化率16.7%),净改善率为43.3%(95%CI: 15.2%-71.4%)。
4.3.4 McNemar检验简介
McNemar检验(McNemar’s test)是一种配对卡方检验,用于分析同一组受试者在两个时间点的二分类结局变化。它只关注“变化”的配对(从无效到有效,或有效到无效),忽略不变的配对。
前提假设(深入浅出):
- 配对性: 数据必须是同一患者的两次测量(如ID=1的基线和随访)。
- 二分类: 结局只有两种(如“是/否”),不能是多分类或连续变量。
- 独立性: 不同患者之间独立(一个患者的变化不影响他人)。
- 样本量: 变化配对数(b + c ≥ 25)足够大,否则用精确检验(本工具自动处理)。
统计原理(简单讲解):
构建2×2配对四格表:
| 治疗后:无效 | 治疗后:有效 | |
|---|---|---|
| 治疗前:无效 | a (不变) | b (改善) |
| 治疗前:有效 | c (恶化) | d (不变) |
- 只用b和c计算:χ² = (b - c)² / (b + c)。
- 原假设(H₀):前后无差异(b ≈ c)。
- p < 0.05:拒绝H₀,表明前后有显著变化(通常改善:b > c)。
结果解读:
- 事件发生率: 前后各时间点的百分比(如基线20%,治疗后60%)。
- 95% CI: 发生率的置信区间(使用Wilson方法,更可靠)。
- p值: <0.05表示变化显著,但需结合临床意义。
缺失数据处理:
本工具自动剔除前后均有值的完整配对。缺失多时,建议返回数据准备模块用多重填补(MI)。
亚组分析:
将数据按特征分层(如男性/女性),每个层内单独做McNemar检验。探索疗效异质性,但需注意多重比较(事后分析用Bonferroni校正:α/亚组数)。
4.3.5 准备数据
首先下载样例数据:
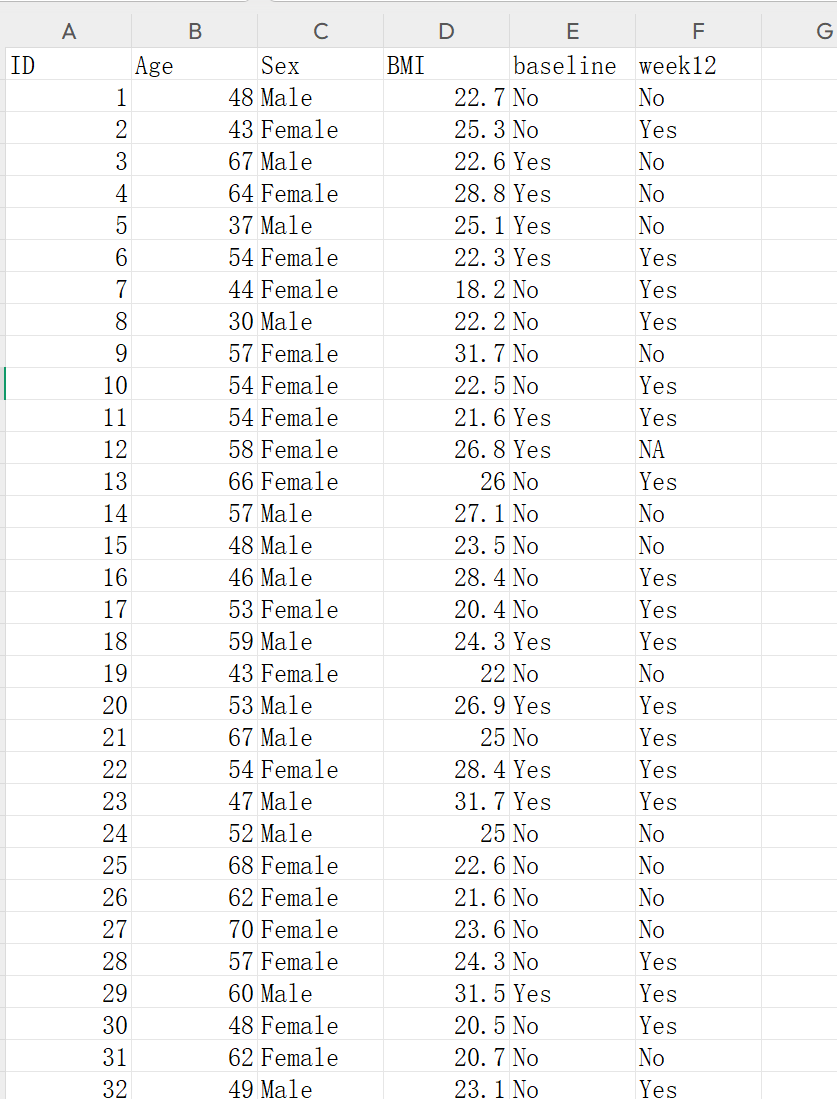
数据格式要求(宽表):
- 每行一患者。
- 基线结局列: 二分类(如baseline: No/Yes)。
- 治疗后结局列: 二分类(如week12: No/Yes)。两个列的水平必须一致(否则分析失败)。
- 基线特征列(可选): 如Age、Sex、BMI,用于Table 1或亚组分析。
- 缺失值: 用NA表示,本工具自动处理。
在样例基础上修改您的Excel数据,保存为csv上传。
常见问题:
- 如果水平不一致(如基线用0/1,随访用No/Yes),返回“重编码”模块统一。
- 确保结局是factor类型(返回“定义字段”模块设置)。
4.3.8 疗效比较分析
4.3.8.1 第一部分:基线人口学和临床特征表(Table 1,可选)
目的: 描述研究人群特征(年龄、性别等),用于论文方法学部分。跳过不影响后续。
操作步骤:
- 在“选择基线变量”中,选择人口学/临床特征(如Age、Sex、BMI)。勿选结局变量(结局在第二部分)。
- 点击“生成/更新Table 1”。
- 结果:显示Table 1(描述性统计:均值/SD、计数/%)。
- 统计知识讲解:
- 连续变量: 如Age,用均值±SD(正态)或中位数(IQR,非正态)。
- 分类变量: 如Sex,用计数(%)。
- 单臂设计无组间比较,故无需p值。
4.3.8.2 第二部分:疗效比较分析
- 整体分析(必做):
选择变量:
基线变量:治疗前结局(如baseline)。
随访变量:治疗后结局(如week12)。
Response水平:选“事件”水平(如Yes代表达标)。
标签设置: 自定义基线/随访/结局标签(如“基线”、“治疗后”、“达标率”)。
数字格式: 调整百分比/p值小数位。
表格设置: 选连续性校正(样本小时推荐);显示显著标记(* for p<0.05)。
点击“生成/更新整体分析结果”。
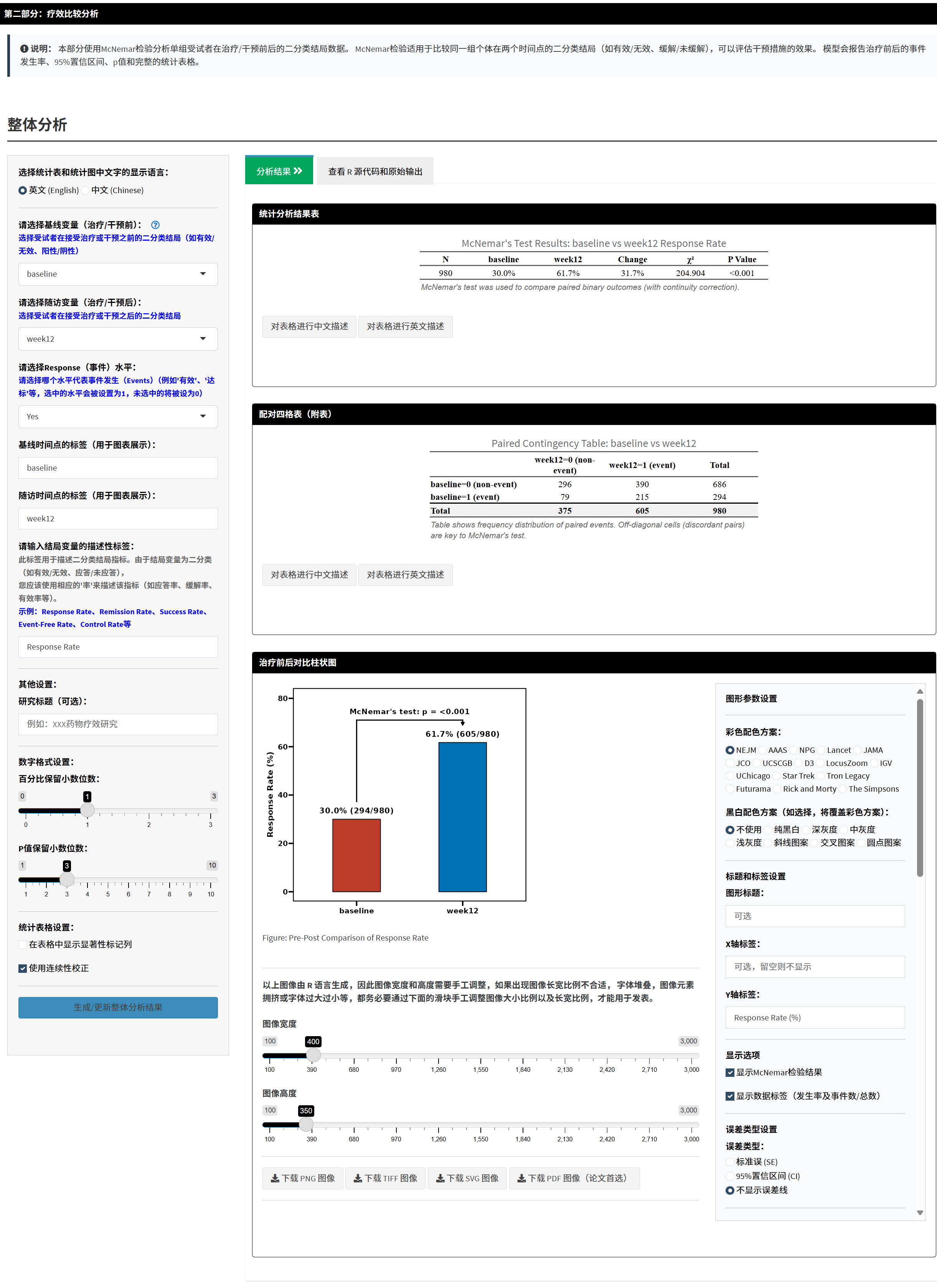
结果:
统计表: 前后发生率、95%CI、p值。
配对四格表: 显示变化频数(a/b/c/d)。
柱状图: 前后对比,可调整配色、误差线、字体等参数实时预览。
- 统计知识讲解:
- 连续性校正: 当变化配对<25时,加0.5避免χ²过大,提高准确性。
- 显著标记: p<0.05用*表示,便于阅读。
- 图形参数: 误差线可选SE/CI;黑白方案用于打印;Y轴自定义避免变形。
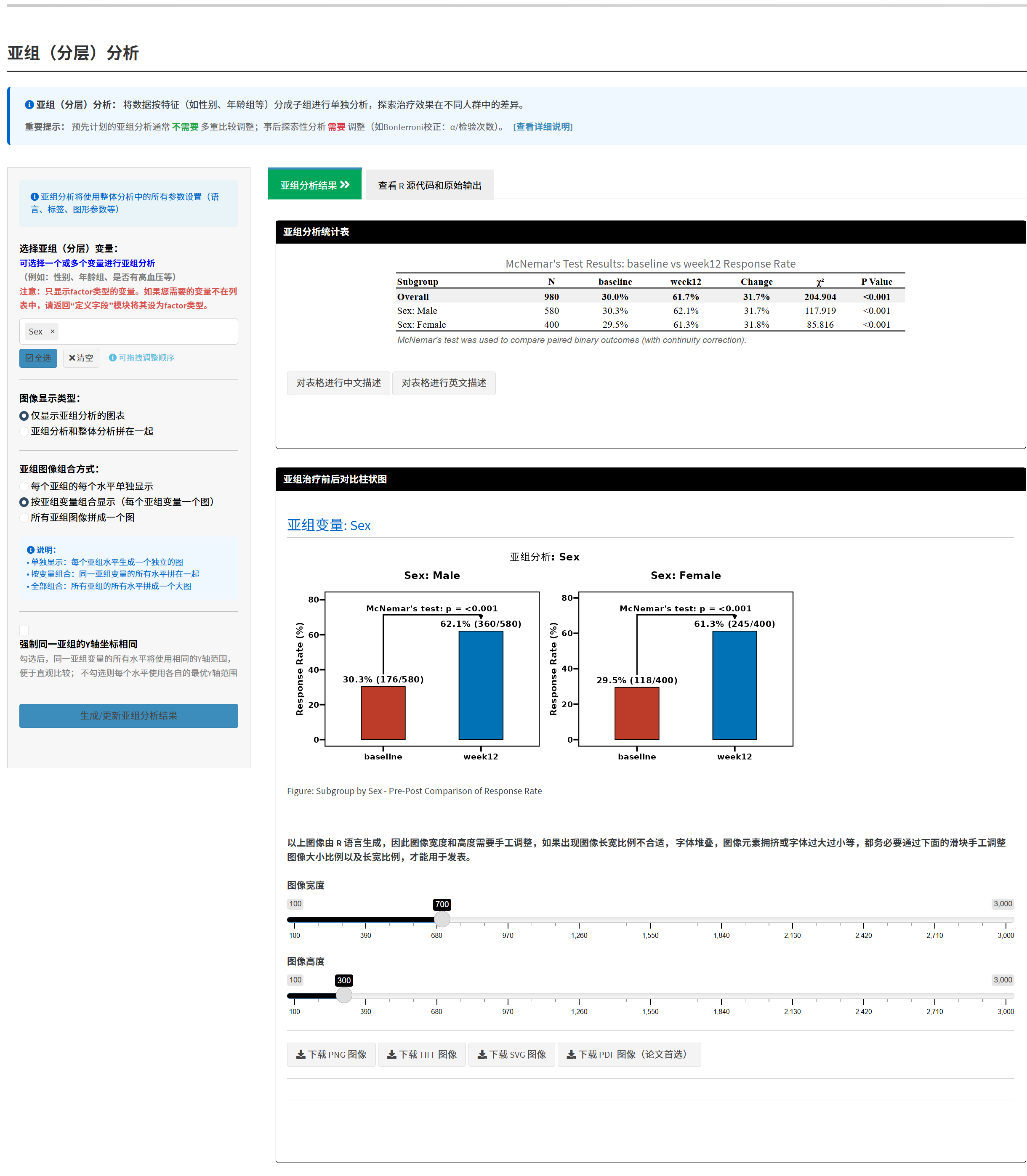
- 亚组分析(可选):
完成整体分析后显示。
选亚组变量(如Sex、Age_group)。
选图像类型(仅亚组/与整体组合)。
选组合方式(单独/按变量/全部拼图)。
勾选“统一Y轴”便于比较。
点击“生成/更新亚组分析结果”。
结果: 亚组统计表(每个层的前后比较);多张图形(根据模式)。
- 统计知识讲解:
- 亚组分析目的: 检查疗效一致性(如男性改善大?)。
- 多重比较: 多个亚组时,p值易假阳性。预计划分析无需调整;事后用Bonferroni(p<0.05/亚组数)。
- 统一Y轴: 确保比例一致,避免视觉误导。
4.3.10 下载Word文件和论文初稿
- 操作步骤:
- 点击“下载Word文件”tab。
- 论文初稿生成(强调功能): 填写研究信息(人群、干预、类型、终点),确认数据准备,点击“下载英文论文”或“下载中文论文”。AI将基于分析结果生成完整初稿(5-10分钟),包括Pubmed检索的背景/讨论。
- 也支持下载纯分析报告(表格+图形)。
- 内容:
- Table 1(若做)。
- McNemar表、四格表、柱状图。
- 亚组表和图(若做)。
- 论文初稿: 中英文版本,结构完整(标题、摘要、引言、方法、结果、讨论、参考文献)。底注自动生成统计方法。
- 强调: 生成的初稿可直接作为SCI投稿基础,AI智能整合您的结果和文献。
提示: 用Microsoft Word打开(WPS可能乱码)。论文初稿需人工审阅/修改。

4.4 单臂疗效分析(结局为生存资料,如OS/PFS/DFS等)
单组生存分析是一种统计学方法,用于研究生存数据中事件发生的时间和频率。它通常用于描述事件发生的速率、估计生存函数,主要关注单一样本中生存时间的描述性分析。在医学研究领域,单组生存分析常用于研究患者生存期和事件发生的概率,例如研究某种疾病患者的生存期。
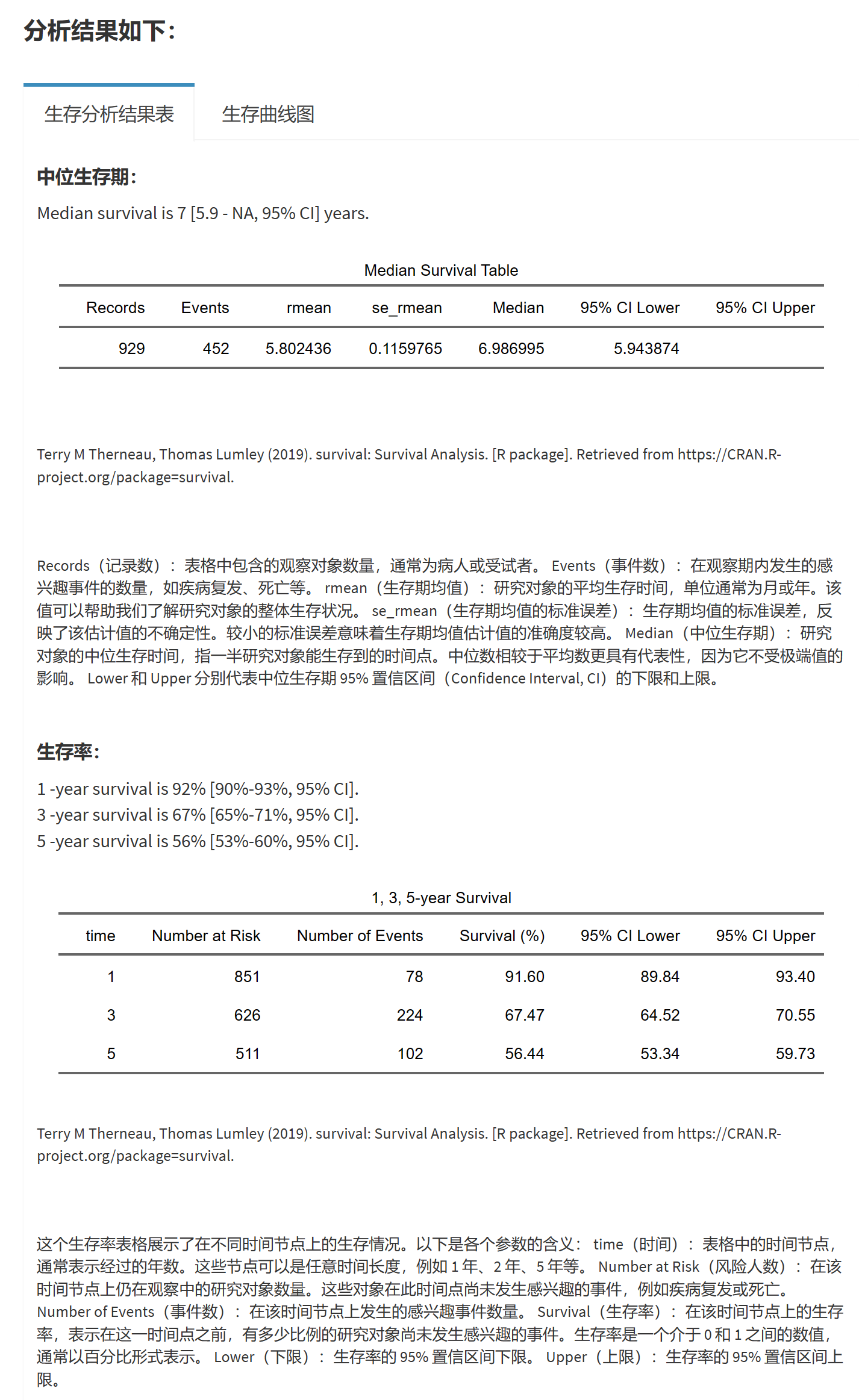
以下是一个医学研究中应用单组生存分析的例子:
假设我们要研究某种癌症患者的生存期(时间)。我们可以收集患者的生存数据,包括每个患者的随访时间、是否发生了感兴趣的事件(如死亡)等。利用单组生存分析,我们可以估计患者的生存率及生存期。
在单组生存分析中,Kaplan-Meier(KM)法是一种广泛使用的非参数方法,用于估计生存数据的生存函数。KM法考虑了随访时间的不同长度和不同时间点的失访情况,提供了对生存率和生存期的准确估计。
软件中提供了以下功能:
设置时间变量的单位,如天、周、月、年:方便对生存时间进行度量。
选择统计图表中的时间单位,系统会自动转换:提供不同时间单位的图表展示。
计算平均生存期,中位生存期及其95% CI:提供生存期的估计和置信区间。
计算自定义的各时间点的生存率及其95% CI:可以根据研究需求,查询指定时间点的生存率。
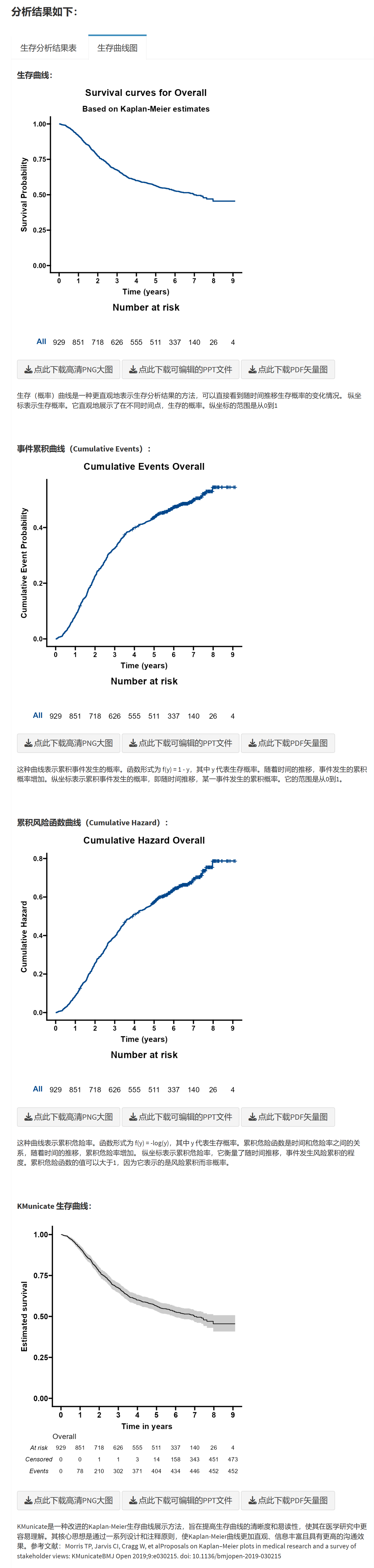
支持生存曲线(Survival Plot):展示随时间推移的生存率变化。
累积事件曲线(Cumulative Events):展示随时间推移的累积事件发生数。
累积风险曲线(Cumulative Hazard):展示随时间推移的累积风险。
KMunicate 曲线(KMunicate-Style Plot):一种直观的方式来展示生存曲线和生存时间的分布。
通过软件的单组生存分析功能,研究者可以更有效地描述和分析生存数据,为临床和公共卫生决策提供有力的依据。
4.4.1 准备数据
首先务必按照下面的格式准备数据(网站上可下载,下载后在此基础上修改):
打开如下图:
在使用本软件进行单组生存分析之前,您需要准备包含两个关键变量的数据:时间变量(time)和生存状态变量(status)。这两个变量的详细说明如下:
- 生存状态变量(status):表示患者在研究结束时的生存状态。在本工具中,您可以为status设置任意标签,但为了简单明了,我们建议使用数字 0 或 1。具体而言:
0 代表未观察到感兴趣事件发生(例如患者尚未死亡或失访)。
1 代表已观察到感兴趣事件发生(例如患者死亡,并记录了死亡日期)。 在本软件中,您可以设定哪个标签代表发生事件,确保标签和实际含义相符。
- 时间变量(time):表示从研究开始日期到观察结束日期的时间差。研究开始日期的定义根据您的研究目的而定,例如随机对照研究通常以随机分组日期为开始,而观察性研究可以选择首次诊断日期或首次治疗日期等。关于time变量,请注意以下事项:
当status为 1 时,观察结束日期为感兴趣事件发生(如死亡)的日期。
当status为 0 时,观察结束日期为最后一次确认患者生存的日期(如研究结束日或随后一次随访日)。
总之,time是一个数值型变量,表示患者从研究开始到观察结束所经历的时间。例如,若time为56,status为1,则表示患者从研究开始到死亡共生活了56天;若time为56,status为0,则表示患者从研究开始到最后一次随访共生活了56天。time的单位可以是天、月或年,本软件可以在分析时进行转换。
在准备数据时,请确保为每个患者填写非负整数的 time 和相应的status标签。time 和 status均不能为空,否则将无法进行分析。若 time 或 status 的数值不确定或缺失,建议不要将该患者纳入数据库。
为了便于理解,我们还是建议在举例时使用 0和 1这样简单的数字标签。当然,在实际操作中,您可以根据自己的需求为status设置合适的标签,比如 “死亡”, “生存或未知(失访)”等标签,然后在软件里把死亡设置为发生事件。只要确保在本软件中正确设定标签含义即可。这将有助于用户更加灵活地应对不同的研究需求,并且更容易地理解和操作数据。
4.4.3 单组患者生存分析
下一步就是生存分析啦:
选择代表时间的变量(如从开始到死亡的时间,或从开始到末次随访时间)。
确定数据中的时间变量每个单位代表的时间长度(天、周、月或年)。
选择代表患者最终状态的变量(只能有两个取值,例如1代表发生事件,0代表删失,如1-死亡,0-存活或未知)。
选择结局变量的水平,以表示发生事件(建模时,选中的水平会设定为1,剩下的水平会设定为0)。
选择后续统计图表中的时间单位(天、周、月或年)。
设置统计表选项:输入需要在统计表中展示的生存率,用英文半角逗号隔开。
设置统计图选项:勾选需要绘制的图表类型(生存曲线、累积事件曲线、累积风险曲线、KMunicate曲线等),并设定图像的宽度和高度。
设定坐标轴的范围:设定横坐标(时间)的上限,以决定曲线完整显示还是部分显示;设定横坐标(时间)的每格单位刻度值。
设置额外图像选项:在图像上显示95%置信区间条带、风险人数表(Risk table)以及删失(censored)数据标记。
点击”开始进行单组生存分析”按钮,程序将根据设置的选项进行分析并生成结果。
请注意,正确设置图像选项(如横坐标上限和最小刻度)有助于让生存曲线显示完整且清晰。

4.5 多臂疗效比较(结局为二分类资料,如:是否有效/ORR/DCR等)
功能:本工具可以对两组或两组以上的患者进行治疗效果评价统计分析。
结局类型:疗效结局为二分类变量,如有效、无效;缓解、无缓解等。
研究设计:研究类型可以是随机对照分组,也可以是非随机分组;可以是干预研究,也可以是非干预研究;可以是前瞻性研究,也可以是回顾性研究。
主要特点:
根据不同的研究设计类型,系统会自动采用适宜的统计学方法
可选倾向性评分匹配或多因素回归来调整治疗组间协变量的平衡
根据分组的多少(两组、两组以上),系统会自动采用适宜的统计学方法
根据CONSORT报告规范一分钟无脑生成统计表,达到新英格兰医学杂志的图表要求
用户不懂统计也能操作,全程避免使用艰涩的统计语言
自动生成统计方法注解
在整个分析过程中,潜移默化的教会用户,临床研究设计的理念和统计分析的理念,使用本工具完成一项研究之后,用户基本也成为了临床研究专家。
一键自动生成以下8个图表:
4.5.1 基础知识
当疗效评价的指标是二分类变量时,适用本工具。什么是二分类变量?
二分类结局变量:
二分类变量即为那些结局只有两种可能性的变量,如有效与否,心梗,心血管不良事件,死亡等,一般将发生事件的人数除以样本量总数得到的事件发生率作为结局考察。
如何评价疗效?
常见的二分类变量疗效结局评价指标包括:OR (Odds Ratio) 值、RR (Risk Ratio) 值、RD (Risk Difference) 值。
评价二分类变量结局疗效的统计方法有哪些?
常见的有卡方检验,Logistic回归,泊松回归等。
缺失数据处理
疗效指标为二分类变量时,对于结局变量,可以彻底剔除结局缺失的患者;也可以用多重填补(MI)法进行填充。
组间基线的平衡
如果是非随机对照研究,分组间的人口学和临床特征,可通过倾向性评分匹配、逆概率加权或者多因素分析等来调整。
4.5.2 准备数据
首先下载样例数据:
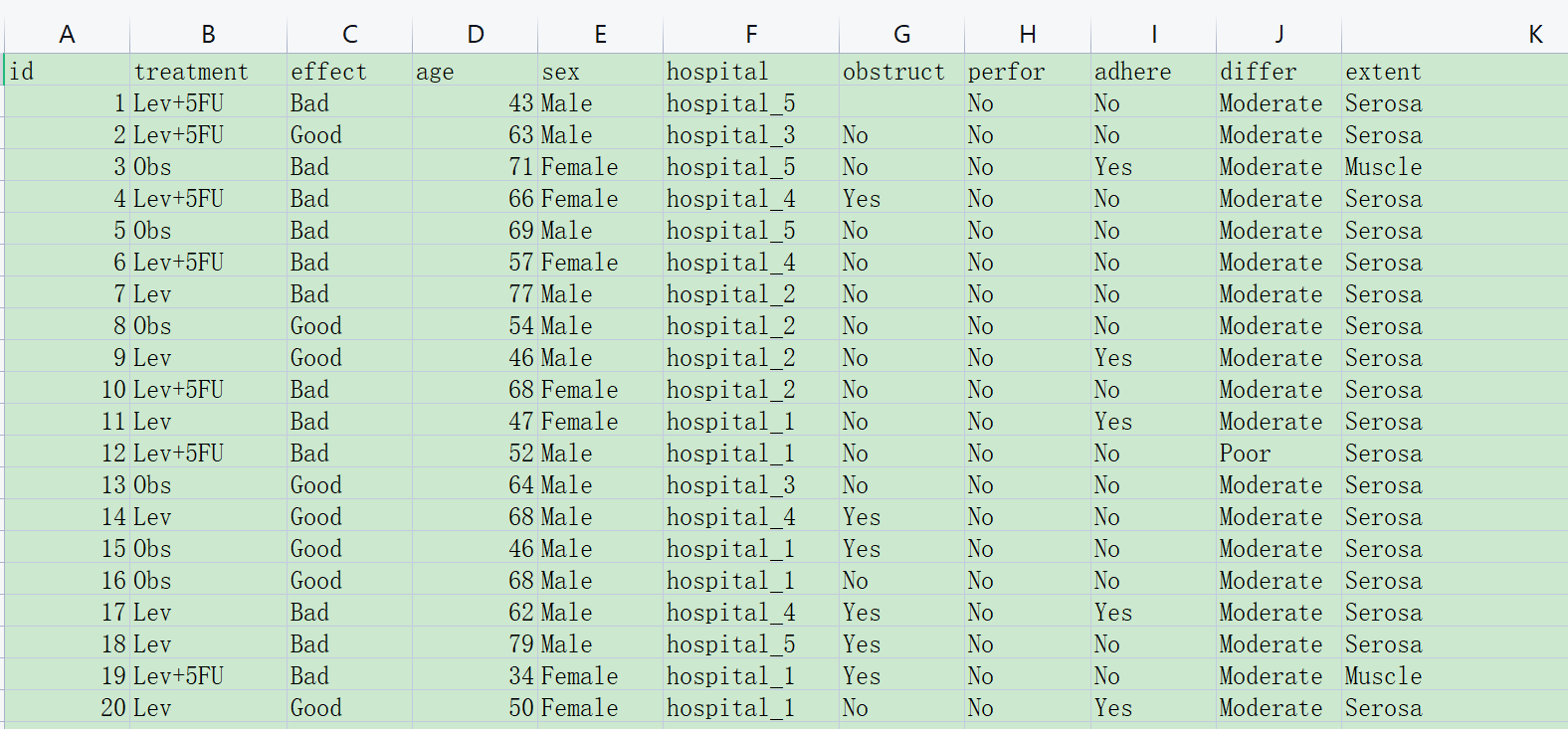
有三类变量:
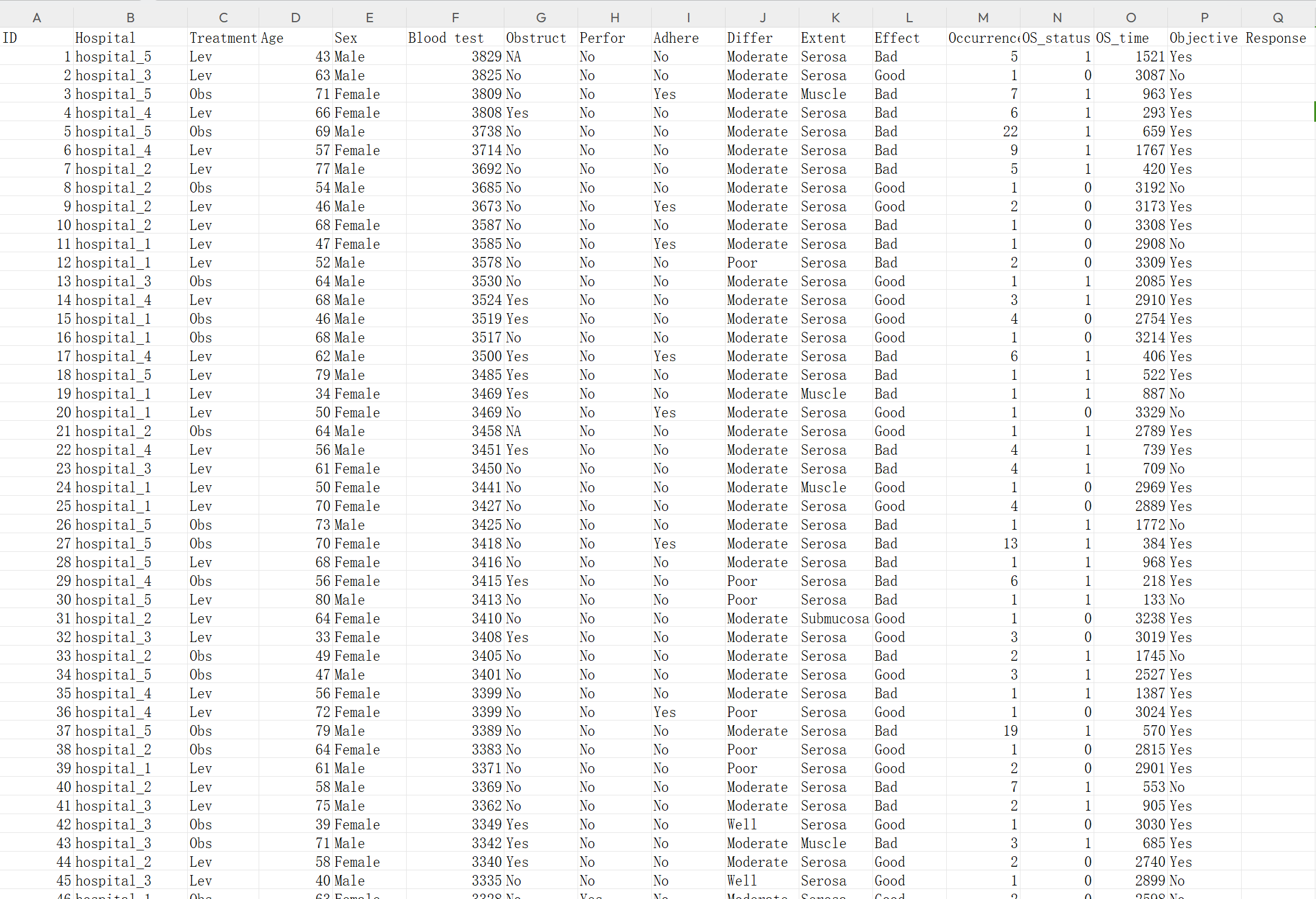
代表治疗分组的变量:例如上图中的treatment, 分成了Lev、Obs和Lev+5FU三个组
代表疗效评价的变量:例如上图中的effect,有疗效Good、Bad两种情况
基线人口学和临床特征:例如上图中的age、sex等等一系列指标,可用来调整组间平衡,也可用来做亚组分析
下载生成的样例数据,然后在样例数据的基础上修改成您自己的数据,就可以上传开始分析啦。
4.5.4 疗效比较分析
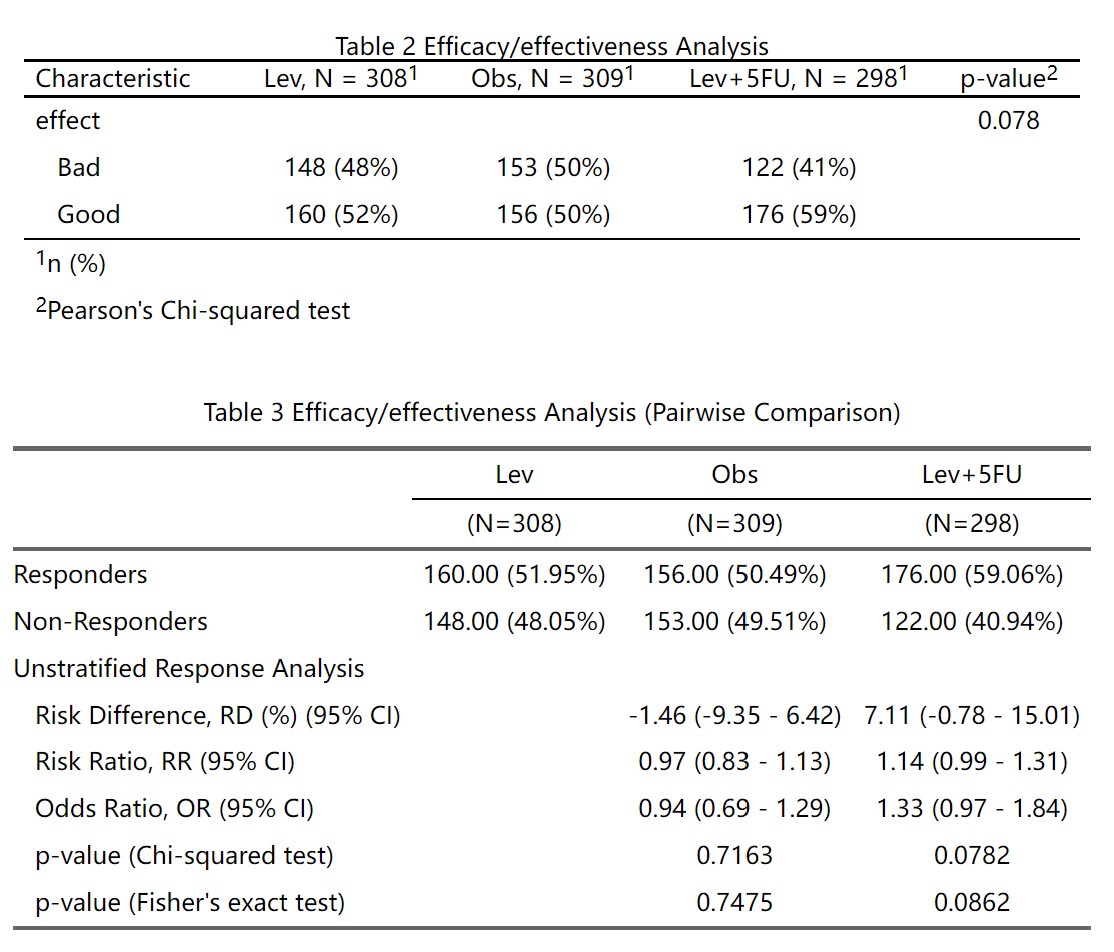
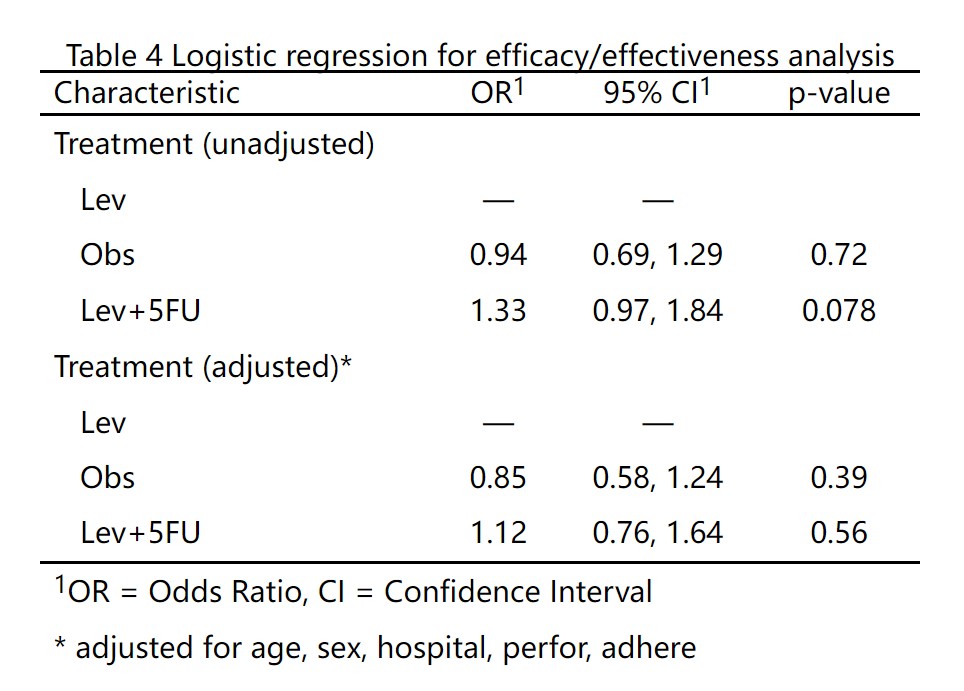
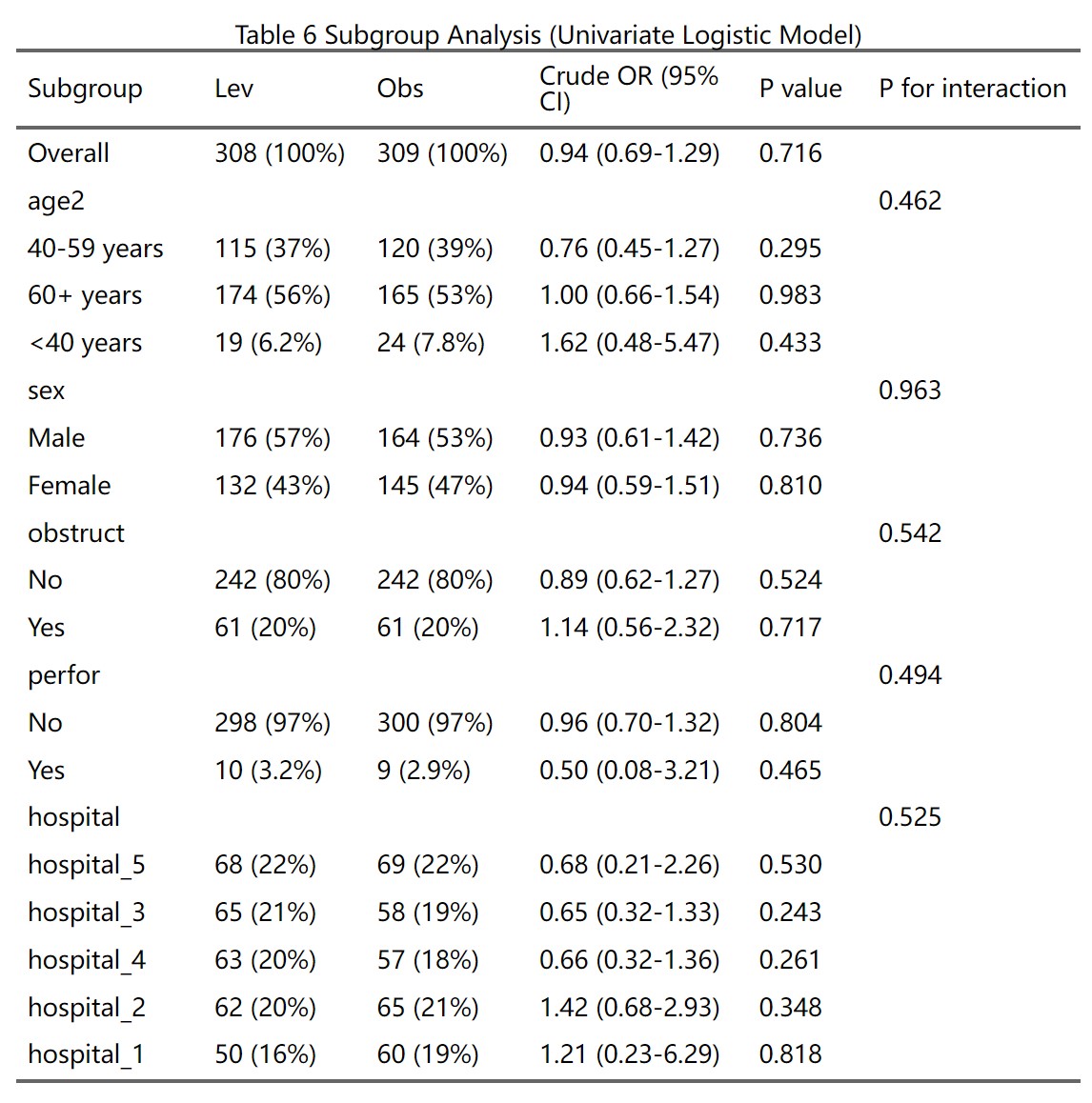
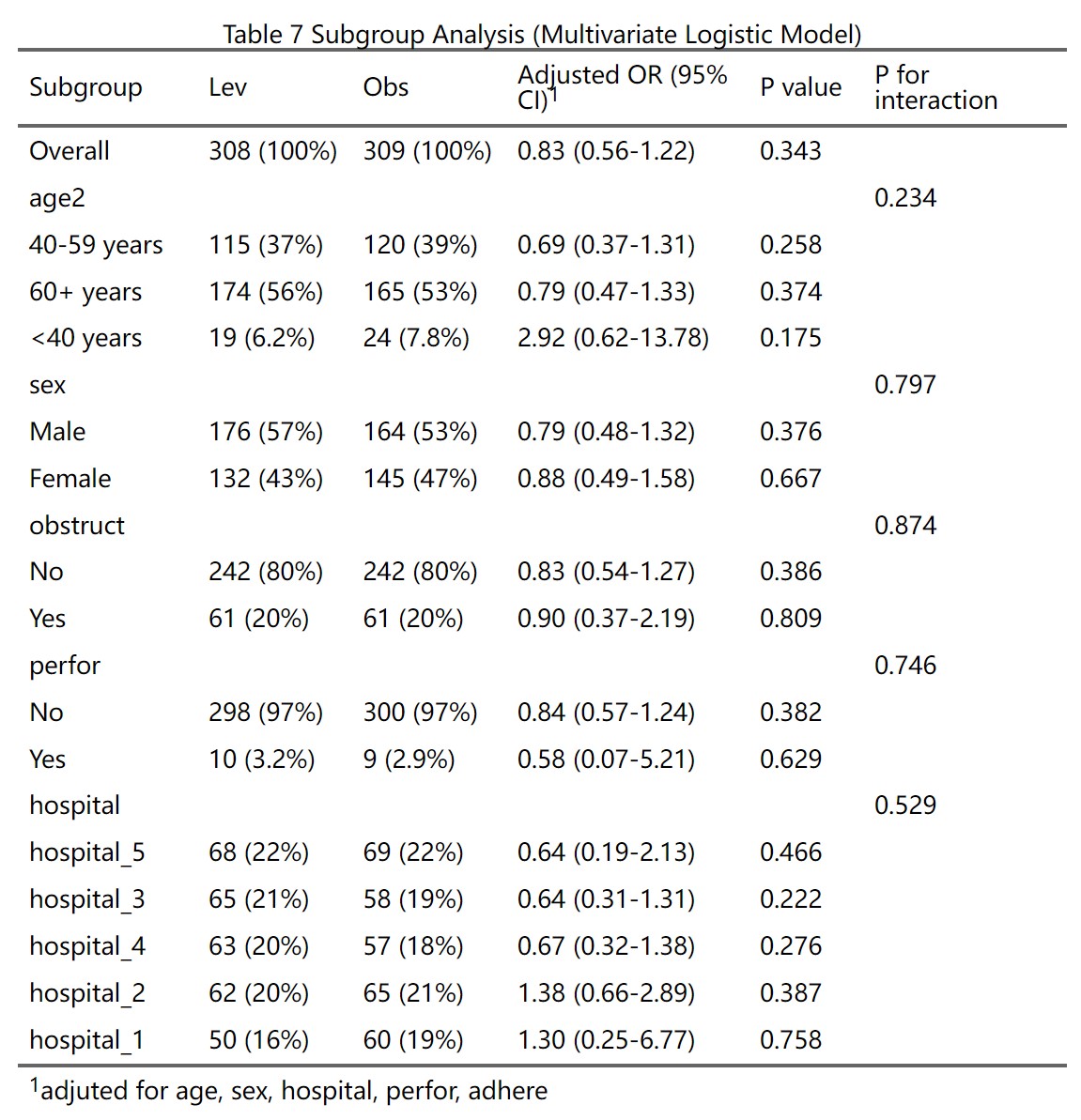
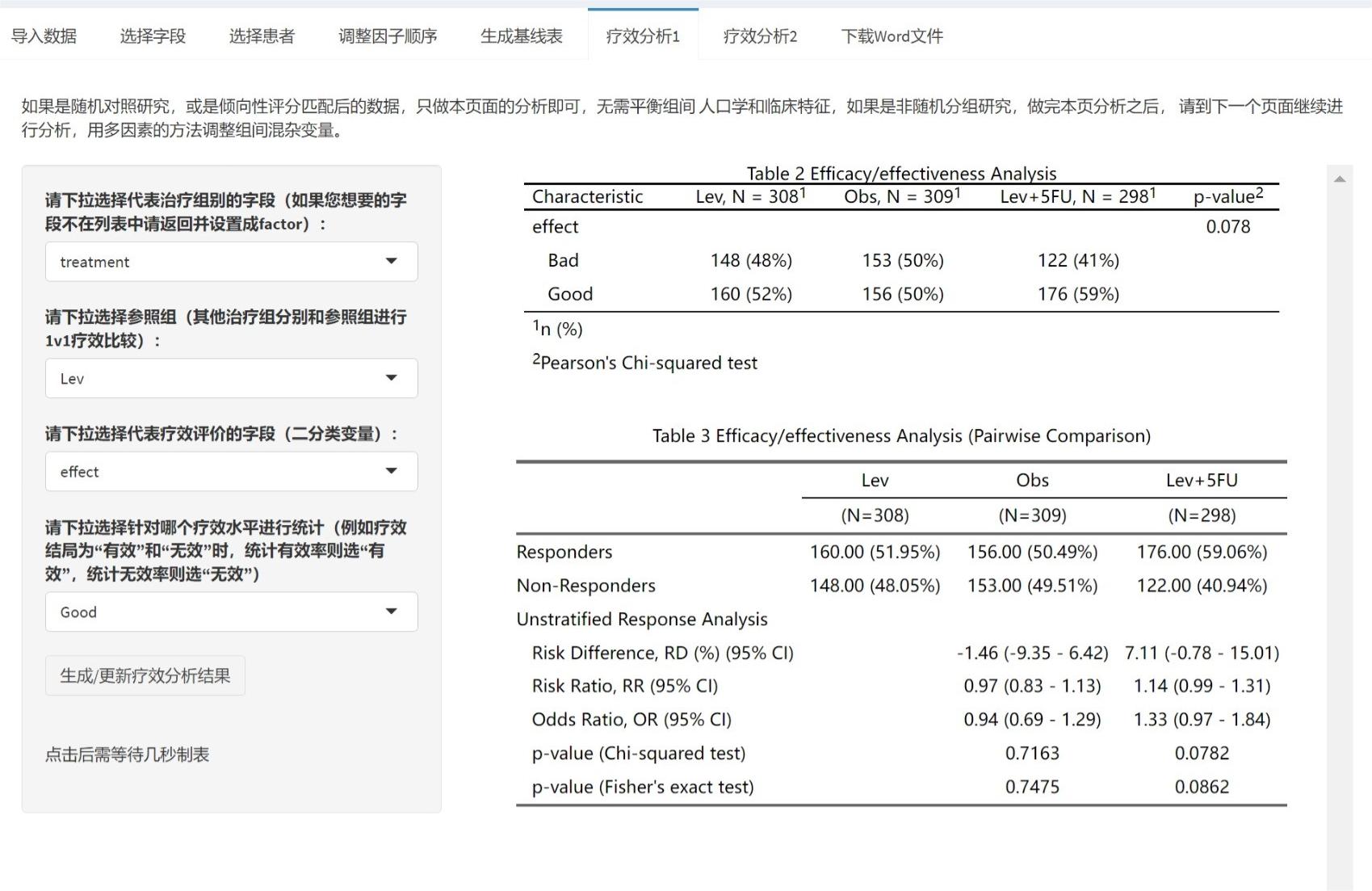
最后进行疗效比较分析,选择代表治疗组别的变量,如treatment,然后选择哪个组是参照组,其他组分别和参照组做两两比较。再选择疗效评价的字段,如effect,这个例子里有两个取值,Good和Bad。由于这里我们要统计效果好的率,所以勾选Good。
点击生成/更新疗效分析结果后得到两个表:
表2 是一般的卡方检验或确切概率检验,仅做参考,可以不放论文里。
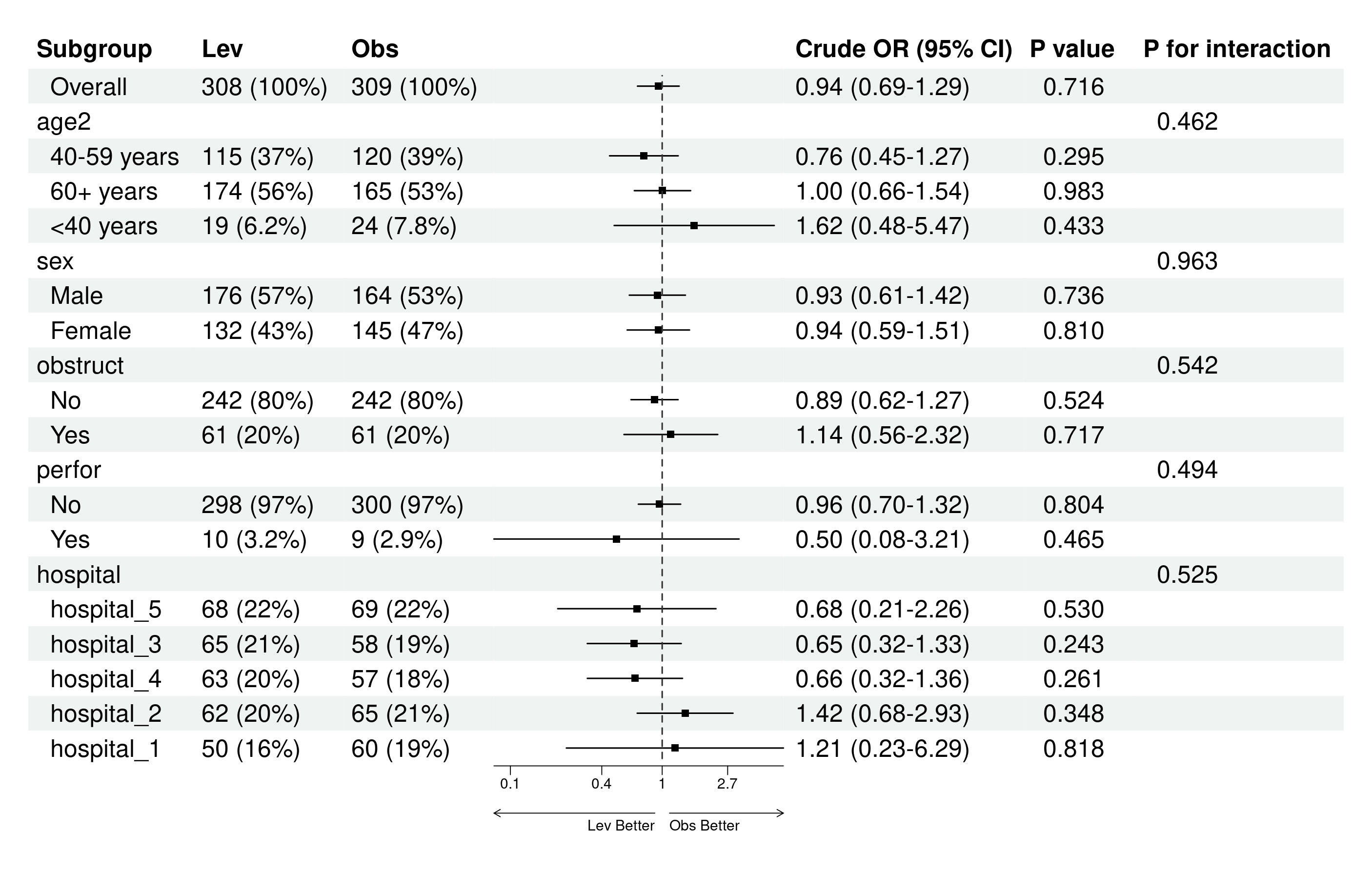
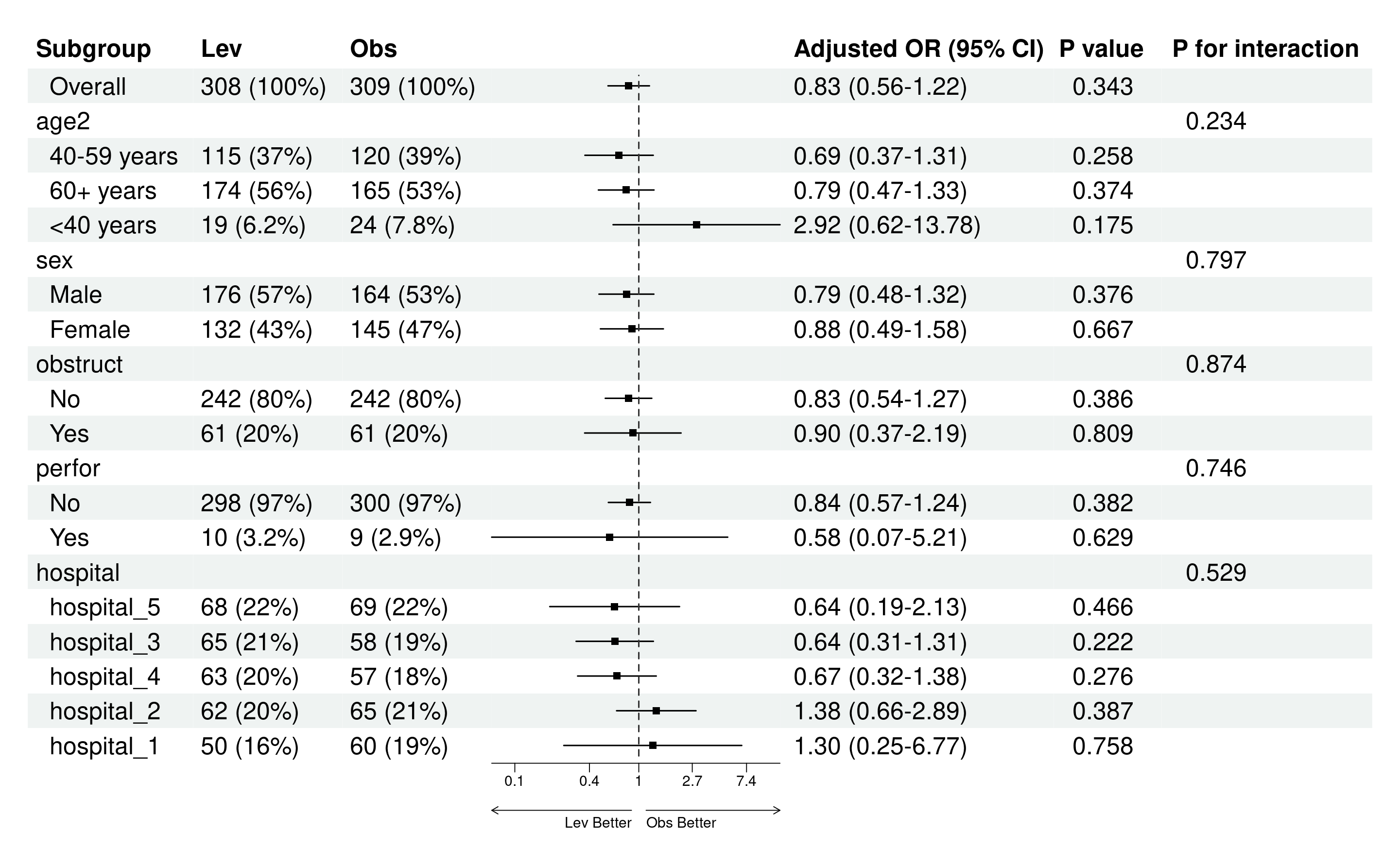
表3 是两两比较,以Lev为参照组,其他两组分别和它比,给出了RD、RR、OR值和可信区间。
如果分组是非随机的,或者是回顾性研究的话,还要平衡一下组间的基线协变量,进入下一页,疗效分析2:
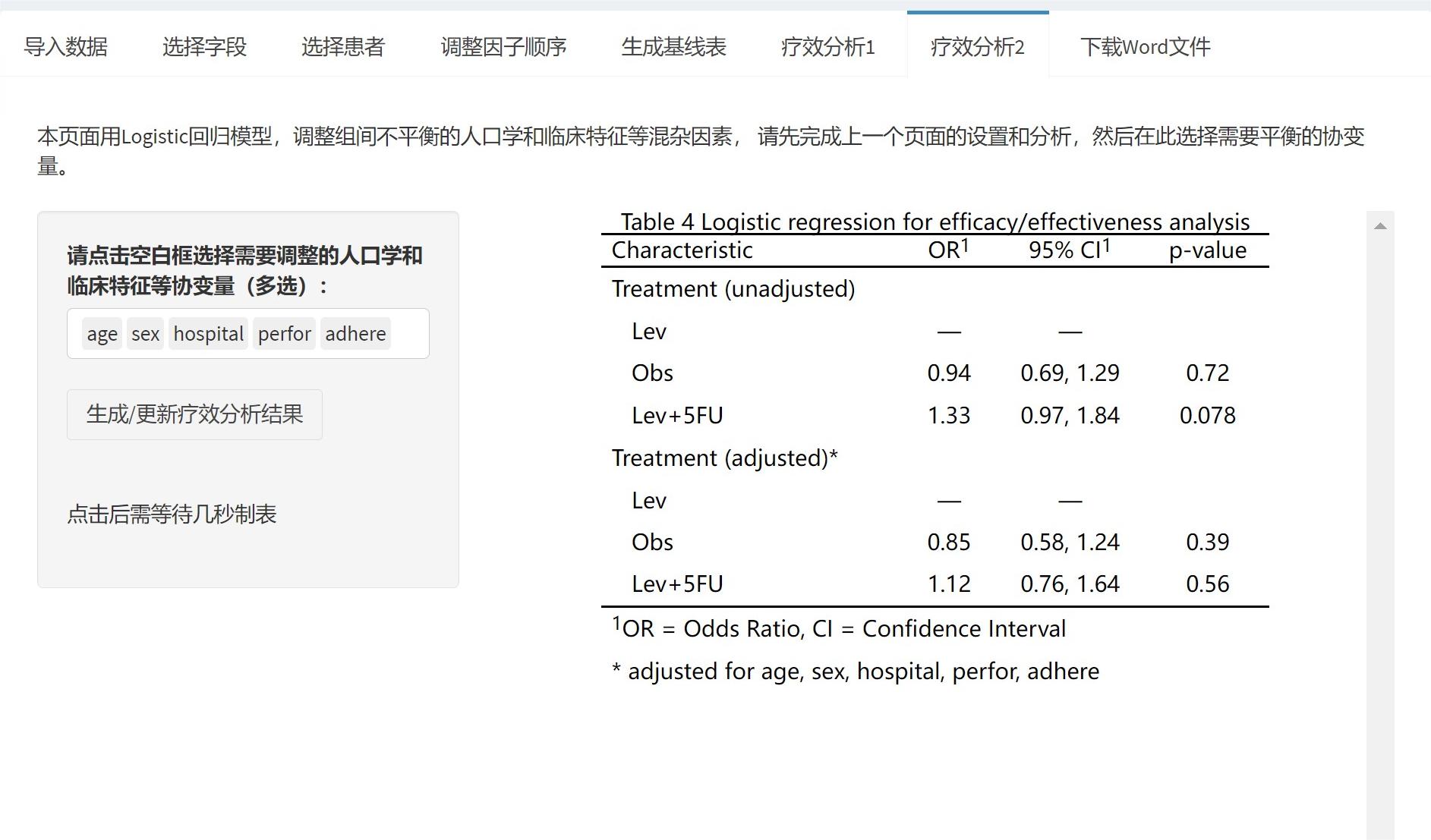
点击选择需要平衡的人口学和临床特征变量,点击按钮,就生成了表4,单因素和多因素Logistic回归。
当然,如果要调整的变量太多的话,还是建议先用本站的”倾向性评分匹配”工具,做完倾向性评分匹配后再把匹配后的数据上传上来做疗效分析。
4.6 多臂疗效比较(结局为连续性资料,如血液检测指标等)
功能:本工具可以对两组或两组以上的患者进行治疗效果评价统计分析。
结局类型:疗效结局为连续性变量。疗效结局如果为二分类或生存资料的,请使用本站另外的模块。
研究设计:研究类型可以是随机对照分组,也可以是非随机分组;可以是干预研究,也可以是非干预研究;可以是前瞻性研究,也可以是回顾性研究。
主要特点:
根据不同的研究设计类型,系统会自动采用适宜的统计学方法
支持治疗前后的差值,治疗组间的差值,以及双重差分(DID)来评价疗效
可选倾向性评分匹配或多因素回归来调整治疗组间协变量的平衡
根据分组的多少(两组、两组以上),系统会自动采用适宜的统计学方法
根据CONSORT报告规范一分钟无脑生成统计表,达到新英格兰医学杂志的图表要求
用户不懂统计也能操作,全程避免使用艰涩的统计语言
自动生成统计方法注解
在整个分析过程中,潜移默化的教会用户,临床研究设计的理念和统计分析的理念,使用本工具完成一项研究之后,用户基本也成为了临床研究专家。
一键自动生成以下4个图表:
4.6.1 基础知识
当疗效评价的指标是连续性变量时,适用本工具。什么是连续性变量?
连续性变量:值是连续数据,它可以在变量值所属区间内任意进行取值,如血糖值、血压值、血胆固醇水平、身高、智商等
基本理念
基线值 Baseline:在基线期测量的疗效指标。基线时间由您的研究设计决定,通常在治疗前。按照惯例,如果是随机对照研究,通常基线期在随机化分组日期附近;如果是非干预研究或回顾性研究,基线时间由研究设计决定。如研究开始时,测量基线空腹血糖水平。
终点值 Endpoint:在研究终点测量的疗效指标。研究终点由研究设计决定。如治疗24周后的空腹血糖水平。有些研究有主要研究终点,还有次要研究终点。比如除了血糖,还要分析糖化血红蛋白和其他指标。
终点和基线的差值 Change from baseline:是指治疗后规定的时间点,疗效指标的变化值。Change from baseline = Endpoint-Baseline 如治疗后24周的空腹血糖-基线空腹血糖。
终点相对基线变化的百分比 Percent change from baseline: 是指治疗后规定的时间点,疗效指标的变化的百分比值。 Percent change from baseline = (Endpoint-Baseline)/Baseline * 100% 如治疗24周后的空腹血糖相对于基线空腹血糖变化的百分比。
如何评价疗效?
疗效评价需要有治疗组和对照组。本工具适用两组或多组疗效评价。如果只有一个组的单臂研究,不适用本工具。
疗效评价主要采用双重差分(double difference) 的理念。
治疗组 Change from baseline = 治疗组 Endpoint - Baseline
对照组 Change from baseline = 对照组 Endpoint - Baseline
疗效比较指标 Effect = 治疗组 Change from baseline - 对照组 Change from baseline
这里需要准备四个关键数据,治疗组治疗前后的两个疗效测量,对照组治疗前后的两个疗效测量。
治疗组前后的差值,和对照组前后的差值,相减得到两组间的Difference。先算两组自身前后的差值,再算组间差值的差值,相减了两次,所以也被称为双重差分。
统计模型
如何进行统计分析呢?最常见的是ANCOVA模型,尽管前面进行了差值减法,但两组基线水平还是有些差异,因此要调整基线水平。模型为 Change from baseline ~ Treatment+Baseline+Other covariables
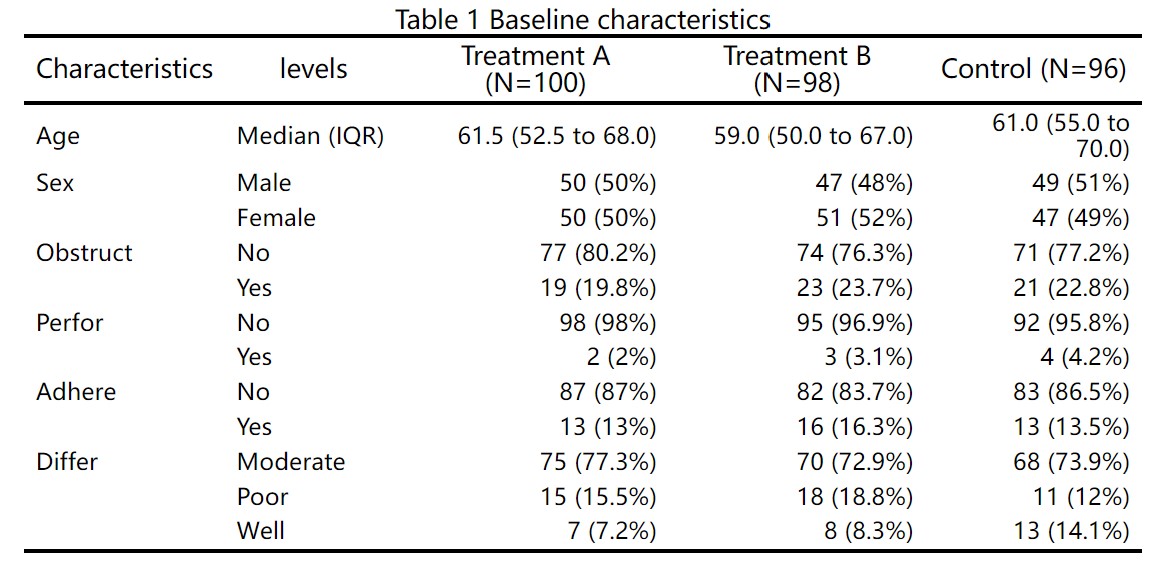
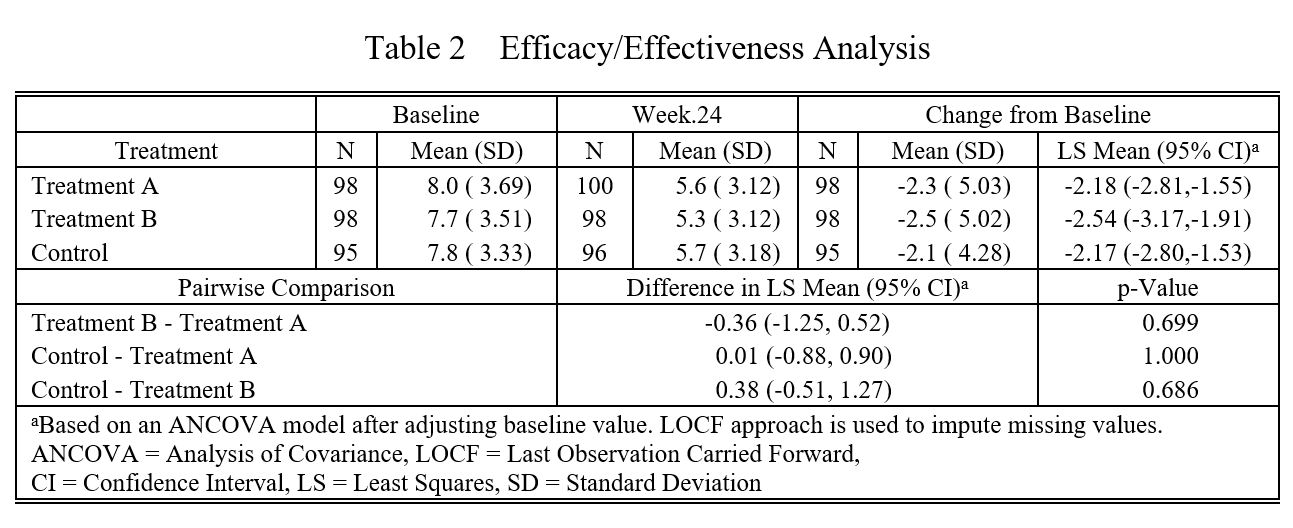
根据CONSORT指南,首选我们要在论文表格里描述每个组基线的mean (sd), 终点的mean (sd), Change from baseline 的 mean (sd),另外还需要描述 Change from baseline 调整了Baseline 之后的 LS mean 和 95% CI,第二步就是治疗组和对照组互相之间的 Difference in LS Mean (95% CI)。
此外,如果是随机对照试验,组间人口学或临床特征已经通过随机分组做了平衡,不需要再过多统计学处理。但如果是非随机研究,组间基线不平衡,还需要对人口学或临床特征进行统计学调整:
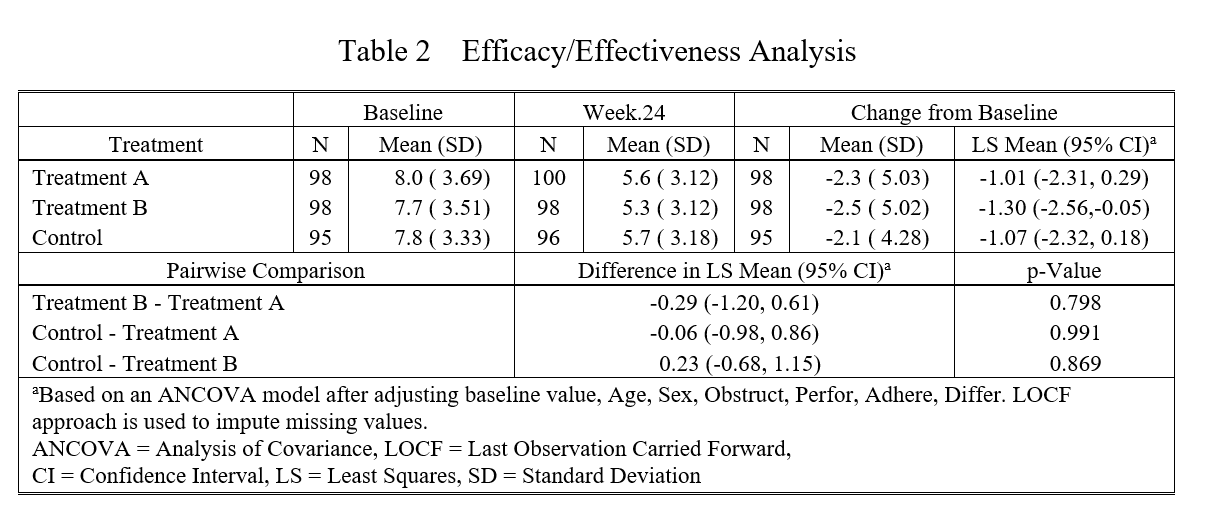
另外,还有缺失数据的填补,之前惯用的是LOCF法,就是如果终点疗效指标缺失,就用上一次离终点最近的一次测量值填补,这样的话在优效性设计里结果偏保守。当然这个方法已经过时了,现在一般用多重填补 Multiple imputation。
因此,做疗效比较是一个比较复杂的过程。但好在现在您拥有了Mstata医学统计机器人,下面只需要随便点点鼠标,一分钟就能无脑完成分析并生成上面这样的统计表。
4.6.3 准备数据
首先点击开始,点击”事先设置”,根据提示输入您的研究类型:
这个页面主要收集有关您的研究设计和数据类型的信息,然后系统AI会自动生成后面页面的界面,并内嵌适宜的统计模型。
主要关注的点是组间是否随机,如果随机,后面会嵌入简单的统计模型,如果非随机,您可以上传经过倾向性评分匹配后的数据,也可以在后面的界面中用多因素方法调整组间平衡。
另外是数据类型,如果您有基线和终点两次的数据,系统会用上述”双重差分”的理念用ANCOVA模型,如果您只有终点的数据,没有基线的数据,系统会改用ANOVA,不调整基线。如果您有多次测量,也一并上传,在基线和终点之间的测量值也是有用的,尤其是在缺失数据填补中有很大意义。
根据提示,下载生成的样例数据,然后在样例数据的基础上修改成您自己的数据,就可以上传开始分析啦。
4.6.4 疗效比较分析
第三部分:疗效比较分析
这一部分是整个工具的核心,用于评估不同治疗组在连续性结局变量上的疗效差异。系统支持两种统计模型:传统的方差分析/协方差分析(ANOVA/ANCOVA)和混合效应模型(Mixed Effects Model),并可根据需要调整协变量、处理缺失值。整个分析基于边际均值(estimated marginal means)和对比检验(contrasts),通过森林图可视化结果。
操作步骤如下:
1. 选择统计分析模型
点击问号图标可查看详细的模型选择指南。系统提供两种模型:
传统方差/协方差分析(ANOVA/ANCOVA):适用于单中心研究或各组样本独立、无聚类效应的情况。当不需要调整协变量时为单因素方差分析(ANOVA);需要调整协变量时为协方差分析(ANCOVA)。方法成熟,计算快速,结果解释直观。
混合效应模型(Mixed Effects Model):适用于多中心研究或存在群组聚类效应的数据(如同一医院的患者可能更相似)。包含固定效应(分组变量、协变量)和随机效应(如医院、城市等群组变量),可正确处理非独立性,避免I类错误率膨胀。推荐当中心数≥5个时使用。
原理:ANOVA/ANCOVA假设各组观测独立,适合简单设计;混合效应模型通过随机效应处理数据的层级结构(如患者嵌套在医院内),提供更可靠的推断。
2. 确认分组变量信息
系统自动显示第一部分选择的分组变量及其标签(只读显示,不可修改)。例如:“分组变量:治疗组别 (Group)”。确保这是您要分析的分组。
3. 选择结局变量
从下拉菜单选择代表连续性疗效结局的变量。菜单仅显示数值型(numeric)变量。例如,选择”Pain_VAS_24h”表示治疗后24小时的VAS疼痛评分。
原理:结局变量是疗效分析的核心。系统将比较各组在该变量上的均值差异。数据必须为数值型且尽量避免系统性缺失。
4. 设置结局变量标签
输入结局变量的描述性标签(如”治疗后24小时VAS疼痛评分”或”Blood Pressure”),该标签将在图表、表格和论文中显示,便于理解。系统会自动使用变量的原有标签作为默认值,您可以修改。
5. 比较设置(根据分组数量自动调整)
如果只有2组:系统自动设置为”与对照组比较”模式,隐藏比较类型和多重比较方法菜单(因为只有一次比较,无需调整)。系统会提示:第一个组(您在第一部分排序时放在最左边的组)已作为对照组,另一组将与其比较。如有误,请返回第一部分重新排序。
如果有3组或以上:显示完整的比较设置选项:
比较类型:
其他各组分别与对照组比较(推荐):所有其他组分别与第一个组(对照组)进行比较。系统会提示您确认对照组是否正确(第一个组)。如有误,返回第一部分重新拖拽排序,将正确的对照组放在最左侧。
全部两两比较:比较所有组之间的两两差异(如4组有6次比较)。
自定义比较:选择此项后,会出现复选框,列出所有可能的组对,您可勾选需要比较的特定组对。
多重比较校正方法:点击问号图标可查看详细说明。当进行多次比较时,应考虑多重比较校正以控制I类错误率(假阳性风险)。系统提供多种方法:
无:不进行校正。仅适用于预先指定的单一主要比较,或纯粹的探索性/描述性分析。
Bonferroni / Holm:通用方法,适用于任何比较结构。Bonferroni最保守,Holm是其改进版本。
Tukey HSD:专门针对全部两两比较设计,比Bonferroni效能更高。推荐用于全部两两比较。
Dunnett:专门针对多个治疗组分别与单一对照组比较设计,比Bonferroni效能更高。推荐用于与对照组比较。
其他方法(BH、BY、FDR等):不同的错误率控制策略。
原理:多重比较会膨胀I类错误率。例如,4组全部两两比较共6次,若不调整,总体I类错误率约26%(远超5%)。根据ICH E9指南,监管提交的关键分析应采用适当的多重性调整;探索性分析可报告未调整的p值,但应明确说明。
6. 协变量设置
从下拉菜单多选需要调整的基线特征(如年龄、性别、基线血糖值等)。可选项:
随机对照研究(RCT)或倾向性评分匹配后的分析:可以留空不调整协变量,因为随机化或PSM已平衡基线。
非随机的临床试验或观察性研究:建议选择组间存在混杂的变量进行多因素调整,以控制混杂偏倚。
如果选择了混合效应模型:有特别提示——如果是多中心研究,中心(医院)或代表地区、城市等变量,如果水平数<5个,可放在协变量中作为固定效应;如果水平数较多(≥5),不要放在这里,而应放在下面的随机效应菜单中。
原理:协方差分析(ANCOVA)在模型中纳入协变量,调整其影响,计算调整后的均值差,控制混杂(如年龄大组可能结局差,但非治疗原因)。混合效应模型中,固定效应协变量的作用类似。
7. 随机效应设置(仅混合效应模型时显示)
如果您选择了混合效应模型,会出现随机效应选择框。从下拉菜单选择代表群组cluster的变量(如医院、城市、国家等)。重要提示:
必须至少选择一个随机效应变量,否则无法进行下一步分析。如果您不需要调整群组因素,请在模块最上方选择传统分析方法(方差/协方差),而不是选择混合效应模型。
如果有层级嵌套的多个随机效应(如患者嵌套在医院内,医院嵌套在城市内,城市嵌套在国家内),可选择多个变量,并按照层级从低到高的顺序选择(例如:医院 → 城市 → 国家),顺序不要错。
只有至少选择了一个随机效应,后续的缺失值处理、数字格式设置和生成按钮菜单才会显现。
原理:随机效应处理群组聚类效应(如同一医院的患者可能更相似),避免违反独立性假设。嵌套随机效应(如医院嵌套在城市内)通过多层随机截距处理复杂的数据结构。
8. 缺失值处理设置
点击问号图标可查看详细说明(包括缺失值的重要性、各方法的原理、优缺点、如何选择等)。
如果您在第一部分选择了PSM(倾向性评分匹配):系统会显示提示——“沿用之前您在PSM模块中选择的缺失值处理方法,直接在匹配后的数据上做分析,不再处理缺失值。”此时隐藏缺失值处理菜单,因为PSM模块已处理缺失。
如果您没有选择PSM:显示缺失值处理选项,有两种方法:
完整案例分析(Complete Case Analysis, CCA):不做缺失值填补,剔除结局变量或协变量有缺失值的患者后分析。优点:简单直接,当数据完全随机缺失(MCAR)且缺失比例很小(<5%)时结果无偏。缺点:样本量减少,效能降低;当数据不是MCAR时(如随机缺失MAR或非随机缺失MNAR)会产生偏倚。
使用多重填补(Multiple Imputation, MI)处理缺失值:基于统计模型多次填补缺失值,生成多套完整数据集,分别分析后合并结果(使用Rubin’s rules)。优点:保留样本量,减少偏倚(在MAR假设下),标准误更准确(反映填补的不确定性)。缺点:计算复杂度较高,需要假设MAR。推荐当缺失率>5%时使用。
**如果选择多重填补,需要进一步设置**:
- **填补内容**(点击问号查看详细说明):
- 仅填补结局变量:适用于协变量完整或近乎完整的情况。协变量缺失的观测将被排除。
- 仅填补协变量:适用于结局变量完整的情况。结局变量缺失的观测将被排除。
- 同时填补结局变量和协变量(推荐):最全面,可保留更多观测,但需要更强的MAR假设。
- **填补套数**(点击问号查看详细说明):默认20套。传统上认为5-10套足够,但现代研究建议填补套数至少等于缺失比例的百分数(如30%缺失率,至少30套)。更多填补套数可更准确估计填补引入的方差,提高p值和置信区间的精度。
- **辅助变量选择方法**(点击问号查看详细说明):
- **我自行指定辅助变量**:手动选择。辅助变量是用于帮助预测缺失值的变量(本身不是分析模型中的变量)。纳入辅助变量可使MAR假设更合理,提高填补精度,减少偏倚。建议选择与结局变量、缺失指示变量、协变量相关的变量。系统默认全选所有符合条件的变量,但**会自动排除不重复值超过50的分类变量**(如ID号、病历号等),避免多重填补失败。您应将长文本、ID号等无意义变量去掉。
- **使用quickpred法让系统自动分析指定**:基于变量间相关性自动选择辅助变量。可设置最小相关性阈值(quickpred_mincor,默认0.1)、最小可用案例比例(quickpred_minpuc,默认0)、始终包含的预测变量(quickpred_include,可选)。
- **随机种子**:设置随机种子(默认12345)以确保结果可重复。原理:多重填补基于MAR假设,利用观测数据的分布填补缺失,避免简单剔除导致的偏差。辅助变量提供额外信息,使填补更准确。系统使用mice包实现链式方程(MICE)填补,对每套数据分析后用Rubin’s rules合并(合并估计值为平均值,合并标准误考虑组内方差和组间方差,后者反映填补的不确定性)。
9. 数字格式设置
调整小数位数:
- 均值保留小数位数(默认2位)
- P值保留小数位数(默认3位)
10. 点击生成按钮
点击”生成/更新分析结果”按钮。系统计算并显示:
主要结果(根据缺失处理方法不同):
描述性统计表:展示各组的样本量、均值、标准差、中位数、四分位间距等。原理:描述数据分布,帮助读者了解各组基线水平。
组间比较结果表:
如果使用多重填补(MI):显示MI调整后的主要分析结果(标注”主要分析(多重填补,MI)“),展示各组与参照组的均值差(Mean Difference, MD)、95%置信区间(CI)和P值。基于Rubin’s rules合并m套填补数据的结果,标准误考虑了填补的不确定性。
- 如果使用完整案例分析(CCA)或PSM后分析:直接显示CCA结果(标注”完整案例分析(CCA)“或”沿用PSM处理”),展示剔除缺失值后的分析结果。
- 表格中,如果调整了协变量,均值差为调整后的LS Mean Difference(最小二乘均值差,ANCOVA)或Marginal Mean Difference(边际均值差,混合模型);如果未调整协变量,则为Mean Difference。
- 原理:均值差(MD)量化治疗效果大小,CI反映不确定性,P值检验显著性。系统使用emmeans包基于边际均值(estimated marginal means)估计各组调整后均值,并进行对比检验(contrasts)。
比较结果森林图:可视化各组的均值差及置信区间。中轴线为0(无差异),线段不跨0表示显著差异。可通过右侧参数面板调整森林图外观(见下文)。原理:森林图直观展示效应量和显著性,便于快速识别组间差异。
附件表格:
ANOVA表(或混合效应模型结果):
- 传统ANOVA/ANCOVA:展示变异来源、自由度、F值、P值等统计量。
- 混合效应模型:展示固定效应系数表(包含变异来源、自由度、t值、P值等),以及模型summary输出(包括随机效应方差、残差方差等)。
- 原理:ANOVA表分解总变异为组间变异和组内变异,F检验评估组间差异显著性。混合效应模型通过最大似然估计(ML)或限制性最大似然(REML)估计固定效应和随机效应。
Emmeans表:展示各组边际均值(estimated marginal means)、标准误、置信区间等。原理:边际均值是调整协变量后的模型预测均值,代表各组在协变量均值处的期望结局值。
如果使用了多重填补,附件表格标注”多重填补后…“;如果使用完整案例分析,标注”完整案例分析…“。
敏感性分析(仅在使用多重填补时显示):
如果您选择了多重填补(MI)作为主要分析,系统会自动进行敏感性分析,即额外提供完整案例分析(CCA)的结果。包括:
- 敏感性分析 - 组间比较结果表(CCA)
- 敏感性分析 - 森林图(CCA)
- 敏感性分析附件表格:ANOVA表(CCA)、Emmeans表(CCA)、混合模型summary(CCA,如适用)
原理:敏感性分析检验结果的稳健性。如果MI和CCA结果一致(方向和显著性相同),说明结论可靠;如果不一致,需谨慎解读,考虑缺失机制的影响。根据FDA指南,主要分析使用多重填补,同时报告完整案例分析作为敏感性分析。
11. AI描述模块
生成表格后,可点击”用AI描述此表”获取结果段落草稿,便于论文撰写。
12. 调整森林图外观
森林图右侧有详细的参数控制面板,可自定义:
X轴坐标刻度设置:选择系统自动设置或手动设置(可输入下限、上限、刻度数值)。手动模式下,系统会验证刻度值是否在范围内。
列设置:修改第一列表头(如”Comparison”)、置信区间列标题(如”Mean Difference (95% CI)“或”LS Mean Difference (95% CI)*“,星号表示调整了协变量)、P值列表头(如”P value”);选择是否显示置信区间文本列。
底注设置:编辑森林图底注文字。系统会根据是否调整协变量自动生成默认底注(如”* LS Mean Difference adjusted for: Age, Sex”),您可修改。如果底注与坐标轴重叠,可在文字前添加空行。
点估计样式:选择点形状(圆形、方形、三角形、菱形)、点和线颜色、点大小。
线条设置:调整置信区间线宽、T型端点高度、线型(实线、虚线、点线)。
字体设置:调整基础字体大小、字体类型(无衬线、衬线、等宽)、X轴数字字体大小。
其他设置:选择是否添加表头线、设置表格底纹的两种颜色(交替显示)。
每次修改参数后,森林图会自动更新。可多次调整直到满意。调整后的森林图可下载(PNG、PDF、PPT格式)。
注意事项:
如果结果表格或森林图中出现极端值(如Inf、-Inf)或NA,可能是子群样本量太小或事件数不足,需检查数据。
混合效应模型需要足够的群组数量(通常≥5个)才能可靠估计随机效应。如果群组数太少,建议改用传统ANOVA/ANCOVA并将群组作为固定效应协变量。
多重填补的辅助变量选择很重要。避免包含高基数的分类变量(如ID号),否则会导致填补失败。系统已自动过滤,但如果仍有问题,手动移除可疑变量。
敏感性分析(CCA vs MI)结果如果差异很大,提示缺失机制可能不是MAR,需谨慎解读,可能需要进一步探索缺失模式或咨询统计学家。
结果可迭代更新(如改缺失处理方法、添加协变量、调整森林图参数等)。

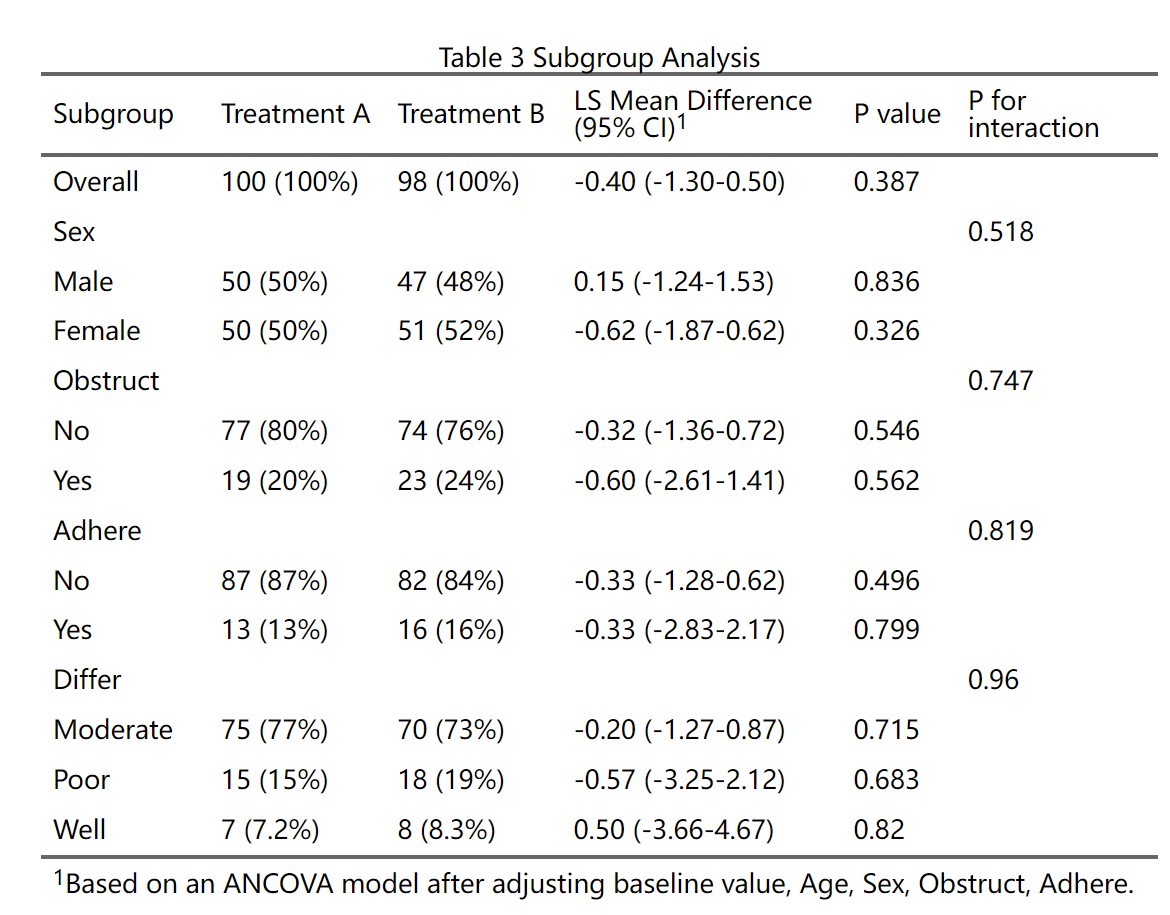
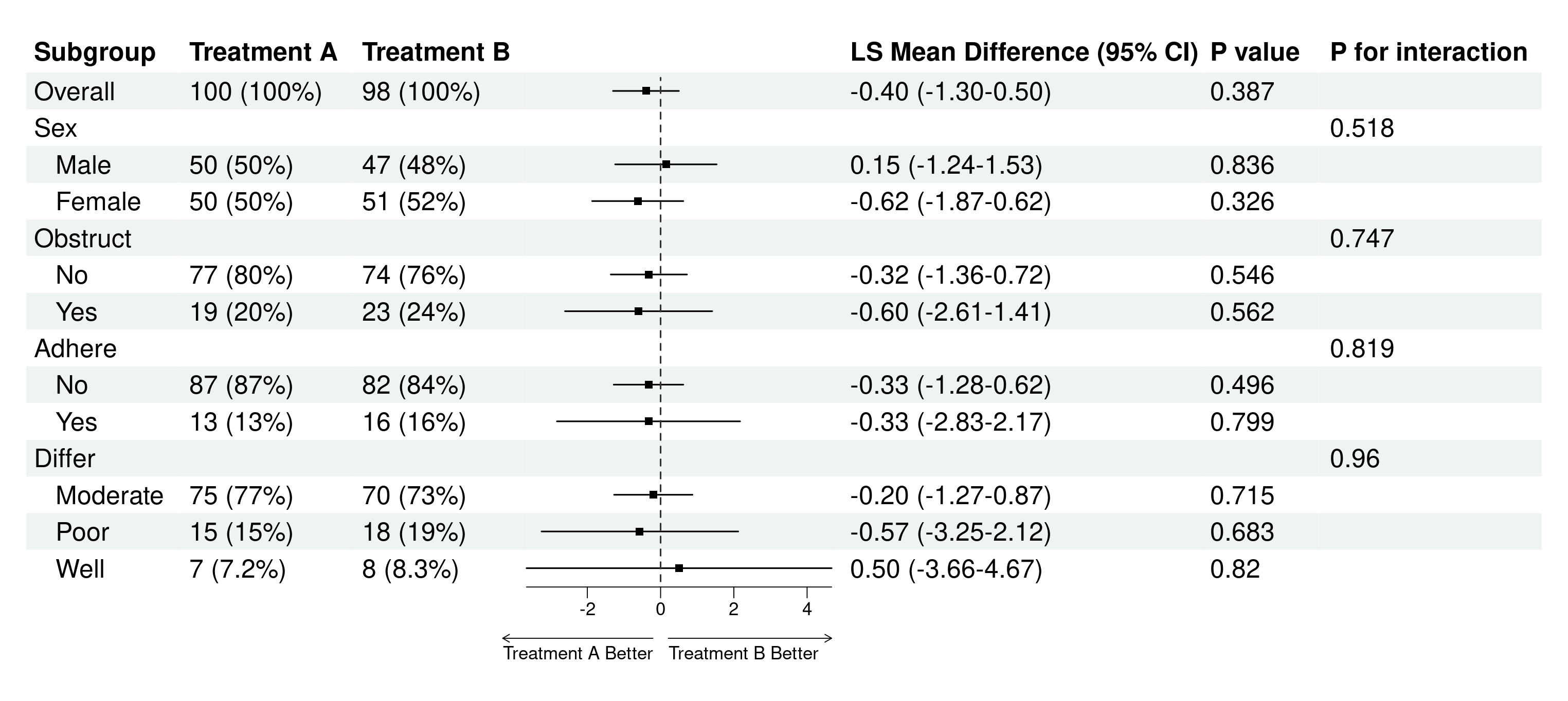
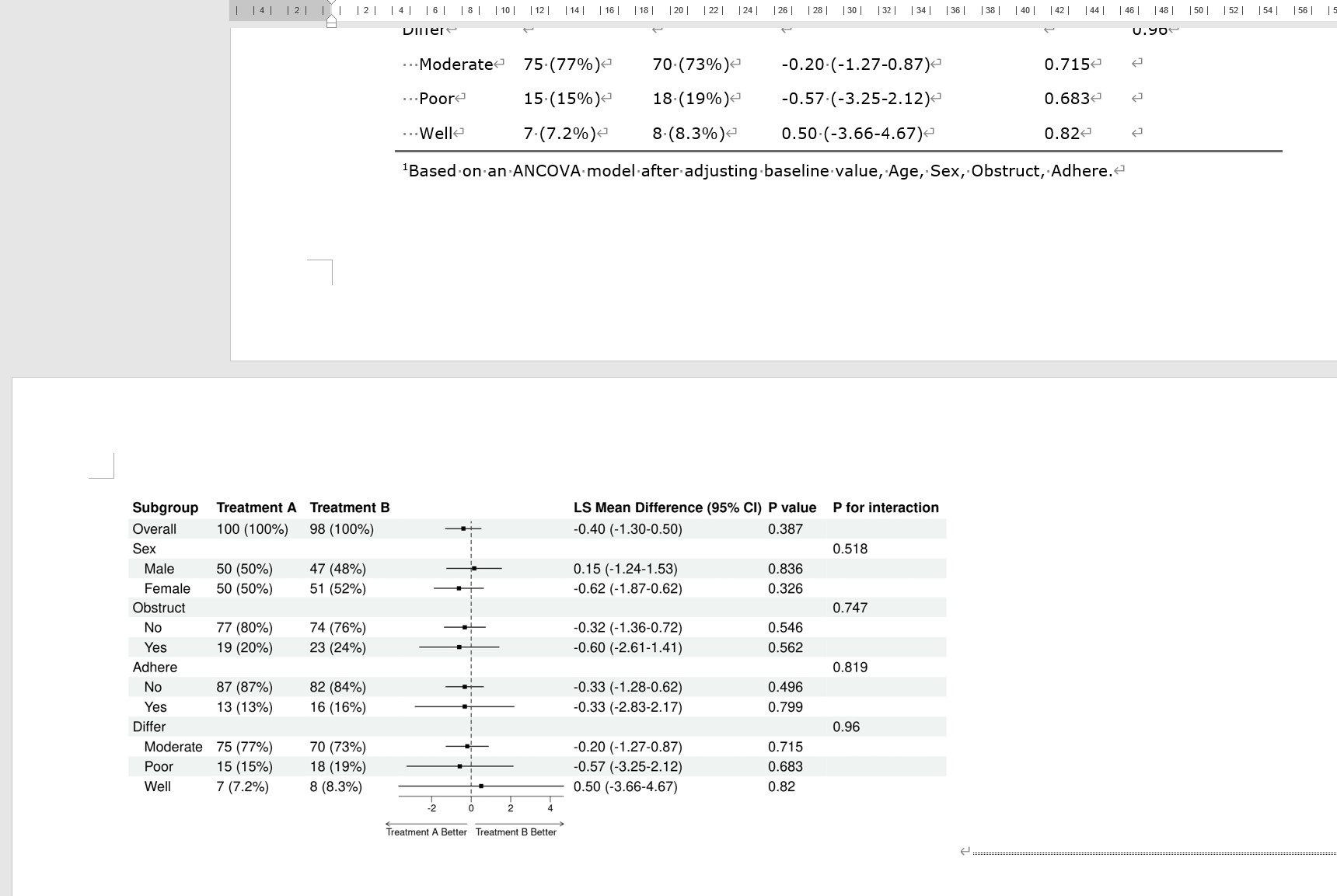
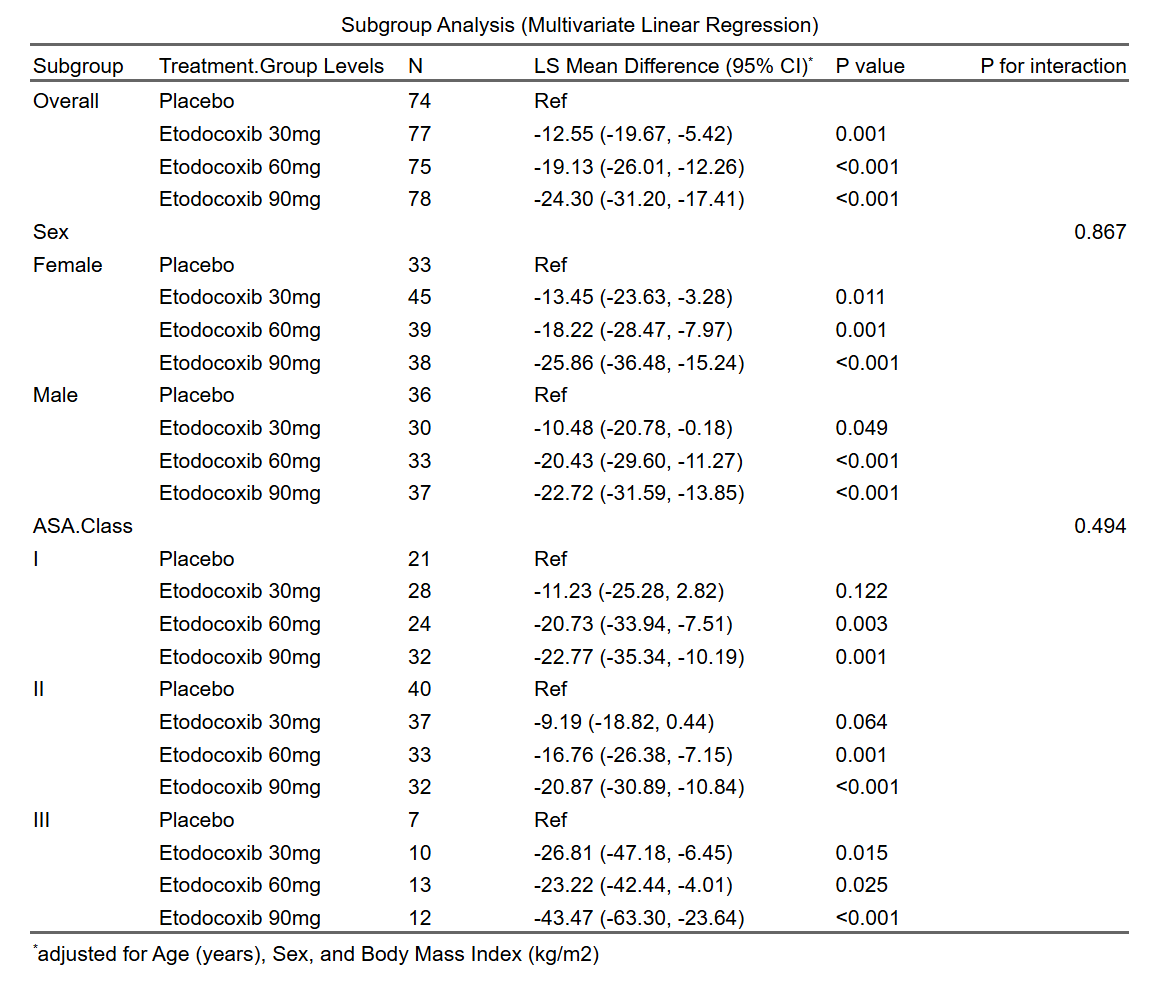
4.6.5 亚组(分层)分析
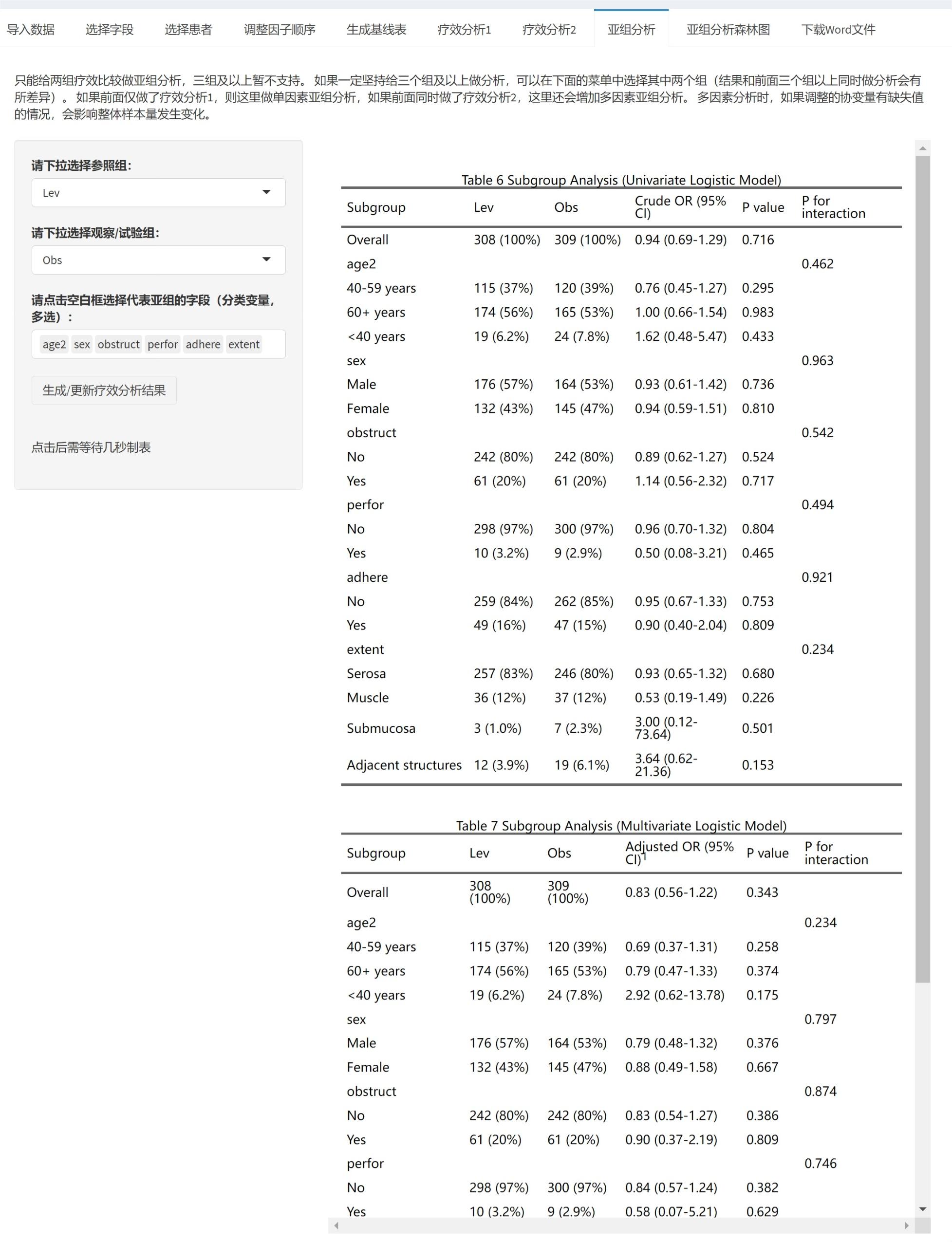
亚组分析(subgroup analysis)或分层分析(stratified analysis),是通过将数据按某些预定义的变量(如年龄、性别、疾病严重度等)分成子组,并在每个子组内分别进行统计分析,以评估治疗效果在不同子组之间的异质性。这有助于识别特定人群中治疗的潜在益处或风险,帮助个性化医学决策。但需谨慎解释,因为亚组分析可能增加假阳性风险,并可能导致过度解读。
亚组分析的前提条件(必须同时满足,缺一不可):
本模块的亚组分析功能目前有一定限制,仅在满足以下所有条件时才可使用:
必须使用ANOVA/ANCOVA模型(不支持混合效应模型):在第三部分”选择统计分析模型”时,必须选择”传统方差/协方差分析(ANOVA/ANCOVA)“,而不是”混合效应模型”。
分组条件:只有两组,或者有多组但在第三部分”比较设置”中选择了”其他各组分别与对照组比较”(即只进行与对照组的比较,不进行全部两两比较或自定义比较)。
不能使用多重填补:在第三部分”缺失值处理设置”中,必须选择”完整案例分析(Complete Case Analysis, CCA)“,而不是”使用多重填补(Multiple Imputation, MI)“。或者您在第一部分选择了PSM(倾向性评分匹配),沿用PSM的缺失处理。
不能选择多重比较调整:在第三部分”多重比较校正方法”中,必须选择”无”,而不是Bonferroni、Tukey等方法。(注:如果只有两组,系统自动隐藏此选项且默认为”无”,符合此条件。)
如果不满足以上任一条件,系统会在亚组分析部分显示警示信息,说明无法进行亚组分析,并列出不满足的具体条件。例如:
- “未选择ANOVA分析方法”
- “分组条件不满足(需2组或多组与对照组比较)”
- “使用了多重填补”
- “选择了多重比较调整P值”
并提示:“当前软件版本暂不支持在多重填补、多重比较P值调整后、自定义组间比较、混合效应模型的情况下进行亚组(分层)分析。如果您选择了这些选项,请等待下个版本更新后再进行亚组分析。”
您需要调整第三部分的设置(如改为ANOVA、改为CCA、改为无多重比较调整)后,才能进行亚组分析。
操作步骤如下(前提条件满足时):
1. 选择亚组(分层)变量
从下拉菜单多选需要进行亚组分析的变量。重要限制:
只支持factor类型的变量。如果您需要的变量不在列表中,请先返回”数据管理与准备”模块,将其转换为factor类型(例如,将连续的年龄变量分组为”<60岁”和”≥60岁”两个水平)。
可选择一个或多个变量(如性别、年龄组、疾病分期、基线特征、是否合并其他疾病等),探索疗效在不同人群中的异质性。
原理:每个亚组变量按其水平(factor的levels)分层,系统在全人群(Overall)和每个子群内分别建模,计算均值差(Mean Difference, MD)及其置信区间。同时,系统会检验治疗与亚组变量的交互作用(interaction),计算P for interaction(交互P值)。如果交互P值<0.05(或0.10,取决于预设阈值),表示治疗效果在子群间有显著差异,才有必要深入解读各亚组的结果。如果交互P值不显著,则应报告整体结果(全人群的MD),而非强调各亚组的结果。
注意事项:
亚组分析应基于临床或生物学合理性,而非数据驱动(data-driven)。建议在研究设计时预先指定少数几个(3-5个)关键亚组变量,避免事后大量探索导致假阳性。
如果是研究前就提前预先设定的亚组分析(写入了研究设计书中),且亚组分析的次数不多,则可以不做多重比较p值调整。如果是事后(post hoc)分析,则需要调整多重比较的P值,尤其是针对P for interaction(目前本模块未实现自动调整,需手动解释时说明)。
2. 表格列显示控制
您可以选择是否在亚组分析表格中显示以下列:
显示N列:勾选后,表格会显示各亚组内各治疗组的样本量(如”50”表示该亚组该治疗组有50人)。默认勾选。取消勾选后,N列将被隐藏,表格更简洁。
显示P value列:勾选后,表格会显示各亚组内治疗组间比较的P值(检验该亚组内组间差异的显著性)。默认勾选。取消勾选后,P value列将被隐藏,仅保留P for interaction列(用于判断异质性)。
原理:N列帮助评估子群样本充分性(小子群样本少,MD的CI宽、不稳定)。P value列显示各亚组内的组间比较结果,但需注意不应过度解读单个亚组的P值,而应结合P for interaction判断。
3. 数字格式设置
调整小数位数:
- 效应量(Mean Difference)及置信区间保留小数位数(默认2位)
- P值保留小数位数(默认3位)
4. 点击生成按钮
点击”生成亚组(分层)分析结果”按钮。系统计算并显示:
亚组分析结果表:
表格结构(以两组比较为例):
第一列(Subgroup):子群名称。首行为”Overall”(全人群总体分析,无P for interaction,这是正常的);后续行按亚组变量分层,每个变量的各水平缩进显示(如”性别”下有”男”和”女”)。
N列(如勾选显示):各治疗组在该亚组内的样本量(如”50 (45.5%)“表示该组50人,占该治疗组总数45.5%)。
效应量列:均值差(Mean Difference)或调整后均值差(如LS Mean Difference,取决于是否调整协变量),及其95%置信区间。如果某行的效应量和P值为空,但有P for interaction,说明该行仅为变量名(如”性别”),其下的子水平(“男”、“女”)才有具体数值。
P value列(如勾选显示):该亚组内组间比较的P值。如果<0.05,表示该亚组内组间差异显著。
P for interaction列:治疗与亚组变量的交互作用P值。仅在变量名行或Overall行显示。如果<0.05(或0.10),表示治疗效果在该亚组的不同水平间有显著异质性,即疗效因子群而异。
原理:系统使用线性回归模型,在模型中纳入治疗变量、亚组变量及其交互项(treatment × subgroup),并可调整协变量。交互项的似然比检验(likelihood ratio test)评估交互作用显著性。如果交互显著,说明治疗效果因亚组而异;如果不显著,说明治疗效果在各亚组内一致,应以整体结果为准。
注意:
表格第一行”Overall”是全人群分析,没有P for interaction是正常的(因为没有分层),不能描述为”未提供P for interaction”。
如果某行效应量估计值和P值为空,但有P for interaction,只需描述该亚组的P for interaction即可,绝不能描述为”效应量和P值未提供”。这是因为该行是变量名行,其下的子水平行才有具体数值。
如果子群样本量很小(如<20人),该子群的MD置信区间会很宽,结果不稳定,应谨慎解读。
生成后,可用AI描述模块点击”用AI描述此表”获取结果段落草稿。
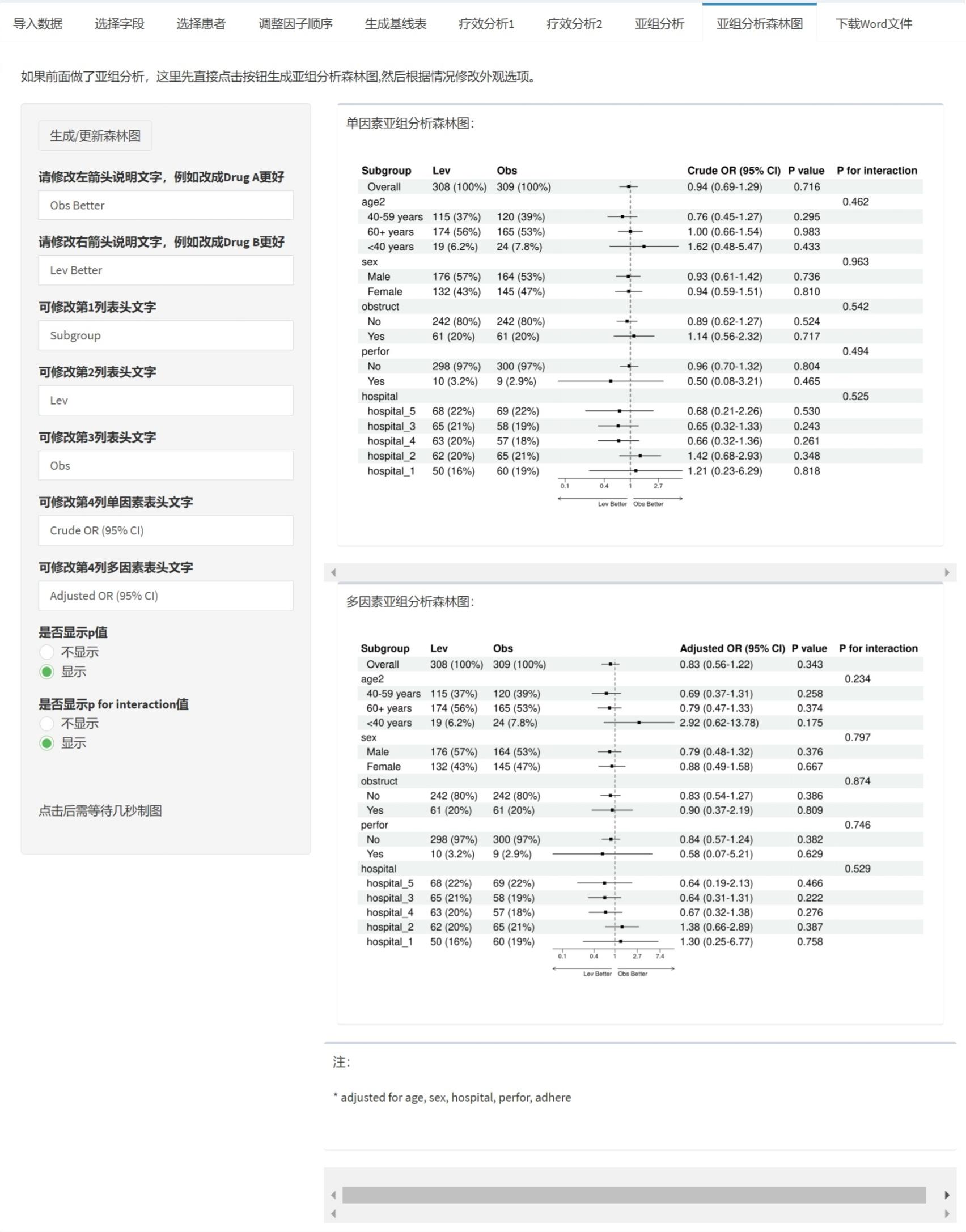
5. 生成并调整亚组分析森林图
点击表格下方的”亚组分析森林图”标签,系统自动生成亚组森林图。森林图右侧有详细的参数控制面板,可自定义(与主分析森林图参数类似):
X轴坐标刻度设置:系统自动或手动设置(下限、上限、刻度数值)。
列设置:修改第一列表头(如”Subgroup”)、置信区间列标题(如”Mean Difference (95% CI)“);选择是否显示置信区间文本列。
箭头设置(仅两组比较时显示):系统不知道您的研究是结局变量数值越高疗效越好,还是数值越低疗效越好,因此需要您根据实际情况填写左右箭头的文字。例如:
- 左侧箭头文字:“倾向于对照组”或”Favors Control”
- 右侧箭头文字:“倾向于治疗组”或”Favors Treatment”
- 箭头下方文字字体大小(默认0.8)
底注设置:编辑森林图底注。可在文字前添加空行避免与坐标轴重叠。
点估计样式:点形状、颜色、大小。
线条设置:线宽、T型端点高度、线型。
字体设置:基础字体大小、字体类型、X轴数字字体大小。
其他设置:是否添加表头线、表格底纹颜色。
每次修改参数后,森林图会自动更新。调整后可下载。
原理:亚组森林图可视化各亚组内的治疗效果及其置信区间,并标注P for interaction。通过观察各亚组的MD及CI是否跨越中轴线(0线),以及P for interaction是否显著,可快速识别异质性。箭头文字帮助解读方向(哪个组更好)。
如何解读亚组分析结果:
优先看P for interaction:如果<0.05(或0.10,根据预设),说明治疗效果在亚组间有显著差异,可深入解读各亚组结果。如果≥0.05,说明没有证据支持疗效因亚组而异,应报告整体结果(Overall),而非强调各亚组差异。
结合临床意义:即使P for interaction显著,也需结合临床和生物学合理性判断。避免过度解读偶然发现的差异(特别是事后分析)。
注意多重性:如果进行了多个亚组分析(如5个亚组变量),假阳性风险增加。如果是事后分析,建议调整P for interaction的阈值(如用0.01代替0.05),或在解释时强调探索性质。
小样本谨慎:子群样本量小时,MD的CI宽,统计效能低,结果不稳定。
常见问题:
Q:我的研究有三个以上治疗组,可以做亚组分析吗?
A:可以,但前提是您在第三部分选择了”其他各组分别与对照组比较”(而非”全部两两比较”或”自定义比较”)。系统会在各亚组内分别计算各组与对照组的MD,并检验交互作用。
Q:亚组分析的交互P值不显著,是否可以报告各亚组的结果?
A:交互P值不显著表示没有证据支持疗效在亚组间有差异,此时应报告整体结果(全人群的MD),而非强调各亚组的结果。但如果有强烈的临床或生物学理由(如先验假设年轻人获益更多),可在讨论中谨慎提及亚组趋势,并强调需要进一步验证。根据ICH E9指南,亚组分析应作为探索性分析,结果需谨慎解读。
Q:为什么我的亚组分析不支持混合效应模型或多重填补?
A:当前版本的亚组分析功能尚未实现对混合效应模型和多重填补的支持(涉及复杂的交互项估计和合并规则)。如果您的主分析使用了这些方法,可以先在CCA和ANOVA设置下进行亚组分析作为探索性分析,或等待软件后续更新。
Q:我可以根据连续变量(如年龄)做亚组分析吗?
A:本模块仅支持factor类型的亚组变量。如果您想按年龄分组(如<60岁 vs ≥60岁),请先在”数据管理与准备”模块中将连续的年龄变量转换为分类变量(创建新变量如”年龄组”,设为factor),然后选择该新变量作为亚组变量。
结果可迭代更新(如添加/移除亚组变量、调整森林图参数等)。亚组分析森林图和表格可用于论文的正文或补充材料。
 ### 下载word文件 {#downloadwordcont}
### 下载word文件 {#downloadwordcont}
最后进入”下载word文件”
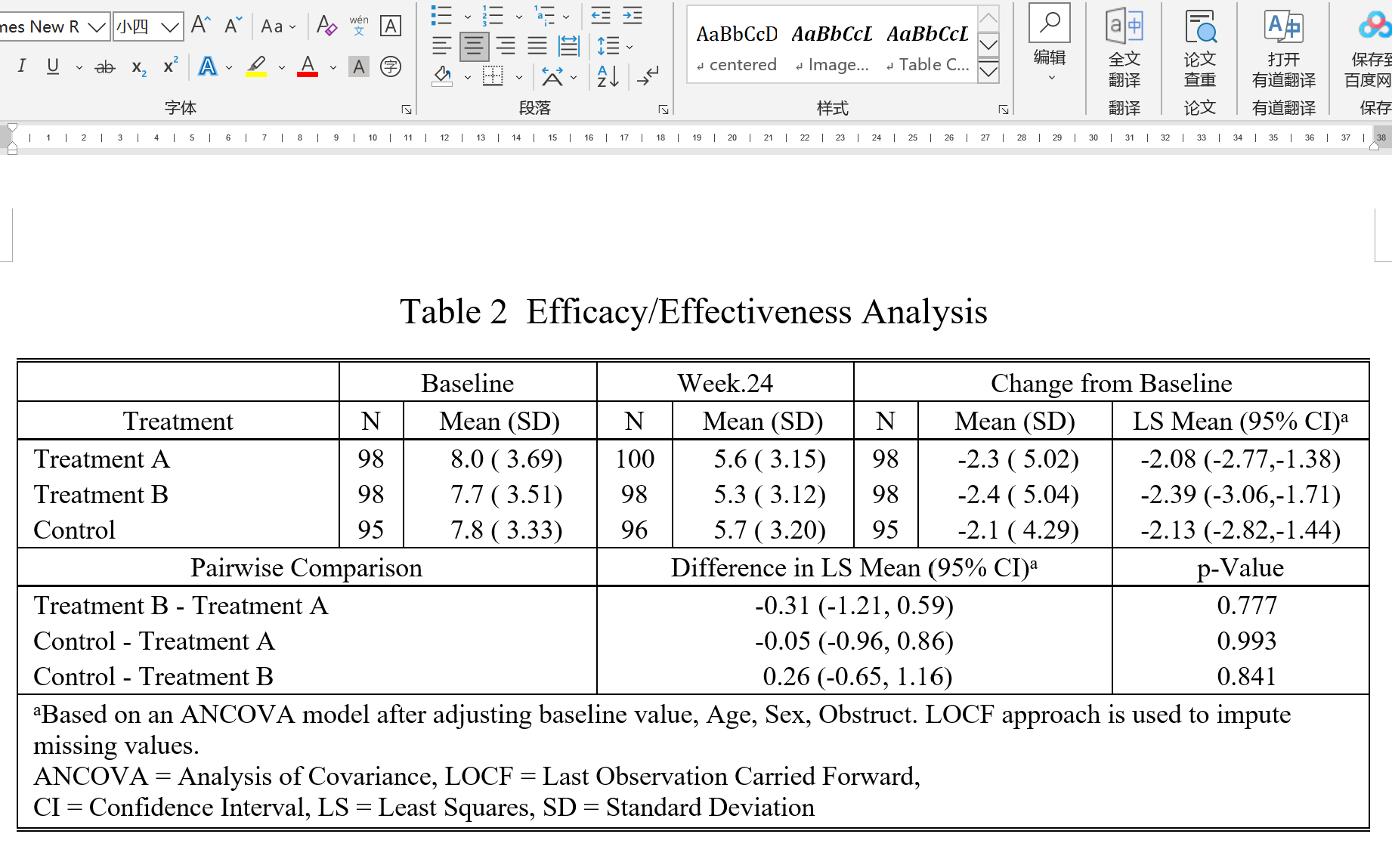
下载的文档包括基线表(Table 1)和疗效分析表(Table 2)。
我们可以看到,表格底注的统计方法文字,是根据研究设计和您的选项动态变化的:
4.7 多臂疗效比较(结局为连续性变量,仅在治疗后检测一次结果,如术后疼痛评分等)
功能: 本工具可以对两组或两组以上的患者进行治疗效果评价统计分析,支持连续性变量作为疗效结局。
结局类型: 疗效结局为治疗后一次测量的连续性变量,例如治疗后24小时的疼痛评分(VAS、NRS)、生物标志物水平等。
研究设计: 支持随机对照研究(RCT)或非随机分组研究;可以是前瞻性或回顾性研究;适用于干预性或观察性研究。
主要特点:
根据研究设计自动选择合适的统计方法,包括不调整、倾向性评分匹配(PSM)或多因素回归调整组间平衡。
支持方差分析(ANOVA)、协方差分析(ANCOVA)、混合效应模型等多种分析方法。
提供缺失值处理方案:多重填补(Multiple Imputation)或完整病例分析(CCA)。
生成符合学术规范的高质量图表,适合顶级医学杂志要求。
操作简单,用户无需深厚统计知识即可完成分析。
分析过程中逐步引导用户理解临床研究设计和统计原理,使用后用户可掌握相关知识。
最终生成一篇论文初稿

一键自动生成以下图表和表格:
- 基线特征表(Table 1)
- 描述性统计表(Descriptive Statistics Table)
- 组间比较结果表(Group Comparison Results Table)
- 比较结果森林图(Forest Plot)

- 亚组分析表(Subgroup Analysis Table)
- 亚组分析森林图(Subgroup Forest Plot)
- PSM匹配前后SMD比较表和Love Plot(如选择PSM)
- 方差分析表和估计边际均值表(ANOVA & Emmeans Tables)
- 混合效应模型组间比较(Mixed model)

- 缺失值多重填补后结果(Multiple Imputation)
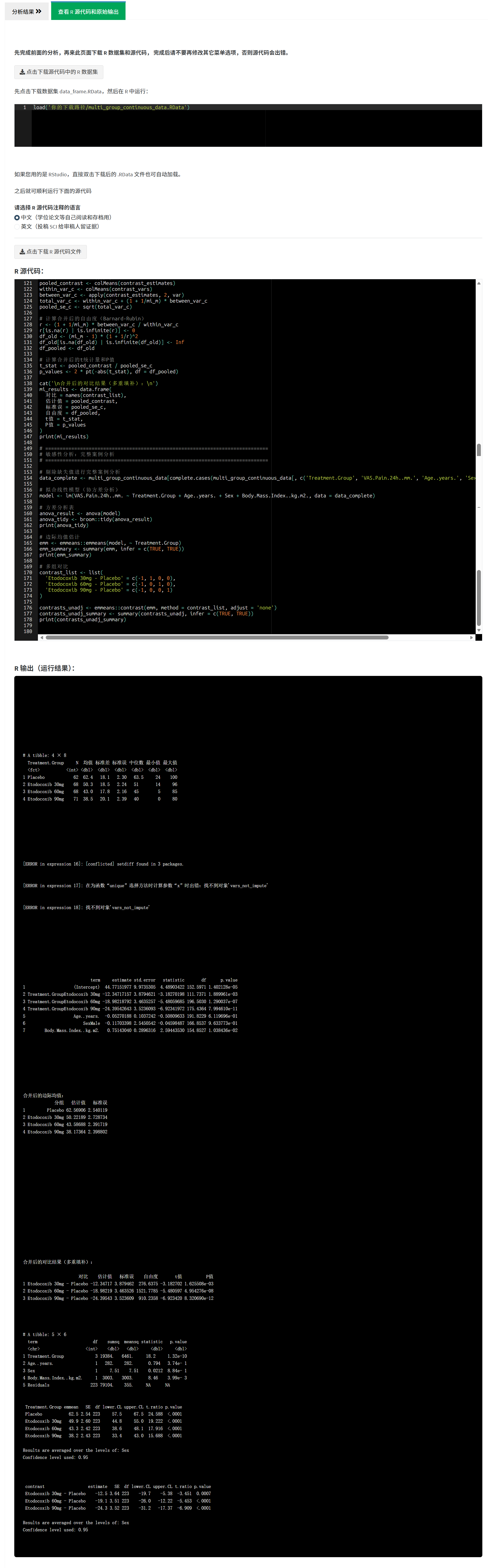
- R 源代码自动生成作为投稿证据
4.7.1 基础知识
当疗效评价指标为连续性变量时,且只在治疗后评估一次(非重复测量)时,使用本工具进行分析。
如何评价疗效?
常见的连续性疗效评价指标包括:治疗后的疼痛评分(如VAS评分0-10分、NRS评分)、血压值(收缩压、舒张压)、生物标志物水平(如血清炎症因子浓度)、功能评分(如生活质量评分)等。统计分析主要通过比较各组的均值或中位数差异、计算均值差(Mean Difference, MD)及其置信区间、进行方差分析检验等来评估治疗效果。
组间基线平衡
对于随机对照研究(RCT),组间基线通常已平衡,无需额外调整。对于非随机分组研究(如回顾性或观察性研究),可能存在基线差异,可通过倾向性评分匹配(PSM)或多因素回归调整协变量(ANCOVA),以减少混杂影响。
统计方法选择
本工具提供以下分析方法:
- 单因素方差分析(ANOVA):适用于RCT或PSM匹配后的数据,不调整协变量。
- 协方差分析(ANCOVA):在分析模型中直接调整协变量,控制混杂因素。
- 混合效应模型(Mixed Effects Model):适用于包含群组聚类效应的数据(如多中心研究),通过随机效应(如医院、城市)处理非独立性。
缺失值处理
本工具支持两种缺失值处理策略:
- 多重填补(Multiple Imputation, MI):使用统计方法填补缺失值,保留更多样本,提高统计效能。
- 完整病例分析(Complete Case Analysis, CCA):剔除含有缺失值的样本,仅分析完整数据。
4.7.2 准备数据
首先下载样例数据:
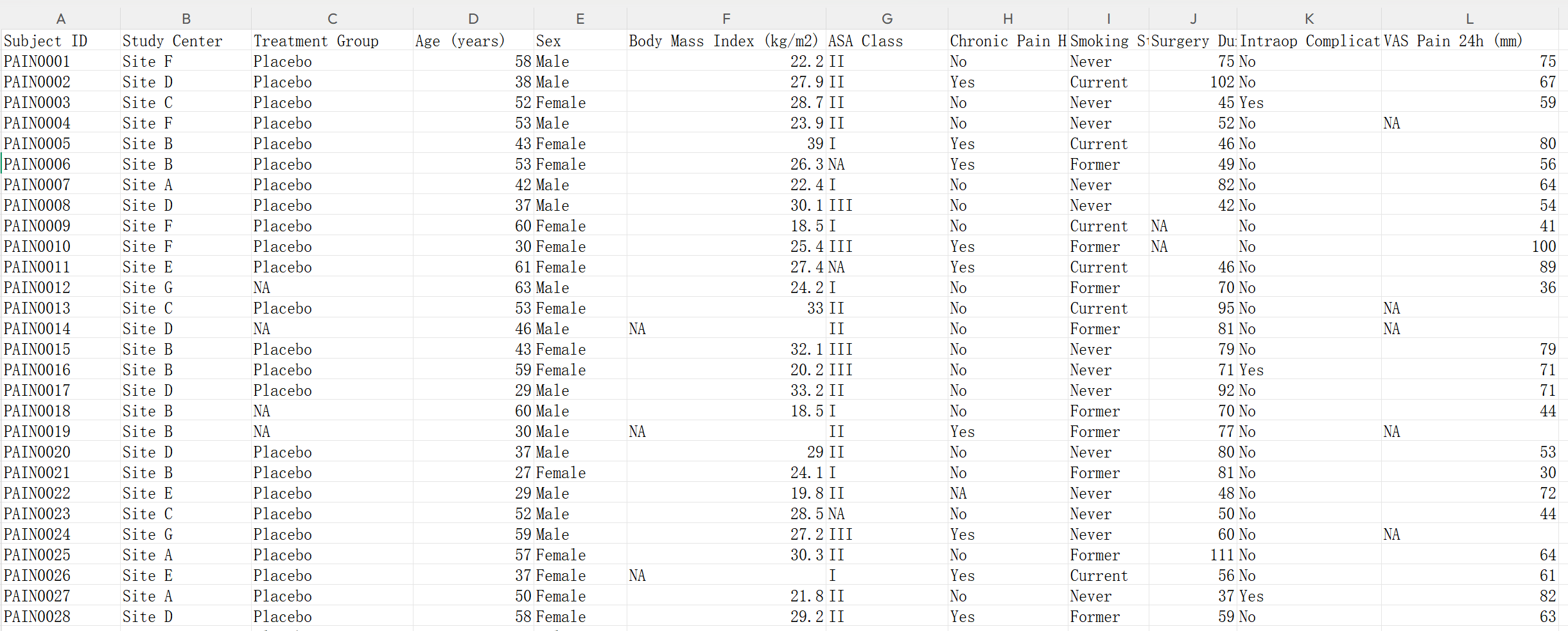
数据格式说明:
数据应为宽表格式(每个患者一行),包含以下类型变量:
代表治疗分组的变量:例如上图中的 Treatment Gropup。
代表疗效评价的连续性变量:例如上图中的VAS Pain 24h,表示治疗后24小时的VAS疼痛评分。该变量必须是数值型。
基线人口学和临床特征:例如上图中的Age、Sex等指标,可用来调整组间平衡,也可用来做亚组分析。
数据准备要点:
- 治疗分组变量必须是分类变量(factor型),且水平数不宜超过10个。
- 连续性结局变量必须是数值型(numeric),单位统一(如均为mm Hg或均为0-10分)。
- 基线变量中,连续变量为数值型,分类变量为因子型。
- 缺失值:空白单元格处理,或者写 NA(csv文件支持写NA)。
下载生成的样例数据,然后在样例数据的基础上修改成您自己的数据,就可以上传开始分析啦。
4.7.4 疗效比较分析
第一部分:研究设计设置
这一部分是整个分析流程的起点,主要目的是定义研究的分组方式和处理组间潜在混杂的方法。通过这些设置,系统能够根据您的研究类型自动优化后续分析路径,确保结果的科学性和可靠性。混杂(confounding)是指一些基线因素(如年龄、性别、疾病严重度)可能影响治疗组间的比较,导致观察到的疗效差异并非真正由治疗引起,而是受这些因素干扰。正确处理混杂是保证因果推断准确的关键。
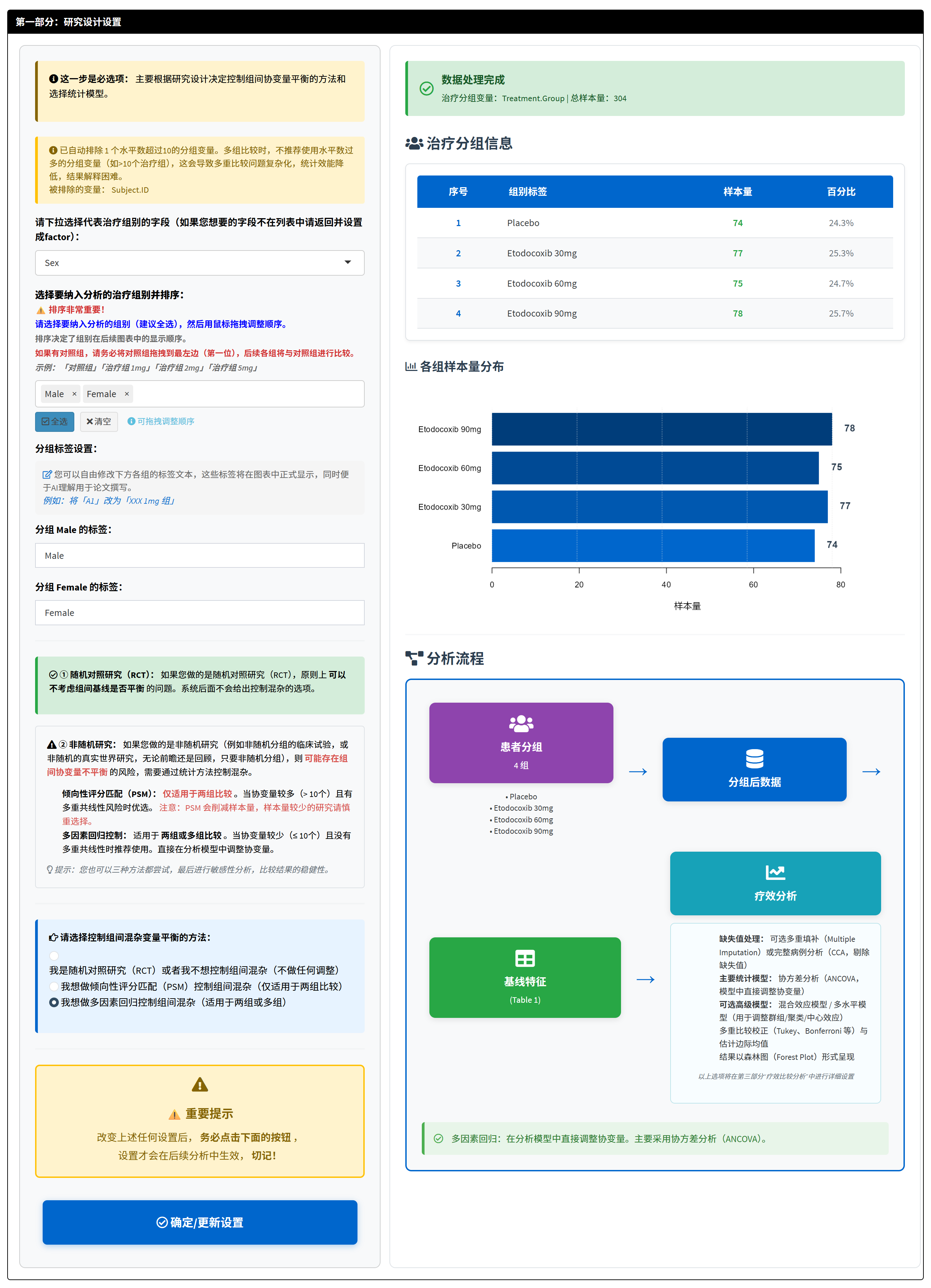
操作步骤如下:
选择代表治疗组别的变量:从下拉菜单中选择表示分组的变量(如样例中的”Group”)。这个变量必须是分类变量(factor型),代表不同治疗组(如对照组、低剂量组、中剂量组、高剂量组)。系统支持两组或多组分析。
选择并排序分组水平:系统自动列出所有分组水平,您需要选择要纳入分析的组别(建议全选),然后用鼠标拖拽调整顺序。排序非常重要:第一个组别默认为参照组(对照组),后续各组将与参照组进行两两比较。例如,如果有四组(对照组、低剂量组、中剂量组、高剂量组),应将对照组拖拽到最左边(第一位),则分析将计算”低剂量 vs 对照”、“中剂量 vs 对照”、“高剂量 vs 对照”的差异。
设置分组标签:您可以为每个组别输入更有意义的标签(如”安慰剂对照组”、“XXX药物 1mg组”),这些标签将在图表中正式显示,便于理解和论文撰写。
选择控制组间混杂变量平衡的方法:根据您的研究设计,从三个选项中选择一个。系统会根据选择弹出相应界面。
随机对照研究(RCT)或不想控制组间混杂(不做任何调整):适用于随机分组的研究(如RCT),其中患者随机分配到各组,理论上基线特征已平衡,无需额外调整。原理:随机化确保组间差异仅由随机误差引起,而非系统偏差。选择此项,直接进入疗效分析,无需平衡步骤。系统将采用单因素方差分析(ANOVA)。
倾向性评分匹配(PSM)控制组间混杂:适用于非随机分组的研究(如回顾性或观察性研究),仅支持两组比较。原理:PSM通过logistic回归计算每个患者的”倾向评分”(接受某种治疗的概率),然后匹配评分相似的患者,模拟随机化,减少选择偏差和混杂影响。优点:直观平衡基线,减少样本偏差;缺点:可能丢失样本(匹配失败的患者被剔除),且仅限两组。选择此项,进入第二部分进行匹配细节设置。
多因素回归控制组间混杂:适用于非随机分组,支持两组以上。原理:在统计模型中同时纳入治疗变量和协变量,调整协变量的影响,计算调整后的均值差。优点:保留全部样本,处理多组和连续协变量;缺点:需满足模型假设(如无多重共线性),否则结果不可靠。选择此项,直接进入疗效分析,并在后续步骤选择协变量。系统将采用协方差分析(ANCOVA)。
- 确定/更新设置:完成上述选择后,务必点击”确定/更新设置”按钮,设置才会在后续分析中生效。点击后,系统会处理数据,并在右侧显示分组信息概要(包括各组样本量、百分比、条形图和分析流程图)。
第二部分:生成基线表或PSM(可选)
这一部分根据第一部分的研究设计设置自动调整内容。如果您选择了随机对照研究(RCT)或不调整混杂(或多因素回归),系统会引导生成基线特征表(Table 1),用于描述组间人口学和临床特征的分布,帮助读者了解样本组成。如果选择了倾向性评分匹配(PSM),则进入匹配流程,用于平衡非随机分组的基线差异。
此部分是可选的,如果您对基线平衡不感兴趣,可直接跳到第三部分。但生成基线表或进行PSM能提升结果的可信度,尤其在非随机研究中。
如果选择RCT或多因素回归(生成基线特征表):
操作步骤如下:
选择分组变量:系统自动使用第一部分选择的治疗组别变量作为分组依据(如Group)。
选择基线变量:从下拉菜单中多选需要展示的基线特征(如年龄、性别、基线血糖值等)。建议选择与研究相关的变量,至少2个。连续变量(如年龄)会自动识别为数值型,分类变量(如性别)为因子型。选择顺序决定表中变量的排列(从上到下)。
生成表格:点击生成按钮,系统自动计算并显示Table 1。表格包括:
- 每列代表一个组,展示均值±标准差(连续变量)或计数(百分比)(分类变量)。
- 可选显示组间P值(使用方差分析、Kruskal-Wallis检验或卡方/Fisher检验,根据变量类型和组数自动选择)。
- 对于RCT,建议不显示P值,因为随机化已确保平衡,P值比较可能误导。
原理:基线表描述样本特征,帮助评估组间相似性。在RCT中,任何差异均为随机;在非随机研究中,它揭示潜在混杂,为后续调整提供依据。
如果选择PSM(倾向性评分匹配):
操作步骤与生存资料模块类似,分四个子步骤。PSM仅支持二分类组别(两组),多组需分步处理或改用多因素回归。
基础设置:选择组别变量(必须为两组)和基线变量(至少2个需平衡的变量)。系统自动将人数多的组设为对照组,人少的为干预组。
缺失处理:选择剔除缺失或用KNN填补基线变量缺失值。
PSM匹配:选择方法(optimal、nearest等)、比例(1:1、1:2等)、卡钳值,点击开始匹配,生成SMD表和Love Plot。
匹配前后P值表(可选):生成匹配前后组间P值比较表。
完成此部分后,系统使用平衡数据进入第三部分疗效分析。
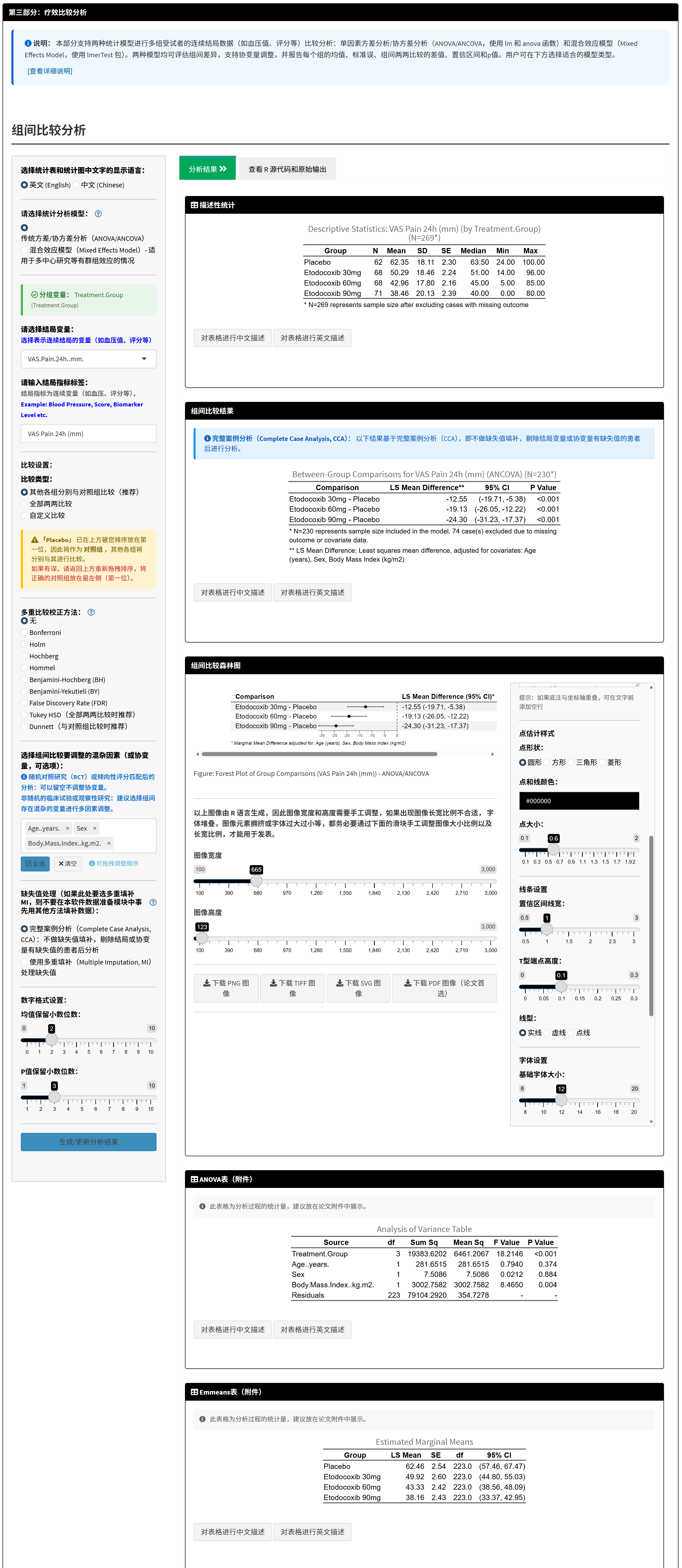
第三部分:疗效比较分析
这一部分是整个工具的核心,用于评估不同治疗组在连续性结局变量上的疗效差异。系统采用方差分析(ANOVA)或协方差分析(ANCOVA)比较各组均值,计算均值差(Mean Difference, MD)及其置信区间,并通过森林图可视化结果。如果选择了多因素回归,还会调整协变量以控制混杂。
操作步骤如下:
- 选择结局变量:从下拉菜单选择代表连续性疗效结局的变量(如样例中的Pain_VAS_24h),这是一个数值型变量,表示治疗后的测量值(如疼痛评分、血压值)。
原理:结局变量是疗效分析的核心,系统将比较各组在该变量上的均值差异。数据必须为数值型且无系统性缺失,否则影响准确性。
为结局变量设置标签:输入结局变量的描述性标签(如”治疗后24小时VAS疼痛评分”),该标签将在图表和论文中显示,便于理解。
选择缺失值处理方法:
- 多重填补(Multiple Imputation, MI):推荐方法。使用统计方法(如MICE算法)填补缺失值,保留更多样本,提高统计效能。系统默认进行5次填补,每次填补生成一个完整数据集,最后合并结果。优点:减少偏差,保留样本量;缺点:计算稍慢。
- 完整病例分析(Complete Case Analysis, CCA):剔除任何变量有缺失的样本,仅分析完整数据。优点:简单直观;缺点:可能丢失大量样本,导致偏差和效能降低。
原理:缺失值会影响统计推断。多重填补基于观测数据的分布填补缺失,避免简单剔除导致的样本量损失和偏差。
- 如果选择多因素回归,选择协变量(可选):如果第一部分选择了”多因素回归控制组间混杂”,会出现协变量选择框。多选需调整的基线特征(如年龄、性别、基线血糖值),但避免过多(一般不超过10个,以防过拟合)。
原理:协方差分析(ANCOVA)在模型中纳入协变量,调整其影响,计算调整后的均值差,控制混杂(例如,年龄大组可能疼痛评分高,但非治疗原因)。
- 是否使用混合效应模型:如果您的数据包含群组聚类效应(如多中心研究、同一医院的患者可能更相似),可勾选”使用混合效应模型”,并选择随机效应变量(如医院、城市)。
原理:混合效应模型通过随机效应处理数据非独立性,避免传统方差分析假设的违背,提供更可靠的推断。适用于多层次数据结构。
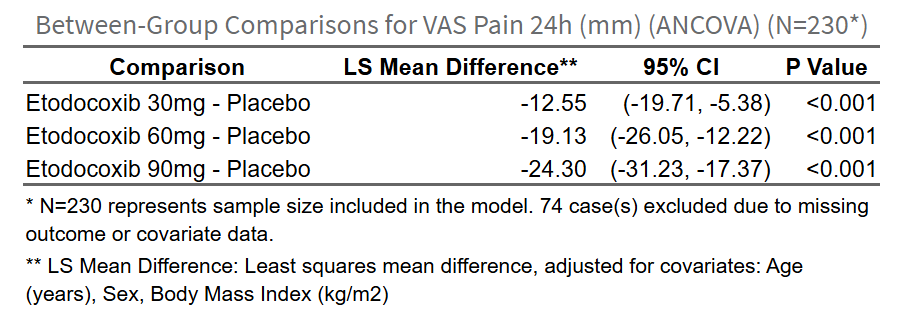
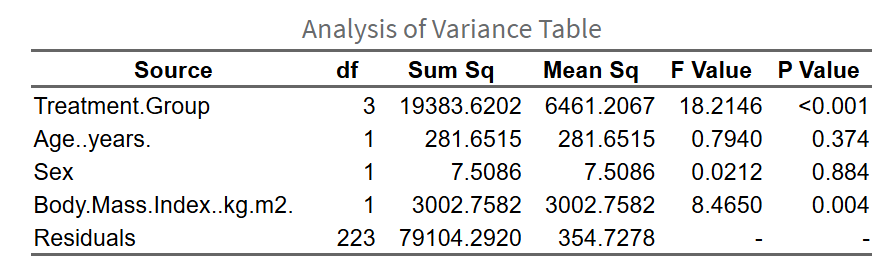
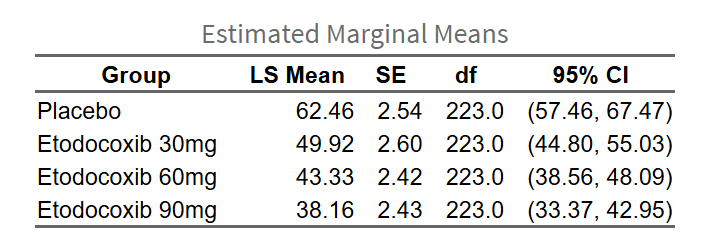
- 点击生成结果:调整小数位(如均值1位、MD 2位、P值3位),点击”生成/更新疗效分析结果”。系统计算并显示:
- 描述性统计表(Descriptive Statistics Table):展示各组的样本量、均值、标准差、中位数、四分位间距等。原理:描述数据分布,帮助读者了解各组基线水平。
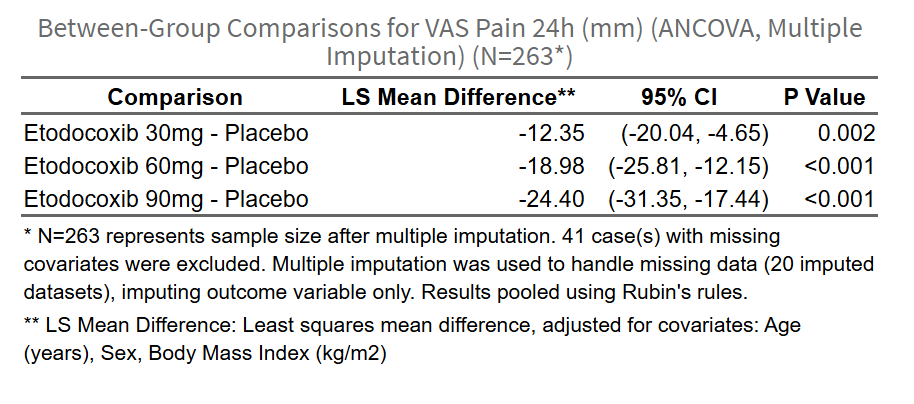
- 组间比较结果表(Group Comparison Results Table):展示各组与参照组的均值差(MD)、95%置信区间(CI)和P值。如使用多重填补,显示MI调整后的结果;如使用完整病例分析,显示CCA结果。原理:MD量化治疗效果大小,CI反映不确定性,P值检验显著性。
- 比较结果森林图(Forest Plot):可视化各组的均值差及置信区间,中轴线为0(无差异),线段不跨0表示显著差异。原理:森林图直观展示效应量和显著性,便于快速识别组间差异。
生成后,可用AI描述模块点击”用AI描述此表”获取结果段落草稿。
- 调整森林图外观:系统提供丰富的自定义选项,包括图形尺寸、颜色、字体、坐标轴范围、是否显示数值列、底箭头文本等。调整后点击”生成/更新森林图”更新图形。
结果可迭代更新(如改缺失处理方法、添加协变量等)。
4.7.5 亚组分析
亚组分析是主疗效分析的深入扩展,用于考察治疗效果在不同患者子群(如根据年龄、性别、疾病严重度等划分)中的一致性或差异。这有助于识别潜在的治疗效果修饰因素,即某些基线特征是否会改变治疗的相对疗效。例如,在一个治疗组 vs 对照组的比较中,分析是否年轻患者比老年患者获益更多,从而指导临床决策和未来研究。
亚组分析的原理是通过分层建模,在每个子群内单独计算均值差(MD)及其置信区间,同时检验治疗与子群变量的交互作用(P for interaction),以评估异质性。如果交互P值<0.05,表示疗效在子群间显著不同;否则,整体结果适用于所有子群。但需注意,亚组分析易受小样本影响(增加假阳性风险),建议作为探索性分析,仅在生物学合理时解读。
本部分仅支持两组疗效比较(三组以上暂不支持),因为多组交互计算复杂,可能导致结果不稳定。需在疗效比较分析完成后进行(使用相同数据和模型设置)。
操作步骤如下:
进入”亚组分析”标签:确认前一步疗效分析已完成,且分组为两组(系统会自动校验)。
选择参照组和观察组:从下拉菜单选择参照组(基准组,如对照组)和观察组(比较组,如治疗组)。参照组是计算MD的参考(MD=观察组均值-参照组均值),通常选对照组,便于解读正向疗效(MD>0表示观察组更好,如疼痛评分降低更多)。
选择亚组变量:从下拉菜单多选分类变量作为子群划分依据(如年龄分组<60 vs ≥60、性别男 vs 女)。变量必须有2-10个水平(太多水平导致子群过细,计算失败或结果不可靠)。建议选临床意义强的变量(如3-5个),避免无关或高维度变量。
原理:每个变量按水平分层,系统在全人群(Overall)和每个子群内分别建模,计算MD。整体行无交互P值(正常),子群行显示样本分布,帮助评估子群样本充分性(小子群样本少,MD CI宽、不稳定)。
- 点击生成结果:点击”生成/更新亚组分析结果”按钮,系统自动计算并显示亚组分析表。表格结构:
子群列:整体(Overall)和每个变量的水平(子水平缩进显示)。
组别样本量列:参照组和观察组的样本量。
MD (95% CI)列:子群内均值差及其置信区间(如-1.50 (-2.30, -0.70))。
P值列:子群内MD的显著性(<0.05表示组间差异)。
交互P值列(P for interaction):检验治疗效果在子群间的异质性(<0.05表示显著差异,如治疗在年轻组更有效)。
生成后,可用AI描述模块获取结果段落草稿。
- 生成并调整亚组分析森林图:点击”生成亚组分析森林图”,系统显示森林图。调整外观:宽度/高度、颜色、字体、坐标轴范围、是否显示数值列、底箭头文本等。
原理:森林图可视化亚组MD,突出交互作用(交互P值标注)。交互P检验治疗-子群交互,指导是否报告子群特异效果。
结果可迭代更新(如添加/移除子群变量)。如果子群过多或样本小,优先报告交互P值显著的亚组,避免过度解读。
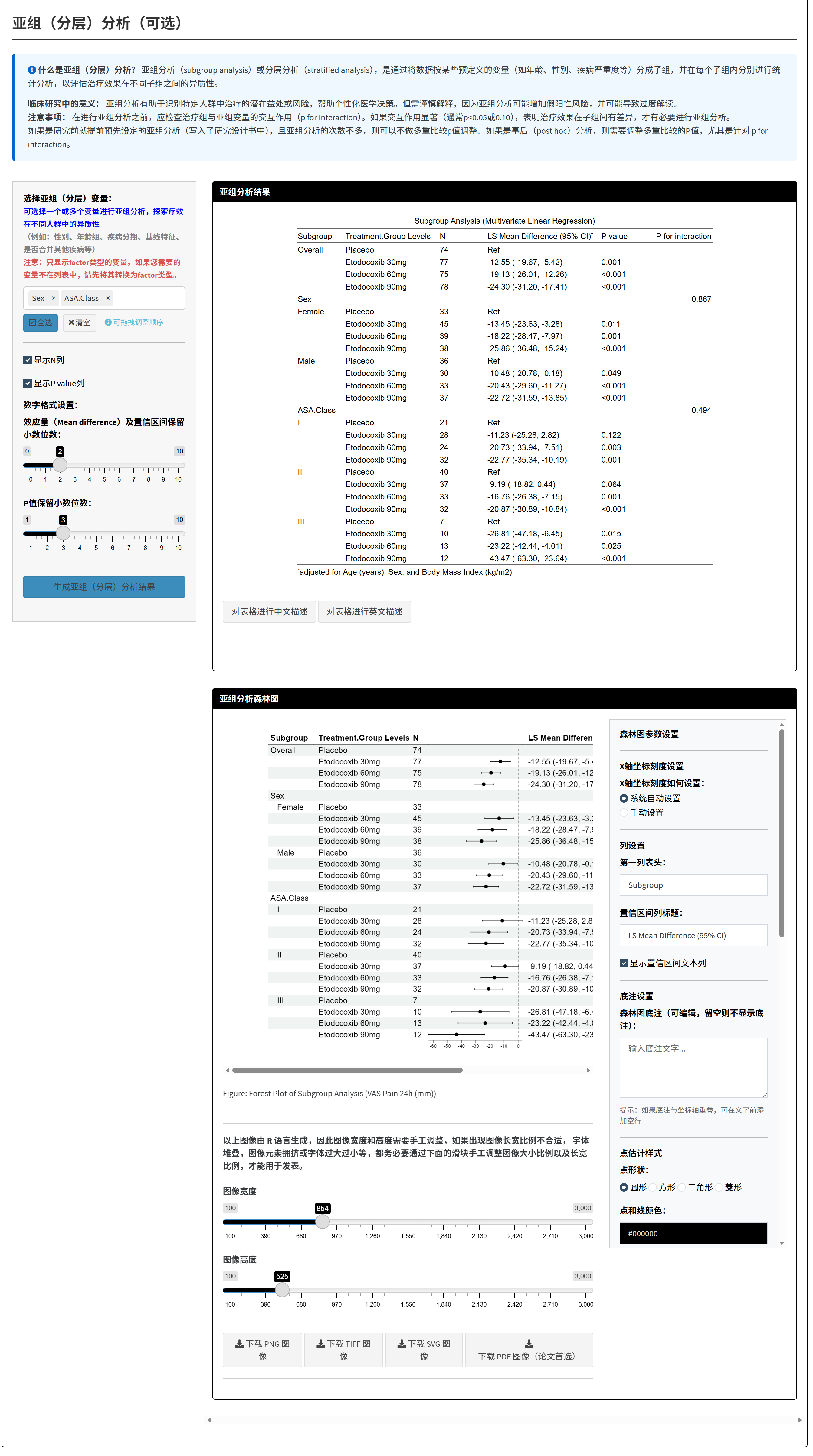
第四部分:下载Word报告或论文
这一部分用于生成完整的Word报告或论文模板,整合所有分析结果和图表。需在完成前述步骤后进行,确保数据和分析已就绪。报告分为英文版(适合国际期刊)和中文版(适合国内投稿),自动嵌入高清图表和表格。
操作步骤如下:
进入”下载Word报告或论文”标签:点击标签,界面显示信息收集表单。需逐项填写患者人群描述、各分组治疗方案、研究类型、主要终点等信息。
填写研究信息:
- 患者人群描述:输入研究对象(如”接受降糖治疗的2型糖尿病患者”)。
- 各分组治疗方案:为每个组别详细描述治疗方案(如”二甲双胍 500 mg 口服,每日两次”)。
- 研究类型:选择前瞻性或回顾性。
- 前瞻性研究类型(如适用):选择RCT或观察性研究。
- RCT盲法(如适用):选择双盲、单盲或开放标签。
- 主要终点:描述主要结局(如”治疗后24小时VAS疼痛评分”)。
- 确认数据质量:在下载前,需勾选三个确认项:
- 变量名使用有意义的英文单词(而非X1、X2)。
- 分类变量标签使用有意义的文字(而非0、1)。
- 已完成所有必要的统计分析步骤。
- 点击下载:完成所有填写和确认后,点击”下载英文论文”或”下载中文论文”按钮。系统处理5-10分钟(调用AI撰写背景、方法、结果、讨论等章节),生成DOCX文件。
报告内容包括标题、摘要、引言、方法(患者数据、入排标准、干预、统计)、结果(嵌入基线表、描述性统计表、比较结果表、森林图、亚组表等)、讨论,以及附录(ANOVA表、Emmeans表、敏感性分析等)。下载后,用Word打开检查内容,手动编辑补充细节。
特别说明:敏感性分析
如果您在疗效分析中选择了”多重填补(MI)“处理缺失值,系统会自动进行敏感性分析,即同时提供完整病例分析(CCA)的结果。这样可以比较MI和CCA的结果一致性,评估缺失值处理方法对结论的影响。敏感性分析结果将附加在报告的补充材料部分,包括:
- 敏感性分析 - 组间比较结果表(CCA)
- 敏感性分析 - 森林图(CCA)
- 补充表:敏感性分析 - ANOVA结果(CCA)
- 补充表:敏感性分析 - 估计边际均值(CCA)
原理:敏感性分析检验结果的稳健性。如果MI和CCA结果一致(方向和显著性相同),说明结论可靠;如果不一致,需谨慎解读,考虑缺失机制的影响。
注意事项:
- 本模块适用于治疗后一次测量的连续性结局变量,不适用于重复测量或纵向数据。
- 如果结局变量严重偏态(如高度右偏),建议进行对数转换或使用非参数方法(本模块暂不直接支持,可在数据准备阶段转换)。
- 亚组分析为探索性分析,需谨慎解读,避免过度挖掘数据导致假阳性。
- PSM仅支持两组比较,多组研究请使用多因素回归调整。
- 论文生成需要网络连接,调用AI检索文献和撰写内容,耗时较长,请耐心等待。
常见问题:
Q:我的结局变量是等级评分(如1-5分),可以用本模块吗?
A:可以。虽然等级数据严格来说是有序分类变量,但如果水平较多(如≥5个),通常可当作连续变量处理,使用本模块分析。如果水平较少(如3个),建议使用有序logistic回归(本软件其他模块可能支持)。
Q:我的数据缺失比较多,应该选择多重填补还是完整病例分析?
A:如果缺失率<20%且缺失机制为完全随机缺失(MCAR)或随机缺失(MAR),推荐多重填补,可减少偏差和保留样本量。如果缺失率很高(>30%)或缺失机制为非随机缺失(MNAR),两种方法都有局限性,建议咨询统计学家。
Q:亚组分析的交互P值不显著,是否可以报告各亚组的结果?
A:交互P值不显著表示没有证据支持疗效在亚组间有差异,此时应报告整体结果(全人群的MD),而非强调各亚组的结果。但如果有强烈的临床或生物学理由,可在讨论中谨慎提及亚组趋势,并强调需要进一步验证。
Q:我的研究有三个以上治疗组,可以做亚组分析吗?
A:本模块的亚组分析仅支持两组比较。如果您有三组以上,可以先在主疗效分析中完成多组比较,然后如需亚组分析,可选择其中两组(如对照组 vs 高剂量组)单独分析,或使用其他统计软件进行复杂的多组亚组分析。
Q:生成的论文初稿可以直接投稿吗?
A:不可以。论文初稿由AI辅助生成,提供了基本框架和内容,但需要您仔细检查和修改,包括:补充具体的医院名称、入排标准细节、随访时间等信息;核实AI检索的参考文献是否真实存在和相关;调整语言表达,使其符合目标期刊的风格;添加您的原创见解和临床意义解读。论文初稿是帮助您节省时间的工具,而非最终成品。
以上就是多臂疗效比较(连续性结局变量)模块的完整教程。祝您分析顺利,论文发表成功!
4.8 多臂疗效比较(结局为连续性变量,治疗前后各测量一次,如基线和治疗12周后空腹血糖值等)
功能: 本工具可以对两组或两组以上的患者进行治疗效果评价统计分析,支持连续性变量作为疗效结局,且在治疗前(基线)和治疗后各测量一次。
结局类型: 疗效结局为治疗前后两次测量的连续性变量,例如基线和治疗12周后的空腹血糖值、治疗前后的血压值、生物标志物水平变化等。
研究设计: 支持随机对照研究(RCT)或非随机分组研究;可以是前瞻性或回顾性研究;适用于干预性或观察性研究。
主要特点:
根据研究设计自动选择合适的统计方法,包括不调整、倾向性评分匹配(PSM)或多因素回归调整组间平衡。
支持宽表格式(每个患者一行,基线和治疗后为不同列)和长表格式(每次测量一行)两种数据结构。
自动计算治疗前后变化值(Change from Baseline)或变化百分比。
支持方差分析(ANOVA)、协方差分析(ANCOVA)、线性混合效应模型(LMM)等多种分析方法。
支持随机效应设置,适用于多中心研究等群组聚类数据。
提供缺失值处理方案:多重填补(Multiple Imputation)或完整病例分析(CCA)。
生成符合学术规范的高质量图表,包括趋势图和森林图,适合顶级医学杂志要求。
自动生成可重复的R代码,作为投稿证据。
操作简单,用户无需深厚统计知识即可完成分析。
分析过程中逐步引导用户理解临床研究设计和统计原理,使用后用户可掌握相关知识。
最终生成一篇论文初稿

一键自动生成以下图表和表格:
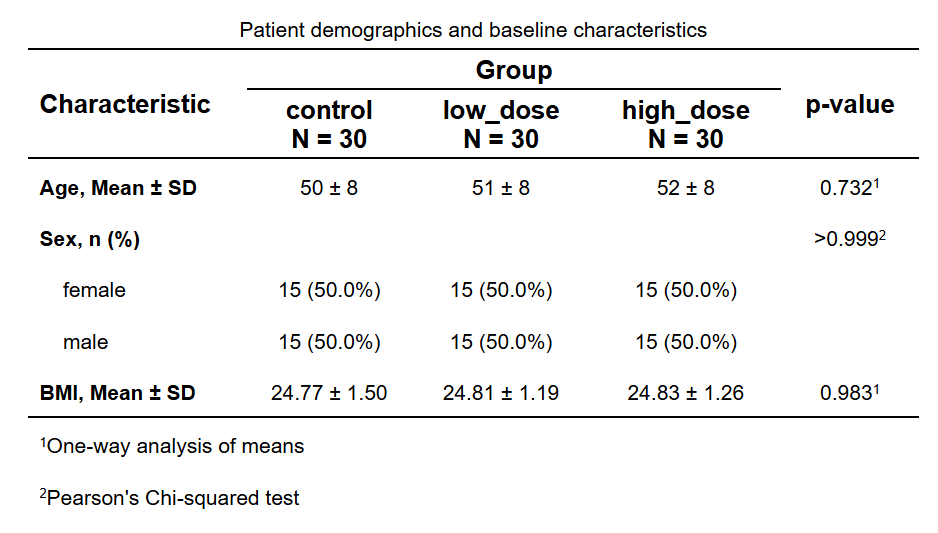
基线特征表(Table 1):展示各组的人口学和临床基线特征(仅宽表格式支持)。
PSM匹配前后SMD比较表和Love Plot:如选择PSM,展示匹配前后各变量的标准化均值差(仅宽表格式支持)。
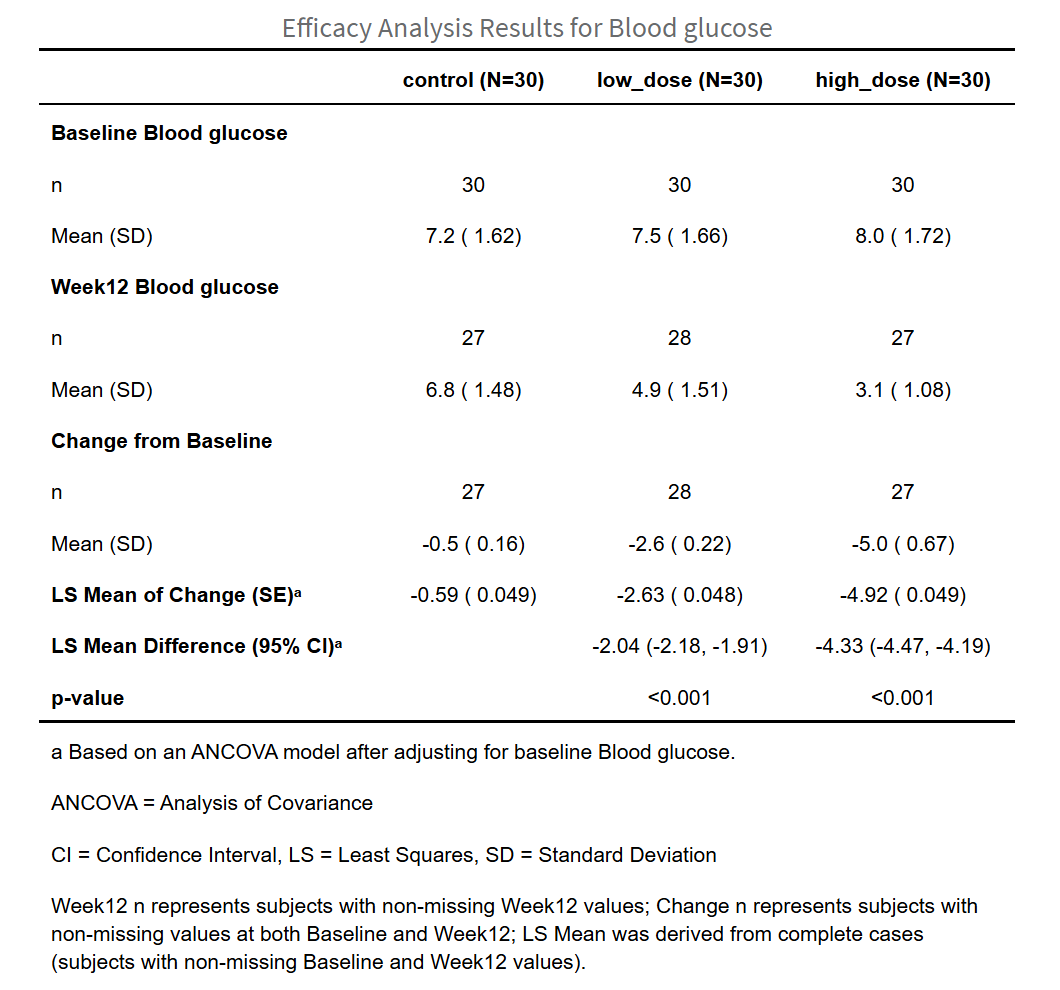
疗效分析结果表(Efficacy Analysis Results Table):将描述性统计和组间比较结果合并为一张综合表格,以临床试验标准格式呈现。表格以各治疗组为列(含各组样本量N),以统计指标为行,依次展示:基线n/均值±标准差、治疗后n/均值±标准差、变化值n/均值±标准差、变化值LS均值(标准误)、LS均值差(95%置信区间)及P值。
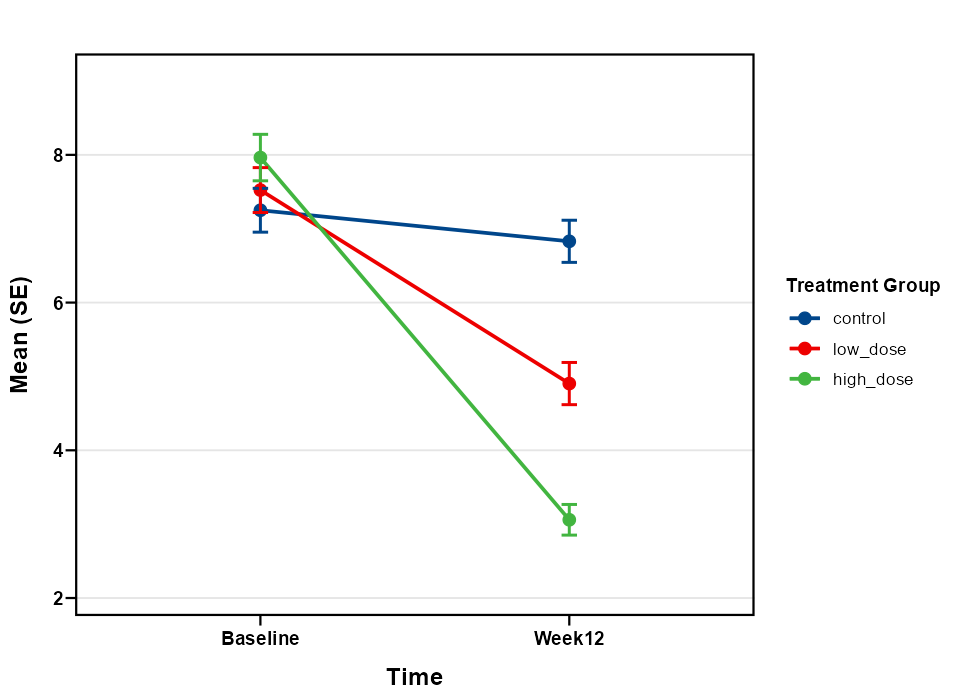
趋势图(Trend Plot):折线图展示各组从基线到治疗后的变化趋势。
森林图(Forest Plot):可视化各组的治疗效果及置信区间。

方差分析表和估计边际均值表(ANOVA & Emmeans Tables)
缺失值多重填补后结果(Multiple Imputation)
同上
R源代码自动生成作为投稿证据
4.8.1 基础知识
当疗效评价指标为连续性变量,且在治疗前(基线)和治疗后各测量一次时,使用本工具进行分析。
如何评价疗效?
本模块的核心是比较各治疗组在”治疗前后变化值”上的差异。常见的分析指标包括:
- Change from Baseline(CFB):治疗后值 - 基线值,反映绝对变化量。
- Percent Change from Baseline:(治疗后值 - 基线值) / 基线值 × 100%,反映相对变化。
通过比较各组的变化值,可以评估治疗的相对疗效。例如,如果治疗组的血糖值下降幅度大于对照组,说明治疗更有效。
组间基线平衡
对于随机对照研究(RCT),组间基线通常已平衡,无需额外调整。对于非随机分组研究(如回顾性或观察性研究),可能存在基线差异,可通过倾向性评分匹配(PSM)或多因素回归调整协变量(ANCOVA),以减少混杂影响。
为什么要调整基线值?
即使在随机对照研究中,各组的基线水平也可能存在轻微差异。通过协方差分析(ANCOVA)调整基线值,可以:
- 控制基线差异的影响,提高统计效能。
- 减少误差变异,使组间差异更容易检测。
- 符合ICH E9等临床试验统计指南的推荐。
统计方法选择
本工具提供以下分析方法:
- 协方差分析(ANCOVA):在模型中调整基线值和其他协变量,计算调整后的最小二乘均值(LS Mean)和组间差异。这是临床试验中最常用的方法。
- 方差分析(ANOVA):不调整任何协变量,直接比较各组的变化值均值。适用于基线已平衡的RCT。
- 线性混合效应模型(LMM):适用于包含群组聚类效应的数据(如多中心研究),通过随机效应(如中心、医院)处理数据非独立性。
缺失值处理
本工具支持两种缺失值处理策略:
- 多重填补(Multiple Imputation, MI):使用统计方法填补缺失值,保留更多样本,提高统计效能。
- 完整病例分析(Complete Case Analysis, CCA):剔除含有缺失值的样本,仅分析完整数据。
4.8.2 准备数据
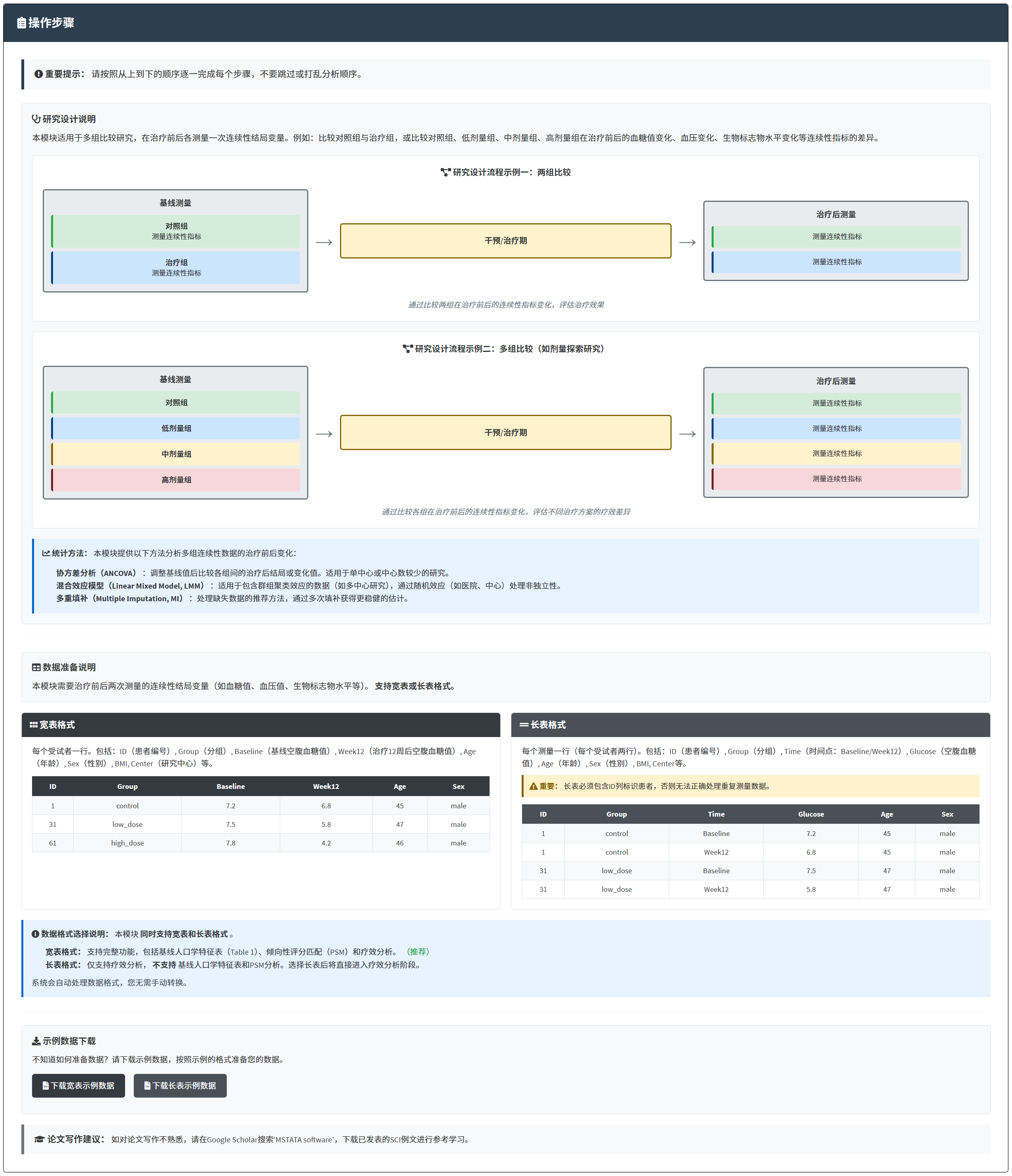
本模块支持两种数据格式:
宽表格式(Wide Format)
每个患者一行,基线和治疗后测量值分别作为不同的列。宽表格式支持完整功能,包括基线人口学特征表(Table 1)、倾向性评分匹配(PSM)和疗效分析。
数据结构示例:
| ID | Group | Baseline | Week12 | Age | Sex | BMI | Center |
|---|---|---|---|---|---|---|---|
| 1 | control | 7.2 | 6.8 | 45 | male | 24.5 | A |
| 2 | low_dose | 7.5 | 5.8 | 47 | male | 24.8 | A |
| 3 | high_dose | 7.8 | 4.2 | 46 | male | 25.1 | A |
长表格式(Long Format)
每次测量一行,同一患者有多行记录,通过ID变量关联。长表格式仅支持疗效分析,不支持基线人口学特征表和PSM分析。选择长表后将直接进入疗效分析阶段。
数据结构示例:
| ID | Group | Time | Glucose | Age | Sex | BMI | Center |
|---|---|---|---|---|---|---|---|
| 1 | control | Baseline | 7.2 | 45 | male | 24.5 | A |
| 1 | control | Week12 | 6.8 | 45 | male | 24.5 | A |
| 2 | low_dose | Baseline | 7.5 | 47 | male | 24.8 | A |
| 2 | low_dose | Week12 | 5.8 | 47 | male | 24.8 | A |
数据格式说明:
代表治疗分组的变量:例如Group,分成control、low_dose、high_dose等组。
代表疗效评价的连续性变量:
- 宽表:基线列(如Baseline)和治疗后列(如Week12),均为数值型。
- 长表:时间变量(如Time)标识测量时间点,数值变量(如Glucose)存储测量值。
基线人口学和临床特征:例如Age、Sex、BMI等,可用来调整协变量或做亚组分析。
随机效应变量(可选):如Center(中心),用于多中心研究的混合效应模型。
数据准备要点:
- 治疗分组变量必须是分类变量(factor型),且水平数不宜超过10个。
- 连续性结局变量必须是数值型(numeric),单位统一。
- 宽表格式中,每个患者只有一行;长表格式中,每个患者有多行(每个时间点一行)。
- 基线变量中,连续变量为数值型,分类变量为因子型。
- 缺失值:空白单元格或NA,系统可自动处理。
下载生成的样例数据,然后在样例数据的基础上修改成您自己的数据,就可以上传开始分析啦。
4.8.4 疗效比较分析
第一部分:研究设计设置
这一部分是整个分析流程的起点,主要目的是定义数据格式、研究的分组方式和处理组间潜在混杂的方法。通过这些设置,系统能够根据您的研究类型自动优化后续分析路径,确保结果的科学性和可靠性。
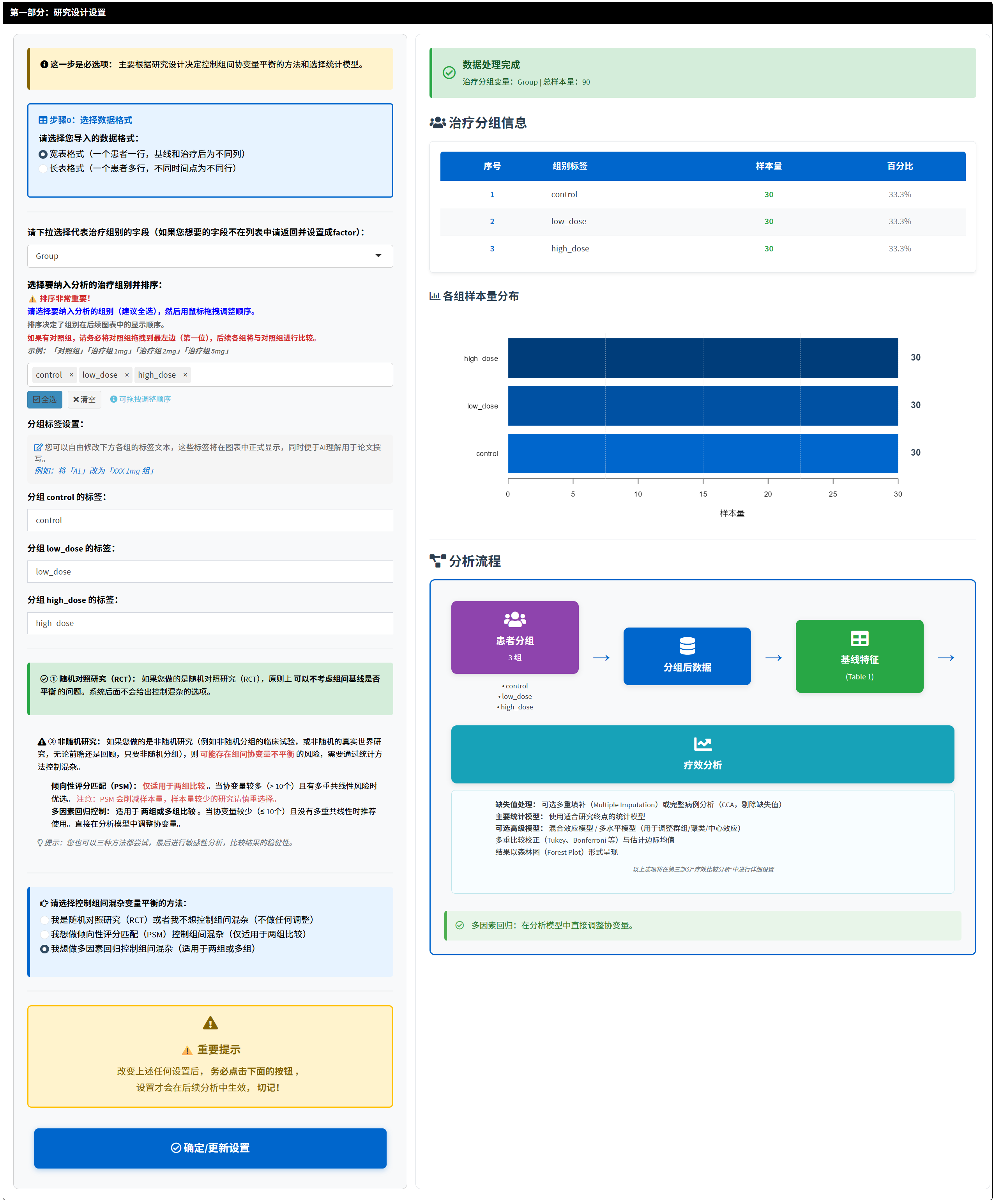
操作步骤如下:
选择数据格式:根据您的数据结构选择”宽表格式”或”长表格式”。
- 宽表格式:每个患者一行,基线和治疗后是不同的列。支持完整功能(Table 1、PSM、疗效分析)。
- 长表格式:每次测量一行,需要指定ID变量、时间变量和数值变量。仅支持疗效分析。
宽表格式变量设置:
- 选择代表治疗组别的变量(如Group)。
- 选择基线测量变量(如Baseline)。
- 选择治疗后测量变量(如Week12)。
长表格式变量设置:
- 选择ID变量(如ID),用于标识同一患者的多次测量。
- 选择时间变量(如Time),包含时间点标签。
- 选择数值变量(如Glucose),存储测量值。
- 选择代表治疗组别的变量(如Group)。
- 选择基线时间点(如Baseline)和治疗后时间点(如Week12)。
选择并排序分组水平:系统自动列出所有分组水平,您需要选择要纳入分析的组别(建议全选),然后用鼠标拖拽调整顺序。排序非常重要:第一个组别默认为参照组(对照组),后续各组将与参照组进行两两比较。例如,如果有四组(对照组、低剂量组、中剂量组、高剂量组),应将对照组拖拽到最左边(第一位),则分析将计算”低剂量 vs 对照”、“中剂量 vs 对照”、“高剂量 vs 对照”的差异。
设置分组标签:您可以为每个组别输入更有意义的标签(如”安慰剂对照组”、“XXX药物 1mg组”),这些标签将在图表中正式显示,便于理解和论文撰写。
选择控制组间混杂变量平衡的方法(仅宽表格式):根据您的研究设计,从三个选项中选择一个。系统会根据选择弹出相应界面。
随机对照研究(RCT)或不想控制组间混杂(不做任何调整):适用于随机分组的研究(如RCT),其中患者随机分配到各组,理论上基线特征已平衡,无需额外调整。原理:随机化确保组间差异仅由随机误差引起,而非系统偏差。选择此项,可生成基线特征表(Table 1),然后进入疗效分析。系统将采用单因素方差分析(ANOVA)。
倾向性评分匹配(PSM)控制组间混杂:适用于非随机分组的研究(如回顾性或观察性研究),仅支持两组比较。原理:PSM通过logistic回归计算每个患者的”倾向评分”(接受某种治疗的概率),然后匹配评分相似的患者,模拟随机化,减少选择偏差和混杂影响。优点:直观平衡基线,减少样本偏差;缺点:可能丢失样本(匹配失败的患者被剔除),且仅限两组。选择此项,进入第二部分进行PSM匹配设置。
多因素回归控制组间混杂:适用于非随机分组,支持两组以上。原理:在统计模型中同时纳入治疗变量和协变量,调整协变量的影响,计算调整后的均值差。优点:保留全部样本,处理多组和连续协变量;缺点:需满足模型假设(如无多重共线性),否则结果不可靠。选择此项,可生成基线特征表(Table 1),然后进入疗效分析,并在后续步骤选择协变量。系统将采用协方差分析(ANCOVA)。
- 确定/更新设置:完成上述选择后,务必点击”确定/更新设置”按钮,设置才会在后续分析中生效。点击后,系统会处理数据,并在右侧显示分组信息概要(包括各组样本量、百分比、条形图和分析流程图)。
第二部分:生成基线表或PSM(仅宽表格式)
这一部分根据第一部分的研究设计设置自动调整内容。如果您选择了长表格式,此部分将跳过,直接进入第三部分疗效分析。

如果您选择了宽表格式,则根据研究设计:
- 如果选择了随机对照研究(RCT)或多因素回归,系统会引导生成基线特征表(Table 1),用于描述组间人口学和临床特征的分布,帮助读者了解样本组成。
- 如果选择了倾向性评分匹配(PSM),则进入匹配流程,用于平衡非随机分组的基线差异。
此部分是可选的,如果您对基线平衡不感兴趣,可直接跳到第三部分。但生成基线表或进行PSM能提升结果的可信度,尤其在非随机研究中。
如果选择RCT或多因素回归(生成基线特征表):
操作步骤如下:
选择分组变量:系统自动使用第一部分选择的治疗组别变量作为分组依据(如Group)。
选择基线变量:从下拉菜单中多选需要展示的基线特征(如年龄、性别、基线血糖值等)。建议选择与研究相关的变量,至少2个。连续变量(如年龄)会自动识别为数值型,分类变量(如性别)为因子型。选择顺序决定表中变量的排列(从上到下)。
生成表格:点击生成按钮,系统自动计算并显示Table 1。表格包括:
- 每列代表一个组,展示均值±标准差(连续变量)或计数(百分比)(分类变量)。
- 可选显示组间P值(使用方差分析、Kruskal-Wallis检验或卡方/Fisher检验,根据变量类型和组数自动选择)。
- 对于RCT,建议不显示P值,因为随机化已确保平衡,P值比较可能误导。
原理:基线表描述样本特征,帮助评估组间相似性。在RCT中,任何差异均为随机;在非随机研究中,它揭示潜在混杂,为后续调整提供依据。
如果选择PSM(倾向性评分匹配):
操作步骤分四个子步骤。PSM仅支持二分类组别(两组),多组需分步处理或改用多因素回归。
基础设置:选择组别变量(必须为两组)和基线变量(至少2个需平衡的变量)。重要提示:不要将结局变量(基线疗效变量或治疗后疗效变量)放进PSM模型里去,只选择需要匹配的人口学协变量或基线水平的特征变量。 系统自动将人数多的组设为对照组,人少的为干预组。
缺失处理:选择剔除缺失或用KNN填补基线变量缺失值。
PSM匹配:选择方法(optimal、nearest等)、比例(1:1、1:2等)、卡钳值,点击开始匹配,生成SMD表和Love Plot。
匹配前后P值表(可选):生成匹配前后组间P值比较表。
完成此部分后,系统使用PSM匹配后的平衡数据进入第三部分疗效分析。
第三部分:疗效比较分析
这一部分是整个工具的核心,用于评估不同治疗组在治疗前后变化值上的疗效差异。系统采用方差分析(ANOVA)或协方差分析(ANCOVA)比较各组的变化值均值,计算调整后的均值差(LS Mean Difference 或 Marginal Mean Difference)及其置信区间,并通过趋势图和森林图可视化结果。
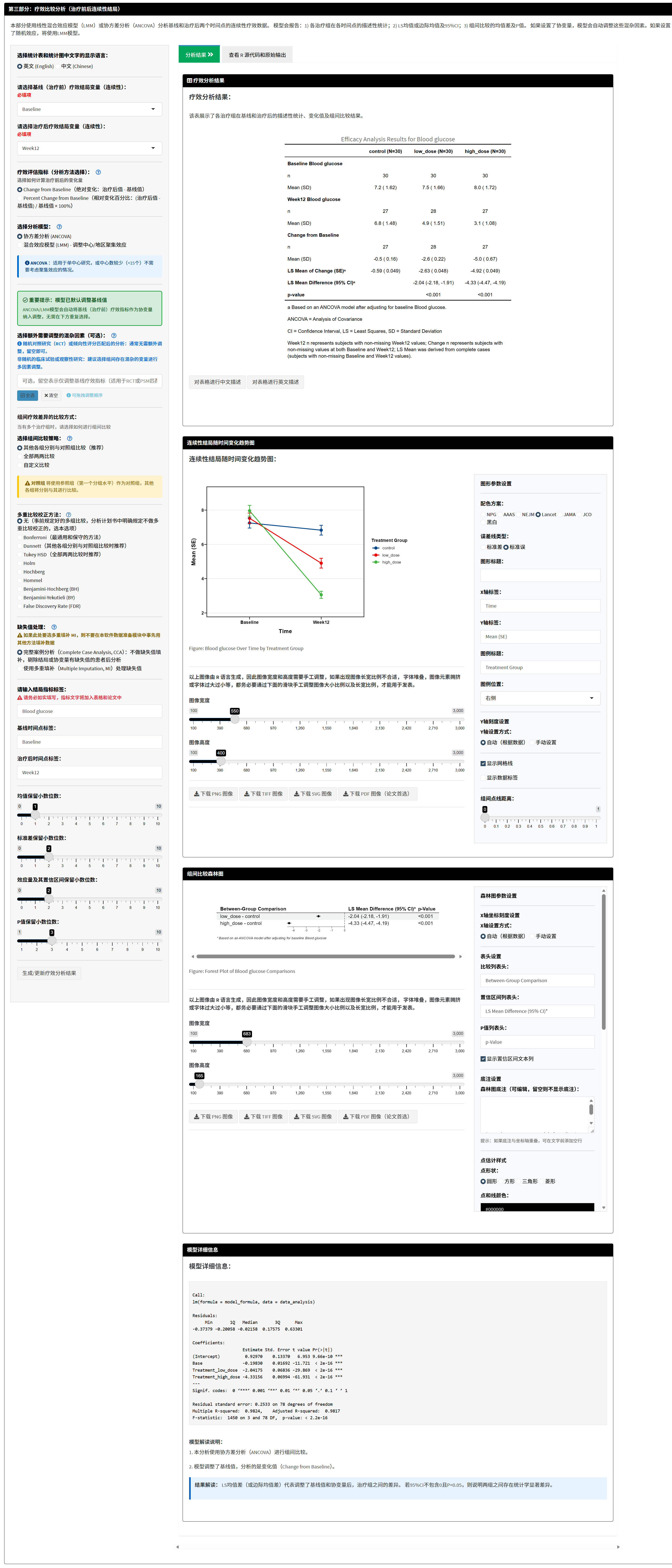 操作步骤如下:
操作步骤如下:
- 选择变化类型:
- Change from Baseline:计算绝对变化值(治疗后 - 基线)。
- Percent Change from Baseline:计算变化百分比。
- 选择缺失值处理方法:
- 多重填补(Multiple Imputation, MI):推荐方法。使用统计方法(如MICE算法)填补缺失值,保留更多样本,提高统计效能。系统默认进行5次填补,每次填补生成一个完整数据集,最后合并结果。优点:减少偏差,保留样本量;缺点:计算稍慢。
- 完整病例分析(Complete Case Analysis, CCA):剔除任何变量有缺失的样本,仅分析完整数据。优点:简单直观;缺点:可能丢失大量样本,导致偏差和效能降低。
- 如果选择了PSM,还可选择沿用PSM的缺失处理(使用匹配后的完整数据)。
原理:缺失值会影响统计推断。多重填补基于观测数据的分布填补缺失,避免简单剔除导致的样本量损失和偏差。
- 选择协变量(可选):如果第一部分选择了”多因素回归控制组间混杂”,会出现协变量选择框。多选需调整的基线特征(如年龄、性别等),但避免过多(一般不超过10个,以防过拟合)。注意:通常会将基线值自动作为协变量纳入ANCOVA模型,这是治疗前后对比分析的标准做法。
原理:协方差分析(ANCOVA)在模型中纳入协变量,调整其影响,计算调整后的均值差,控制混杂。
- 是否使用混合效应模型:如果您的数据包含群组聚类效应(如多中心研究、同一医院的患者可能更相似),可勾选”使用混合效应模型”,并选择随机效应变量(如医院、城市、Center)。
原理:混合效应模型通过随机效应处理数据非独立性,避免传统方差分析假设的违背,提供更可靠的推断。适用于多层次数据结构。
多重比较校正(可选):当有多个治疗组时,可选择多重比较校正方法(如Bonferroni、Tukey HSD、Dunnett等)。
点击生成结果:调整小数位(如均值1位、MD 2位、P值3位),点击”生成/更新疗效分析结果”。系统计算并显示:
主要结果表格:
疗效分析结果表(Efficacy Analysis Results Table):将描述性统计和组间比较结果合并为一张综合表格。表格以各治疗组为列(列头包含组名和总样本量N),以统计指标为行,包含以下内容:
- 基线(Baseline):各组基线的有效样本量n、均值±标准差。
- 治疗后(Endpoint):各组治疗后的有效样本量n、均值±标准差。
- 变化值(Change from Baseline):各组变化值的有效样本量n、均值±标准差。
- 变化值LS均值(LS Mean of Change):调整后的最小二乘均值及标准误(ANCOVA/LMM),或边际均值及标准误(ANOVA)。
- LS均值差(LS Mean Difference):各组与参照组的均值差及95%置信区间。如果调整了协变量,为调整后的LS Mean Difference(ANCOVA)或Marginal Mean Difference(混合模型);如果未调整协变量,则为Mean Difference。
- P值:组间比较的P值。
- 如果选择了多重比较校正,还会额外显示校正后的置信区间和P值。
如果使用多重填补(MI):表格标注”主要分析(多重填补,MI)“,基于Rubin’s rules合并m套填补数据的结果,标准误考虑了填补的不确定性。如果使用完整案例分析(CCA)或PSM后分析:标注”完整案例分析(CCA)“或”沿用PSM处理”,展示相应数据的分析结果。
趋势图(Trend Plot):折线图展示各组从基线到治疗后的变化趋势。可自定义颜色、线型、误差线类型等。
比较结果森林图(Forest Plot):可视化各组的均值差及置信区间。中轴线为0(无差异),线段不跨0表示显著差异。可通过右侧参数面板调整森林图外观。
附件表格:
ANOVA表(或混合效应模型结果):
- 传统ANOVA/ANCOVA:展示变异来源、自由度、F值、P值等统计量。
- 混合效应模型:展示固定效应系数表(包含变异来源、自由度、t值、P值等),以及模型summary输出(包括随机效应方差、残差方差等)。
Emmeans表:展示各组边际均值(estimated marginal means)、标准误、置信区间等。原理:边际均值是调整协变量后的模型预测均值,代表各组在协变量均值处的期望结局值。
如果使用了多重填补,附件表格标注”多重填补后…“;如果使用完整案例分析,标注”完整案例分析…“。
敏感性分析(仅在使用多重填补时显示):
如果您选择了多重填补(MI)作为主要分析,系统会自动进行敏感性分析,即额外提供完整案例分析(CCA)的结果。包括:
- 敏感性分析 - 疗效分析结果表(CCA)
- 敏感性分析 - 森林图(CCA)
- 敏感性分析附件表格:ANOVA表(CCA)、Emmeans表(CCA)、混合模型summary(CCA,如适用)
原理:敏感性分析检验结果的稳健性。如果MI和CCA结果一致(方向和显著性相同),说明结论可靠;如果不一致,需谨慎解读,考虑缺失机制的影响。
生成后,可用AI描述模块点击”用AI描述此表”获取结果段落草稿。
- 调整趋势图和森林图外观
趋势图参数:可自定义折线颜色、点形状、误差线类型(标准差或置信区间)、字体大小等。
森林图参数:森林图右侧有详细的参数控制面板,可自定义:
X轴坐标刻度设置:选择系统自动设置或手动设置(可输入下限、上限、刻度数值)。
列设置:修改第一列表头(如”Comparison”)、置信区间列标题(如”LS Mean Difference (95% CI)*“,星号表示调整了协变量)、P值列表头(如”P value”);选择是否显示置信区间文本列。
底注设置:编辑森林图底注文字。系统会根据是否调整协变量自动生成默认底注(如”* LS Mean Difference adjusted for: Baseline, Age, Sex”),您可修改。
点估计样式:选择点形状(圆形、方形、三角形、菱形)、点和线颜色、点大小。
线条设置:调整置信区间线宽、T型端点高度、线型(实线、虚线、点线)。
字体设置:调整基础字体大小、字体类型(无衬线、衬线、等宽)、X轴数字字体大小。
其他设置:选择是否添加表头线、设置表格底纹的两种颜色(交替显示)。
每次修改参数后,图形会自动更新。调整后的图形可下载(PNG、PDF、PPT格式)。
第四部分:查看R代码
系统自动生成完整的R分析代码,包括:
- 数据准备和格式转换(长表转宽表,如适用)
- 描述性统计计算
- 模型拟合(ANOVA/ANCOVA/LMM)
- 边际均值估计和组间比较
- 结果格式化
代码可复制用于:
- 论文投稿时作为方法学证据
- 在本地R环境重复分析
- 根据需要进行自定义修改
4.8.5 下载Word报告或论文
这一部分用于生成完整的Word报告或论文模板,整合所有分析结果和图表。需在完成前述步骤后进行,确保数据和分析已就绪。报告分为英文版(适合国际期刊)和中文版(适合国内投稿),自动嵌入高清图表和表格。
操作步骤如下:
进入”下载报告或论文”标签:点击标签,界面显示信息收集表单。需逐项填写患者人群描述、各分组治疗方案、研究类型、主要终点等信息。
填写研究信息:
- 患者人群描述:输入研究对象(如”接受降糖治疗的2型糖尿病患者”)。
- 各分组治疗方案:为每个组别详细描述治疗方案(如”二甲双胍 500 mg 口服,每日两次”)。
- 研究类型:选择前瞻性或回顾性。
- 前瞻性研究类型(如适用):选择RCT或观察性研究。
- RCT盲法(如适用):选择双盲、单盲或开放标签。
- 主要终点:描述主要结局(如”治疗前后空腹血糖值变化”)。
- 确认数据质量:在下载前,需勾选三个确认项:
- 变量名使用有意义的英文单词(而非X1、X2)。
- 分类变量标签使用有意义的文字(而非0、1)。
- 已完成所有必要的统计分析步骤(包括:设置分组、生成Table 1或完成PSM匹配、完成疗效比较分析等)。
- 点击下载:完成所有填写和确认后,点击”下载英文论文”或”下载中文论文”按钮。系统处理(调用AI撰写背景、方法、结果、讨论等章节),生成DOCX文件。
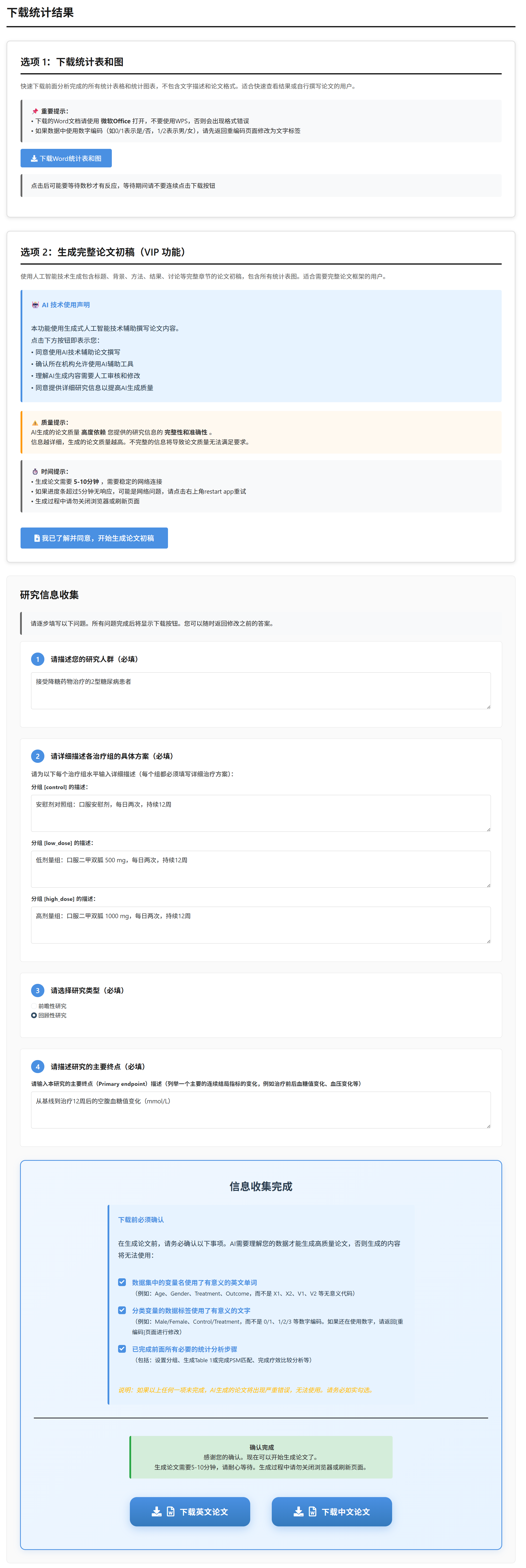
报告内容包括:
- 标题、摘要、引言
- 方法(患者数据、入排标准、干预措施、统计方法描述)
- 结果(嵌入基线表Table 1或PSM结果、疗效分析结果表、趋势图、森林图等)
- 讨论
- 附录(ANOVA表、Emmeans表、敏感性分析结果等)
下载后,用Word打开检查内容,手动编辑补充细节。
特别说明:
- 如果选择了PSM,报告中会包含PSM方法描述(如匹配方法、匹配比例等)和匹配结果表格。
- 如果使用了多重填补,报告会包含敏感性分析(完整案例分析)结果作为补充材料。
- 报告中的统计方法描述会根据您的设置自动生成(如是否调整协变量、是否使用混合效应模型等)。
4.8.6 结果解读
描述性统计表解读:
- 基线列:展示各组在治疗前的测量值分布,用于评估基线可比性。
- 治疗后列:展示各组在治疗后的测量值分布。
- 变化值列:展示各组的”治疗后-基线”变化,是疗效评价的核心。
- LS均值/边际均值:模型调整后的均值,考虑了协变量和基线值的影响。
组间比较表解读:
- 均值差(Mean Difference):观察组减去参照组的差值。负值表示观察组的变化更大(如血糖下降更多)。
- 95%置信区间:估计的不确定性范围。区间不包含0表示差异显著。
- P值:显著性检验结果。P<0.05通常认为有统计学显著差异。
趋势图解读:
- 折线展示各组从基线到治疗后的变化趋势。
- 误差线(标准差或置信区间)反映组内变异程度。
- 各组折线斜率的差异反映疗效差异。
森林图解读:
- 每条线段代表一个比较(如low_dose vs control)。
- 方块位置表示均值差点估计。
- 线段长度表示95%置信区间。
- 虚线(x=0)是无差异参考线。线段不跨越0表示显著差异。
4.8.7 常见问题
Q:我的数据是长表格式,可以生成Table 1和进行PSM吗?
A:不可以。长表格式仅支持疗效分析,不支持基线人口学特征表(Table 1)和倾向性评分匹配(PSM)。如果您需要这些功能,请将数据转换为宽表格式后再上传。
Q:我的数据是长表格式,系统如何处理?
A:系统会自动将长表转换为宽表进行分析。您只需正确指定ID变量、时间变量、数值变量和需要分析的时间点,系统会自动完成转换,并在生成的R代码中显示转换过程。
Q:ANCOVA和ANOVA有什么区别?
A:ANOVA仅比较各组变化值的均值,不调整任何协变量。ANCOVA在模型中纳入基线值和其他协变量,计算调整后的均值差。ANCOVA通常更有效,因为它控制了基线差异的影响,减少了误差变异。在治疗前后对比研究中,通常推荐使用ANCOVA并将基线值作为协变量。
Q:什么时候需要使用混合效应模型?
A:当数据存在群组聚类结构时(如多中心研究中同一中心的患者可能更相似),应使用混合效应模型。通过将中心作为随机效应,模型可以正确处理数据的非独立性,提供更可靠的推断。
Q:LS均值和边际均值有什么区别?
A:本质相同,只是术语不同。当使用ANCOVA时,输出称为”LS均值”(Least Squares Mean);当使用混合效应模型时,输出称为”边际均值”(Marginal Mean)。两者都是模型调整后的预测均值。
Q:如何选择多重比较校正方法?
A:常用方法包括:
- Bonferroni:最保守,适用于少量比较。
- Tukey HSD:适用于所有组间两两比较。
- Dunnett:适用于多个治疗组与单一对照组的比较(推荐)。
如果只有2-3组,可不校正;如果组数较多,建议使用Dunnett或Bonferroni校正。
Q:PSM进行匹配时,应该选择哪些变量?
A:选择可能影响治疗分配和结局的基线特征变量(如年龄、性别、疾病严重度等)。重要:不要将结局变量(基线疗效变量或治疗后疗效变量)放进PSM模型里去,只选择需要匹配的人口学协变量或基线水平的特征变量。
Q:我的数据缺失比较多,应该选择多重填补还是完整病例分析?
A:如果缺失率<20%且缺失机制为完全随机缺失(MCAR)或随机缺失(MAR),推荐多重填补,可减少偏差和保留样本量。如果缺失率很高(>30%)或缺失机制为非随机缺失(MNAR),两种方法都有局限性,建议咨询统计学家。
Q:生成的R代码可以直接在本地运行吗?
A:可以。代码使用标准的R包(dplyr、tidyr、emmeans、lmerTest等)。运行前需确保已安装相关包,并将数据对象赋值给
efficacy_continuous_pre_post_data变量。Q:生成的论文初稿可以直接投稿吗?
A:不可以。论文初稿由AI辅助生成,提供了基本框架和内容,但需要您仔细检查和修改,包括:补充具体的医院名称、入排标准细节、随访时间等信息;核实AI检索的参考文献是否真实存在和相关;调整语言表达,使其符合目标期刊的风格;添加您的原创见解和临床意义解读。论文初稿是帮助您节省时间的工具,而非最终成品。
注意事项:
- 本模块适用于治疗前后各测量一次的连续性结局变量。如果有多个时间点的重复测量,请使用”重复测量”模块。
- 如果结局变量严重偏态(如高度右偏),建议进行对数转换或使用非参数方法(本模块暂不直接支持,可在数据准备阶段转换)。
- PSM仅支持两组比较,多组研究请使用多因素回归调整。
- 混合效应模型需要足够的群组数量(通常≥5个)才能可靠估计随机效应。如果群组数太少,建议改用传统ANOVA/ANCOVA并将群组作为固定效应协变量。
- 论文生成需要网络连接,调用AI检索文献和撰写内容,耗时较长,请耐心等待。
以上就是多臂疗效比较(治疗前后测量的连续性结局变量)模块的完整教程。祝您分析顺利,论文发表成功!
4.9 多臂疗效比较(结局为生存资料,如OS/PFS/DFS等)
功能: 本工具可以对两组或两组以上的患者进行治疗效果评价统计分析,支持生存资料作为疗效结局。
结局类型: 疗效结局为生存资料,例如从研究开始到事件发生(如死亡)的时间。
研究设计: 支持随机对照研究(RCT)或非随机分组研究;可以是前瞻性或回顾性研究;适用于干预性或观察性研究。
主要特点:
根据研究设计自动选择合适的统计方法,包括不调整、倾向性评分匹配(PSM)或多因素回归调整组间平衡。
支持Kaplan-Meier生存曲线、生存率计算、中位生存期、Cox回归HR值等分析。
生成符合CONSORT规范的高质量图表,适合顶级医学杂志要求。
操作简单,用户无需深厚统计知识即可完成分析。
分析过程中逐步引导用户理解临床研究设计和统计原理,使用后用户可掌握相关知识。
最终生成一篇论文初稿
一键自动生成以下图表和表格:
- 基线特征表(Table 1)
- 生存率表(Table 2)
- 中位生存期表(Table 3)
- Cox回归HR表(Table 4)
- 生存曲线图
- 亚组分析表(Table 5)
- 亚组分析森林图
- PSM匹配前后SMD比较表和Love Plot
- 比例风险假设检验表和Schoenfeld残差图
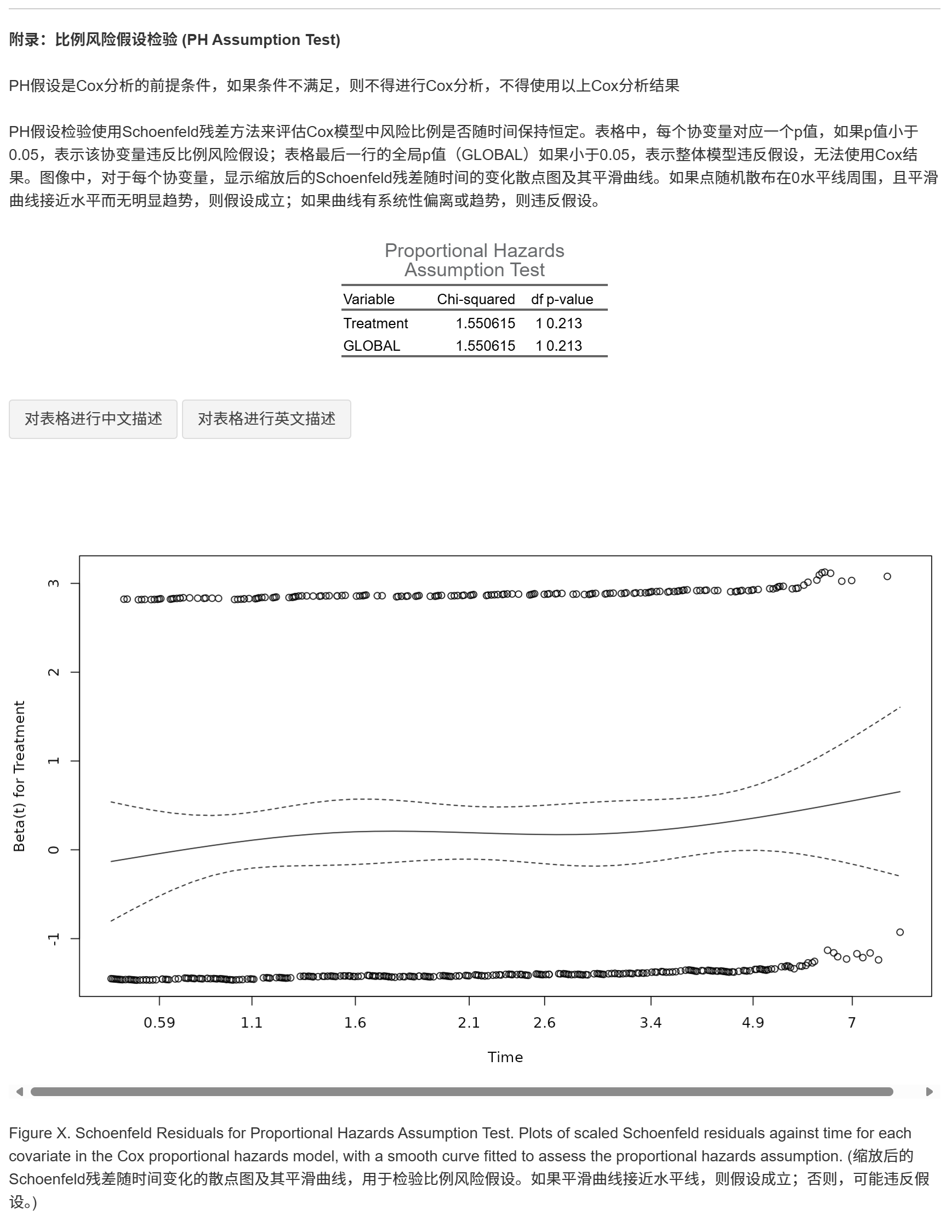
生成的图表概览:
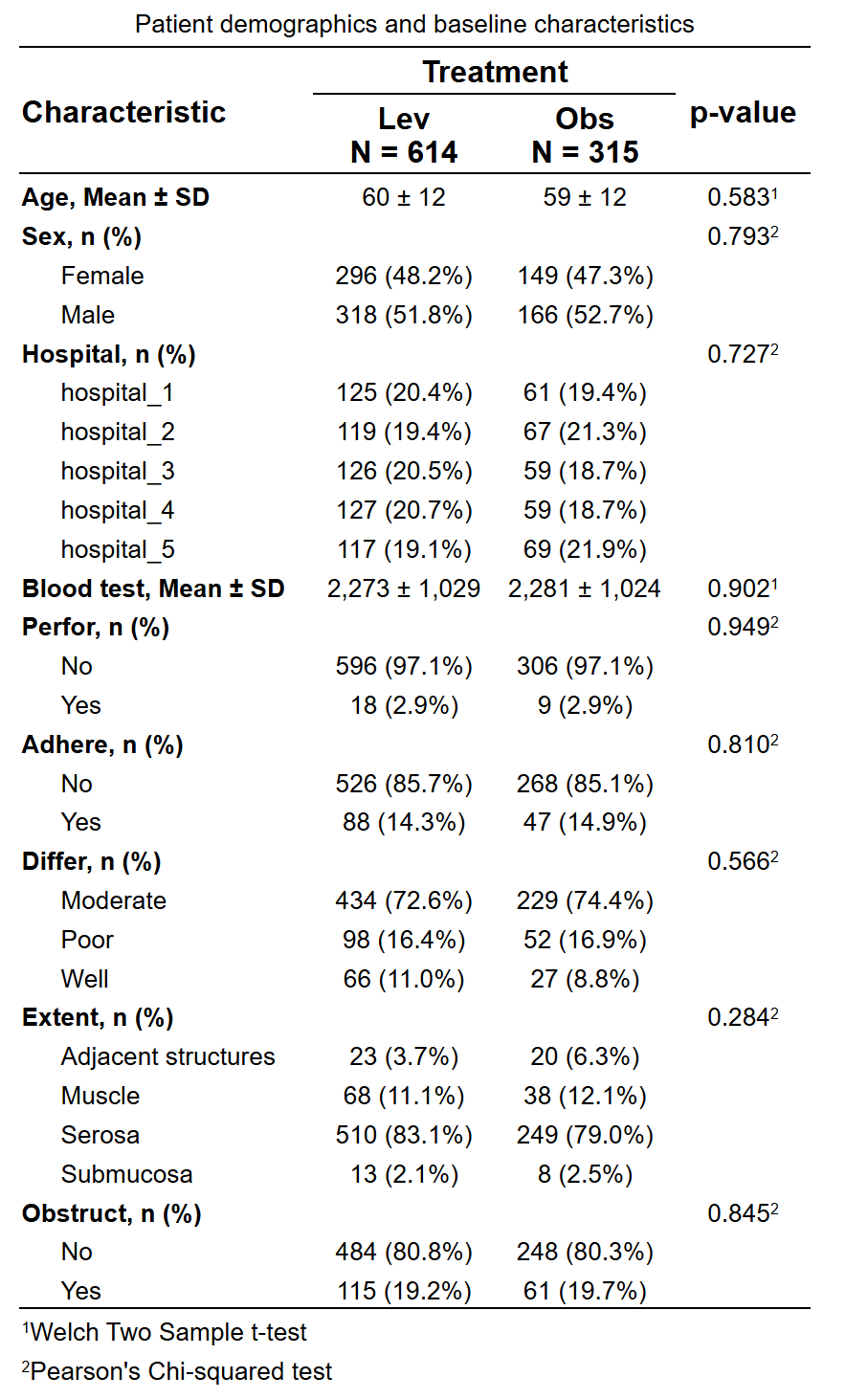
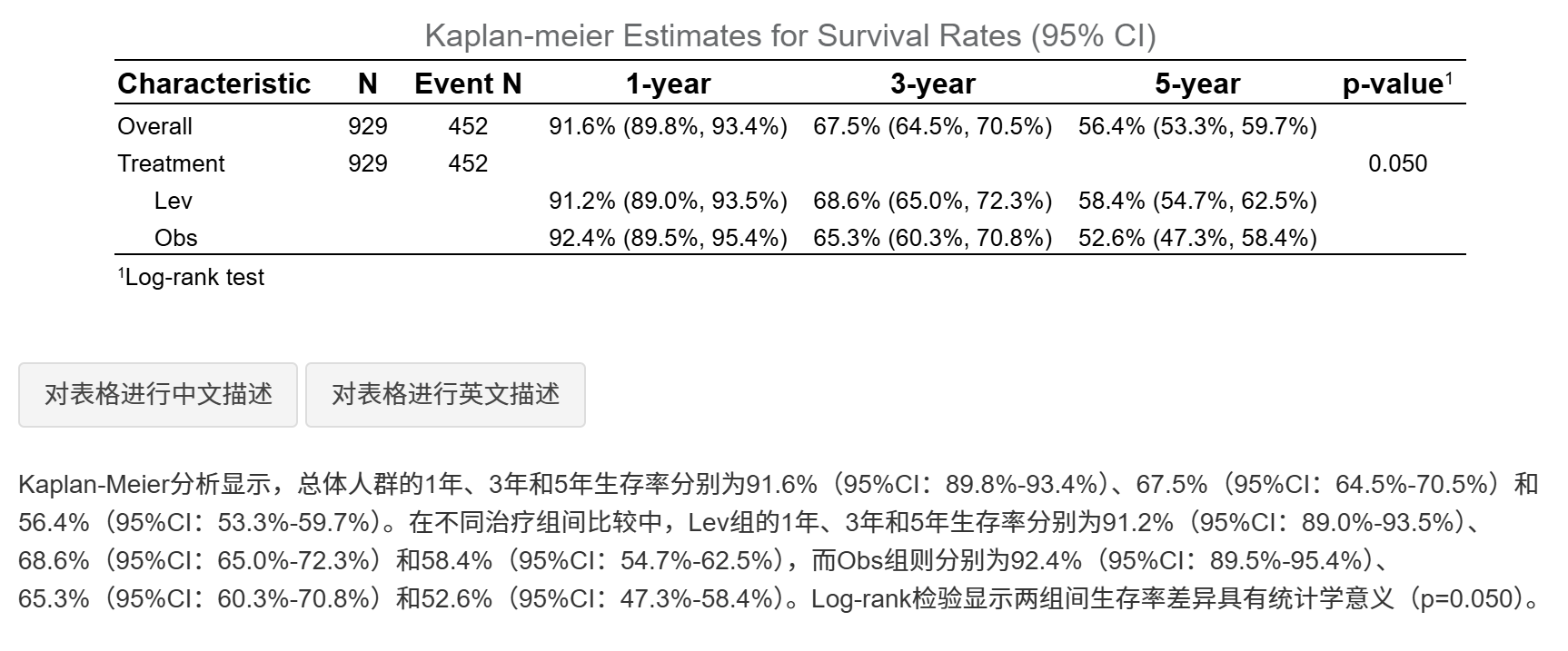

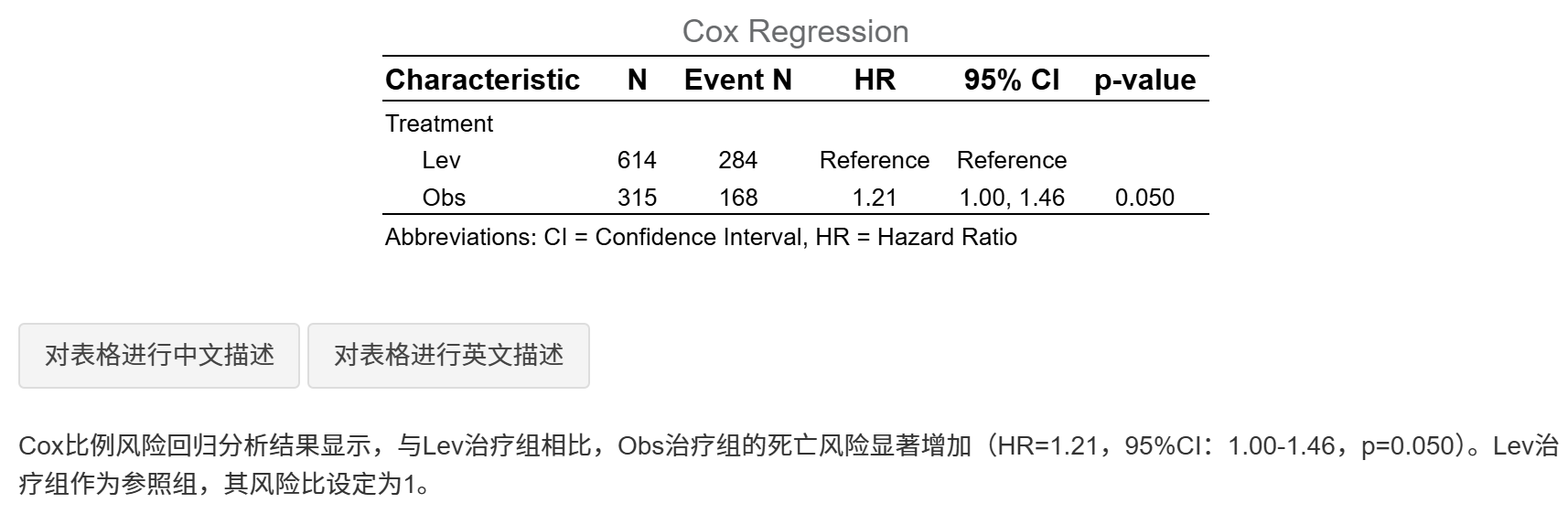
4.9.1 基础知识
当疗效评价指标为生存资料时,使用本工具进行分析。
如何评价疗效?
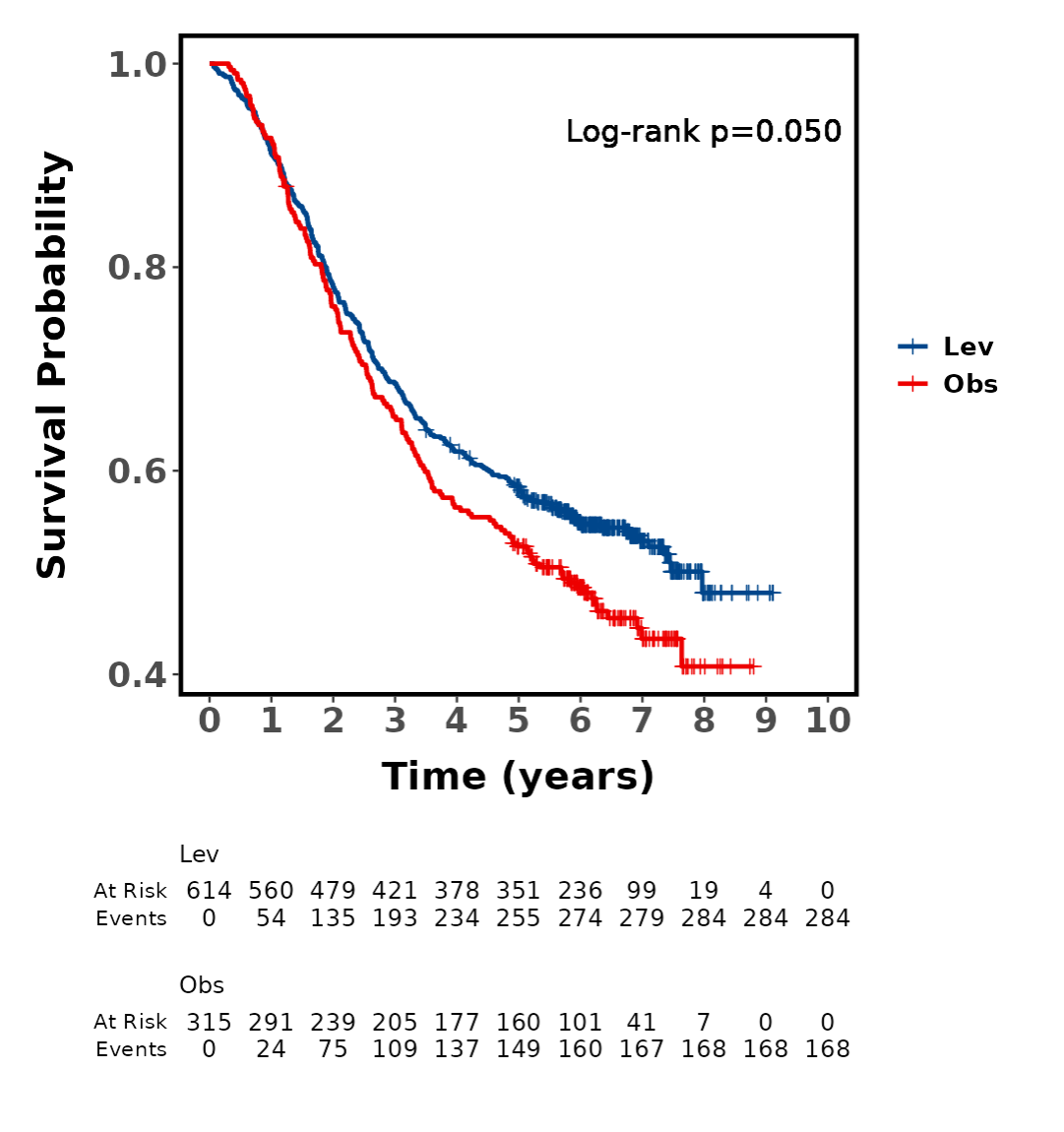
常见的生存资料疗效评价指标包括:特定时间点(如1年、3年、5年)的生存率;中位生存期;风险比(HR)及其置信区间;Log-rank检验P值等。
组间基线平衡
对于随机对照研究(RCT),组间基线通常已平衡,无需额外调整。对于非随机分组研究(如回顾性或观察性研究),可能存在基线差异,可通过倾向性评分匹配(PSM)或多因素回归调整协变量,以减少混杂影响。
比例风险假设(PH假设)
Cox回归的前提是风险比例随时间恒定。本工具提供PH假设检验,包括表格和Schoenfeld残差图。如果全局P值<0.05,假设不成立,建议改用分段Cox或时间依赖Cox模型。
4.9.2 准备数据
首先下载样例数据:
有三类变量:
代表治疗分组的变量:例如上图中的treatment, 分成了Lev、Obs和Lev+5FU三个组
代表疗效评价的变量:例如上图中的time和status
status代表患者在研究结束时的状态,在本工具中只能取0和1两个数字,不要用字符文本,否则会出错。0 代表没观察到事件发生(如没死或者失访),1 代表观察到了事件发生(如已经死亡且录入了死亡日期)。
time代表从开始日期(开始日期的定义由你的研究目的决定,如随机对照研究往往取随机化入组的那一天为开始日期,而观察性研究可以取首次诊断日期或首次治疗日期等等根据研究目的而定)到结局日期的时间差。当status=1时,结局日期为发生事件(如死亡)的日期,当status=0时,结局日期为最后一次活着的日期(如研究结束日,或随后一次随访日)。
总之,time是一个数值型变量,您需要填入患者从开始到死亡或者随后一次随访时,一共活着的天数。如time为56,status为1时代表患者从开始到死亡活了56天;当time为56,status为0时代表患者没观察到死亡,从开始到最后一次随访,活了56天。当然,time的单位也可以不是天,是月、年。软件在分析的时候可以做转换。
准备数据时,time填入一个非负的整数,status填入0或1,time和status都不能为空,每个患者都必须填入数字。time或status不确定(缺失)时,该患者最好不要放入本数据库。
- 基线人口学和临床特征:例如上图中的age、sex等等一系列指标,可用来调整组间平衡,也可用来做亚组分析
下载生成的样例数据,然后在样例数据的基础上修改成您自己的数据,就可以上传开始分析啦。
4.9.4 疗效比较分析
第一部分:研究设计设置
这一部分是整个分析流程的起点,主要目的是定义研究的分组方式和处理组间潜在混杂的方法。通过这些设置,系统能够根据您的研究类型自动优化后续分析路径,确保结果的科学性和可靠性。混杂(confounding)是指一些基线因素(如年龄、性别、疾病严重度)可能影响治疗组间的比较,导致观察到的疗效差异并非真正由治疗引起,而是受这些因素干扰。正确处理混杂是保证因果推断准确的关键。
操作步骤如下:
选择代表治疗组别的变量:从下拉菜单中选择表示分组的变量(如样例中的“treatment”)。这个变量必须是分类变量(factor型),代表不同治疗组(如组A用药物X,组B用药物Y)。系统支持两组或多组分析,但如果选择倾向性评分匹配(PSM),仅限两组。
接下来,选择参照组(reference group)。参照组是比较的基准,其他组将分别与参照组进行两两比较(1v1)。例如,如果有三组(A、B、C),选择A为参照组,则系统计算B vs A和C vs A的疗效差异。原理:参照组通常是标准治疗组或对照组,便于突出新治疗的相对优势。这种两两比较避免多组同时比较时的复杂性,确保结果清晰可解释。
选择控制组间混杂变量平衡的方法:根据您的研究设计,从三个选项中选择一个。系统会根据选择弹出相应界面。
随机对照研究(RCT)或不想控制组间混杂(不做任何调整):适用于随机分组的研究(如RCT),其中患者随机分配到各组,理论上基线特征已平衡,无需额外调整。原理:随机化确保组间差异仅由随机误差引起,而非系统偏差。根据CONSORT指南,在RCT中不推荐基线P值比较,因为它可能误导(参考:Harvey LA. Spinal Cord. 2018;56:919. doi:10.1038/s41393-018-0203-y)。选择此项,直接进入疗效分析,无需平衡步骤。
倾向性评分匹配(PSM)控制组间混杂:适用于非随机分组的研究(如回顾性或观察性研究),仅支持两组。原理:PSM通过logistic回归计算每个患者的“倾向评分”(接受某种治疗的概率),然后匹配评分相似的患者,模拟随机化,减少选择偏差和混杂影响。优点:直观平衡基线,减少样本偏差;缺点:可能丢失样本(匹配失败的患者被剔除),且仅限两组(多组PSM计算复杂)。选择此项,进入第二部分进行匹配细节设置。
多因素回归控制组间混杂:适用于非随机分组,支持两组以上。原理:通过Cox回归模型同时纳入治疗变量和协变量,调整协变量的影响,计算调整后的HR值。优点:保留全部样本,处理多组和连续协变量;缺点:需满足模型假设(如无多重共线性,事件数/协变量数≥10),否则结果不可靠。选择此项,直接进入疗效分析,并在后续步骤选择协变量。
- 如果选择PSM,系统引导进入第二部分(匹配过程);否则,直接进入第三部分(疗效分析)。建议根据样本量和协变量数量选择:协变量多(>10)或存在共线性时,优先PSM;样本小或协变量少时,优先多因素回归。三种方法可分别尝试,做敏感性分析比较结果稳健性。

第二部分:生成基线表或PSM(可选)
这一部分根据第一部分的研究设计设置自动调整内容。如果您选择了随机对照研究(RCT)或不调整混杂(或多因素回归),系统会引导生成基线特征表(Table 1),用于描述组间人口学和临床特征的分布,帮助读者了解样本组成,并初步检查组间是否平衡(尽管在RCT中不推荐P值比较)。如果选择了倾向性评分匹配(PSM),则进入匹配流程,用于平衡非随机分组的基线差异,模拟随机化效果,减少混杂偏倚。PSM的原理是计算每个患者接受某种治疗的“倾向性”(基于基线因素的概率),然后匹配相似倾向的患者,确保组间可比性,从而更可靠地评估治疗效果。PSM特别适用于回顾性或观察性研究,但会减少样本量(未匹配患者被剔除),需权衡。
此部分是可选的,如果您对基线平衡不感兴趣,可直接跳到第三部分。但生成基线表或进行PSM能提升结果的可信度,尤其在非随机研究中。
如果选择RCT或多因素回归(生成基线特征表):
操作步骤如下:
选择分组变量:系统自动使用第一部分选择的治疗组别变量作为分组依据(如treatment)。这确保表按组别分列显示。
选择基线变量:从下拉菜单中多选需要展示的基线特征(如年龄、性别、血压等)。建议选择与研究相关的变量,至少2个。连续变量(如年龄)会自动识别为数值型,分类变量(如性别)为因子型。选择顺序决定表中变量的排列(从上到下)。
生成表格:点击生成按钮,系统自动计算并显示Table 1。表格包括:
每列代表一个组,展示均值±标准差(连续变量)或计数(百分比)(分类变量)。
可选显示组间P值(使用t检验、Wilcoxon检验或卡方/Fisher检验,根据变量类型自动选择)。
对于RCT,建议不显示P值,因为随机化已确保平衡,P值比较可能误导(基于统计共识,如Nature指南)。
原理:基线表描述样本特征,帮助评估组间相似性。在RCT中,任何差异均为随机;在非随机研究中,它揭示潜在混杂,为后续调整提供依据。表格使用gtsummary包标准化输出,确保专业格式。
调整选项:可修改小数位、统计方法(如参数 vs 非参数),重新生成直到满意。

如果选择PSM(倾向性评分匹配):
操作步骤如下,分四个子步骤。PSM仅支持二分类组别(两组),多组需分步处理。
- 基础设置:
选择组别变量:从下拉菜单选择二分类组别变量(如treatment,只能有两个取值)。系统自动将人数多的组设为对照组,人少的为干预组(符合PSM原则,避免过度丢失干预组样本)。
选择基线变量:多选至少2个需平衡的变量(如年龄、性别)。分类变量水平<30,避免高维度变量(如ID号)导致匹配失败。顺序影响后续表排列。
原理:这些变量用于计算倾向评分(logistic回归模型),量化患者“倾向”于某组的概率。选择过多变量可能导致过匹配或计算缓慢;过多水平变量会增加维度灾难。
- 缺失处理:
选择方式:剔除任何组别或基线变量缺失的患者,或仅对基线变量用KNN(k-最近邻)填补(组别缺失必剔除)。
如果选择KNN,设置k值(建议1-10,小样本用小k避免找不到邻居报错)。
点击处理,查看原始和填补后数据(可下载)。
原理:缺失值会偏倚匹配。KNN基于相似患者填补(最近文献推荐用于PSM,如Statistical Methods in Medical Research),保留更多样本。结局变量不填补,以免引入偏倚。
- PSM匹配:
选择方法:如optimal(最优配对,优化总距离)、nearest(最近邻,逐个匹配)、genetic(遗传算法优化)、exact(精确匹配)等。样本大(>2000)很慢,避免慢速方法。
比例(1:N):设置N值(上限基于组间人数比),如1:1平衡样本,1:2保留更多对照。
卡钳值(caliper):输入如0.1(>1个变量时启用),限制匹配范围(小值精度高但样本损失大)。
点击开始匹配,生成:
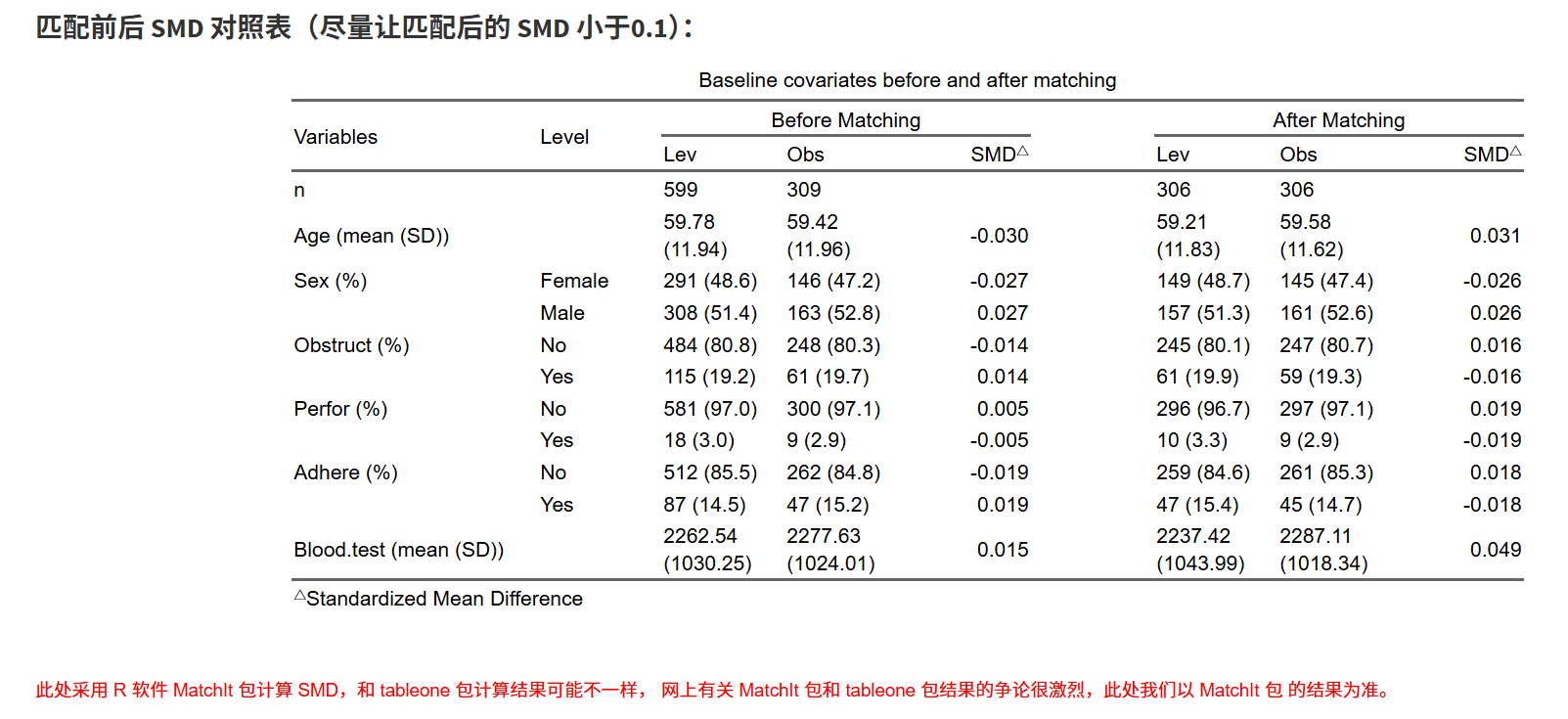
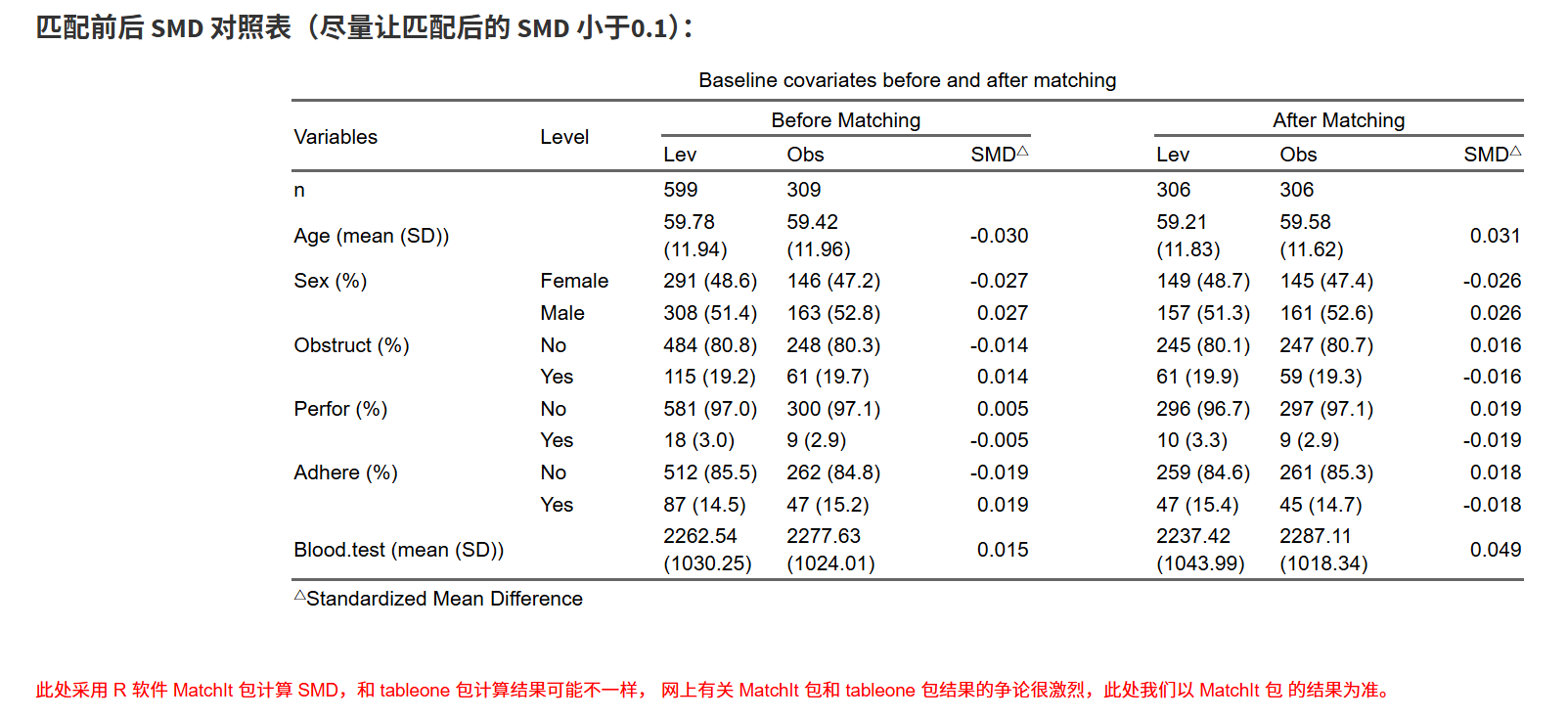
匹配前后SMD表:SMD<0.1表示平衡好(标准化均值差,优于P值)。
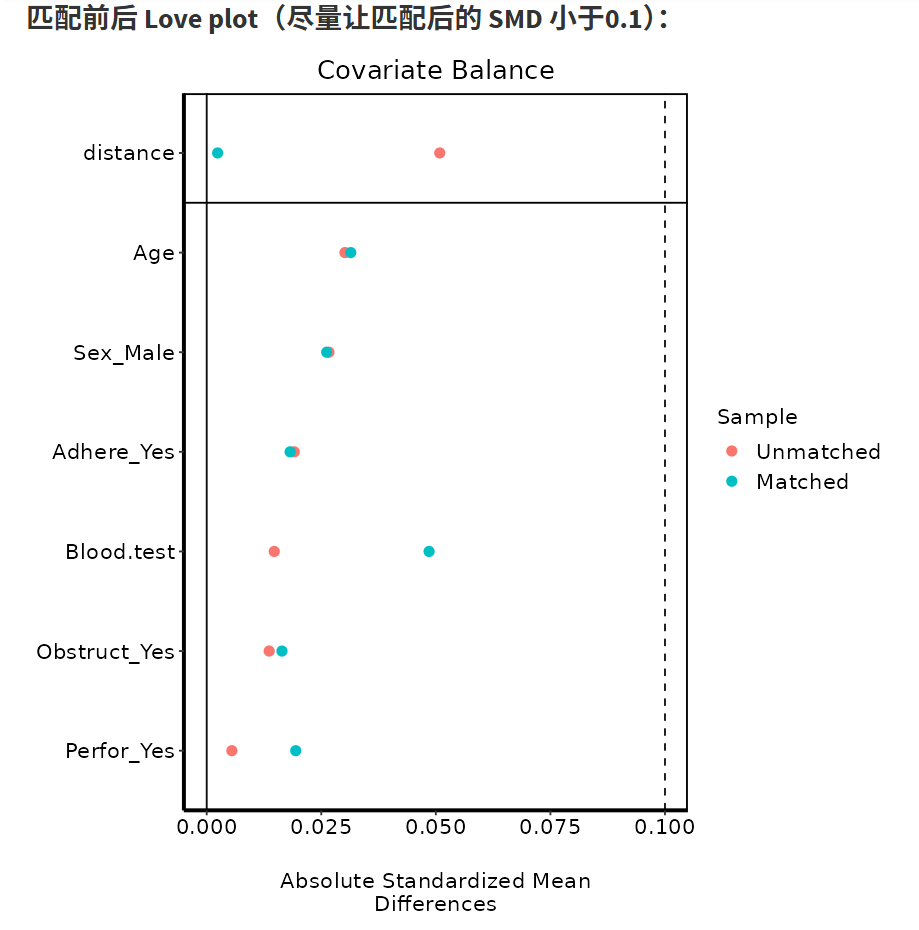
Love Plot:可视化SMD变化(点越靠近0线越好)。
调整图像大小/字体,直到清晰。
原理:PSM模拟随机化,匹配相似评分患者(MatchIt包实现)。方法差异:optimal全局优化;nearest局部贪婪;caliper控制精度,避免不佳匹配。迭代调整参数,直到SMD满意。
- 匹配前后P值表(可选):
选择连续变量统计(如均值±SD vs 中位数IQR)和检验方法(参数 vs 非参数,可查看QQ图判断正态性)。
设置小数位,生成表显示匹配前后组间P值。
原理:P值表补充SMD,展示平衡(P>0.05表示无显著差异),但SMD更可靠(P值受样本量影响)。旧文献常用P值,但现代指南优先SMD。
完成此部分后,系统使用平衡数据进入第三部分疗效分析。如果不满意,调整参数重新匹配。

第三部分:疗效比较分析
这一部分是整个工具的核心,用于评估不同治疗组的疗效差异。疗效结局为生存资料时,分析焦点在于时间事件数据(如从治疗开始到死亡或失访的时间)。系统采用Kaplan-Meier方法估计生存概率和中位生存期,使用Log-rank检验比较组间曲线差异,并通过Cox比例风险模型计算风险比(HR),评估治疗效果的大小。如果选择了多因素回归,还会调整协变量以控制混杂。整个分析基于生存分析原理:考虑删失数据(censoring,如患者失访或研究结束未发生事件),避免简单均值比较的偏差。Kaplan-Meier是非参数方法,适合描述性分析;Cox模型是半参数方法,允许调整协变量,但需满足比例风险(PH)假设(风险比随时间恒定)。如果PH不成立,结果不可靠,需改用其他模型。
操作步骤如下:
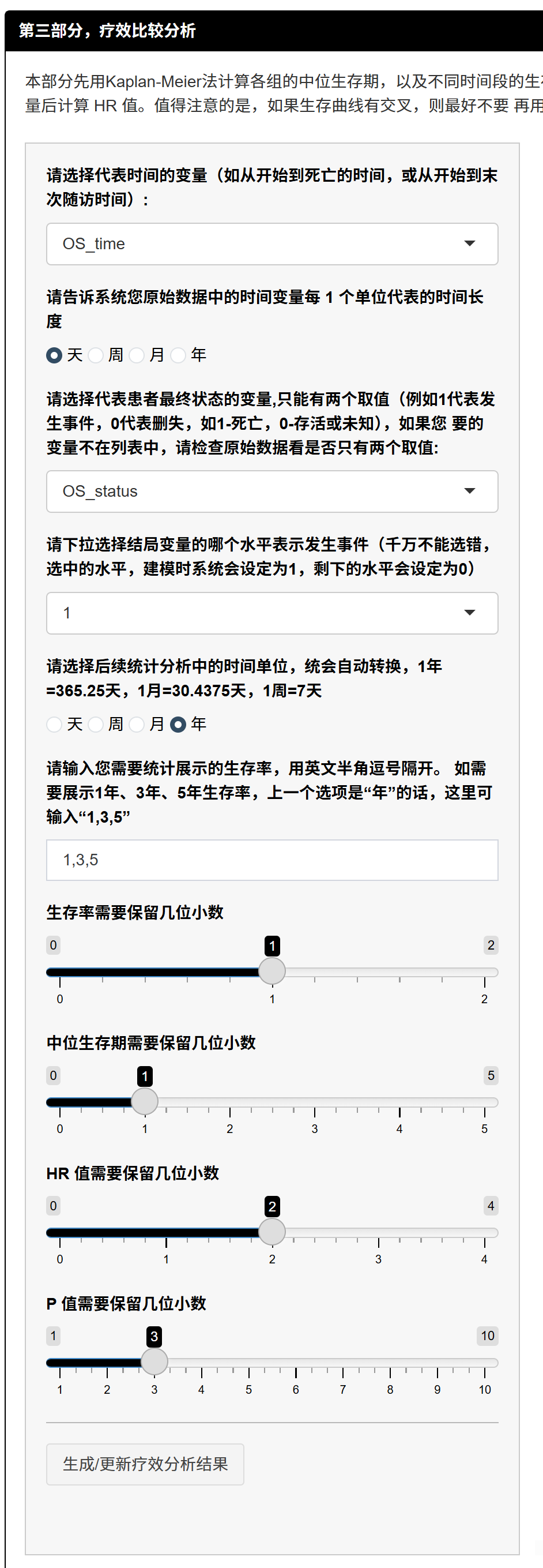
- 选择时间变量和单位:从下拉菜单选择代表生存时间的变量(如样例中的time),这是一个数值型变量,表示从研究起点(如入组日)到事件发生或最后随访的天数、周数等。接着,选择原始数据的单位(如“天”),告知系统每个单位的时间长度(例如,time=365代表365天)。
原理:时间变量是生存分析的基础,用于计算生存函数。单位选择确保系统正确转换数据(如天转年),避免计算错误。数据必须非负且无缺失,否则影响准确性。
- 选择状态变量和事件水平:从下拉菜单选择代表患者结局状态的变量(如status),这是一个二分类数值变量(仅0和1)。然后,选择哪个水平表示“事件发生”(如1代表死亡或复发,0代表存活或删失)。确保变量只有两个取值,否则不在菜单中出现。
原理:状态变量处理删失数据(censoring),0表示未观察到事件(右删失),1表示观察到事件。这允许分析包含不完整观察的患者,提高估计的鲁棒性。选错事件水平会导致模型反转(例如,将存活误为事件)。
- 选择分析时间单位和生存率时间点:选择后续统计(如生存率、曲线)的单位(如“年”),系统自动转换(例如,1年=365.25天)。然后,在文本框输入需要展示的生存率时间点,用逗号分隔(如“1,3,5”代表1年、3年、5年生存率)。
原理:单位转换统一分析尺度,便于临床解读。时间点基于Kaplan-Meier估计特定时点的生存概率(S(t)),帮助评估长期疗效,如肿瘤研究的5年生存率。
- 如果选择多因素回归,选择协变量(可选):如果第一部分选择了“多因素回归控制组间混杂”,会出现协变量选择框。多选需调整的基线特征(如年龄、性别),但避免过多(一般不超过事件数/10,以防过拟合)。协变量缺失需事先填补,否则患者被剔除导致样本减少。分类变量水平>20(如ID号)不可选。
原理:多因素Cox模型调整协变量影响,计算调整后HR,控制混杂(例如,年龄大组可能疗效差,但非治疗原因)。Ten events per variable (EPV)规则确保模型稳定(尽管有争议)。变量筛选可避免多重共线性(协变量间相关)。
- 点击生成结果:调整小数位(如生存率1位、HR 2位、P值3位),点击“生成/更新疗效分析结果”。系统计算并显示:
生存率表(Table 2):展示整体和各组在指定时间点的生存率及95%置信区间(CI),组间Log-rank P值。原理:Kaplan-Meier逐事件更新生存概率,CI反映不确定性;Log-rank检验非参数比较曲线差异。
中位生存期表(Table 3):整体和各组中位生存时间及CI(生存概率=0.5的时间点)。原理:从Kaplan-Meier曲线插值,若未达0.5则显示NA。
Cox回归HR表(Table 4):单因素(未调整)和多因素(调整协变量)HR、CI和P值。HR<1表示治疗组风险低(更好疗效)。原理:Cox模型估计相对风险,调整协变量后HR更可靠。
PH假设检验表和Schoenfeld残差图(附录):表格显示每个协变量和全局P值(<0.05表示违反PH);图显示残差随时间散点及平滑曲线(水平线表示假设成立)。原理:基于Schoenfeld残差检验风险比例恒定;违反时,HR不适用,建议分段或时间依赖模型。
生成后,可用AI描述模块点击“用AI描述此表”获取结果段落草稿。
- 生成并调整生存曲线:点击“生成生存曲线”,显示Kaplan-Meier曲线。调整外观:宽度/高度(像素,确保不扭曲)、风险表高度比例、颜色、字体、置信区间、P值位置等。风险表显示各时点风险人数。
原理:曲线可视化生存概率随时间下降,组间分离表示差异(Log-rank P值量化)。风险表显示删失影响(人数减少)。调整确保图美观、高清,适合出版。
结果可迭代更新(如改时间点),确保PH假设成立再解读。

4.9.5 亚组分析
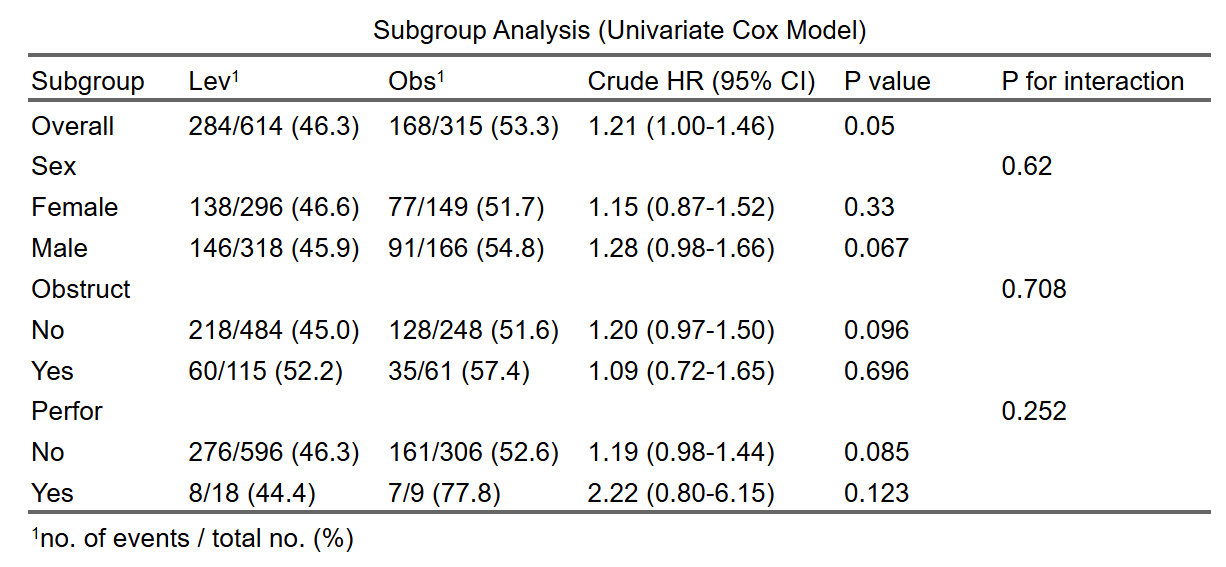
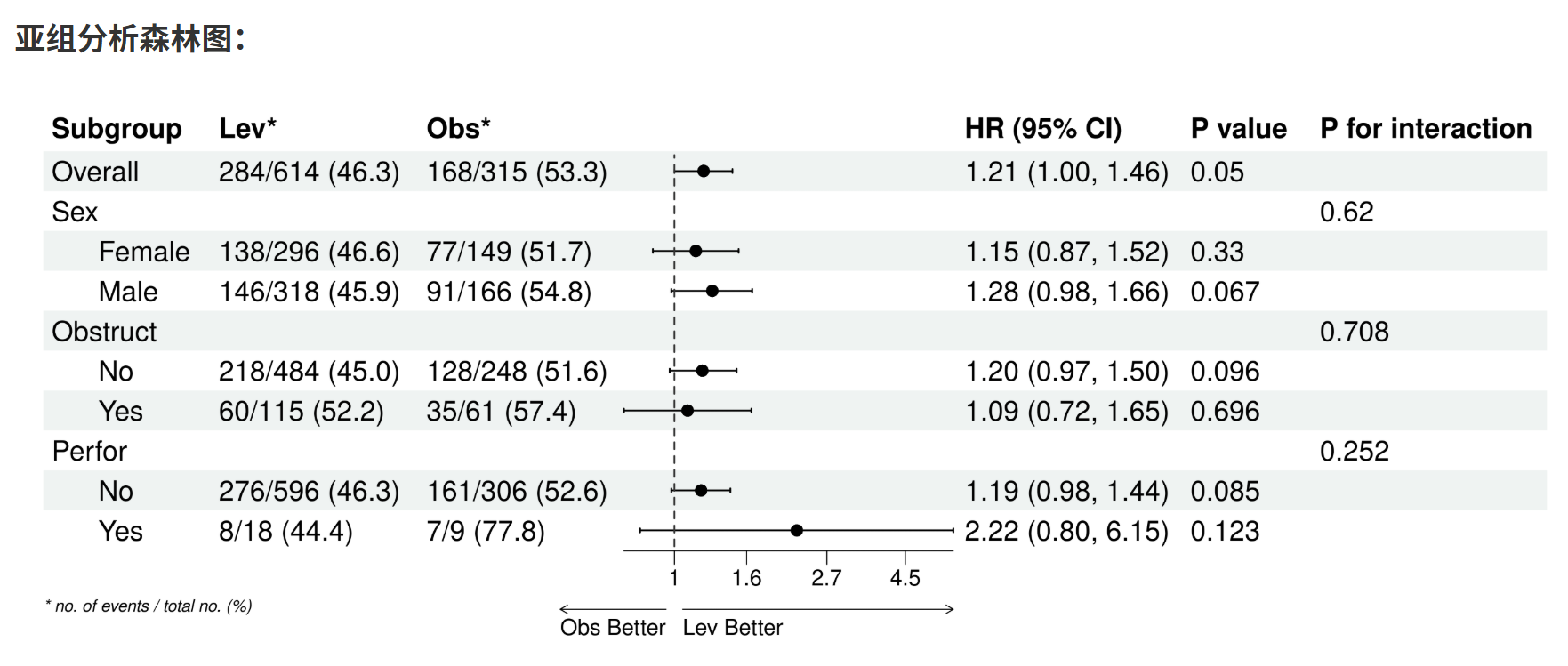
亚组分析是主疗效分析的深入扩展,用于考察治疗效果在不同患者子群(如根据年龄、性别、疾病分期等划分)中的一致性或差异。这有助于识别潜在的治疗效果修饰因素,即某些基线特征是否会改变治疗的相对疗效。例如,在一个治疗组 vs 对照组的比较中,分析是否男性患者比女性患者获益更多,从而指导临床决策和未来研究。亚组分析的原理是通过分层建模,在每个子群内单独计算风险比(HR)及其置信区间,同时检验治疗与子群变量的交互作用(P for interaction),以评估异质性。如果交互P值<0.05,表示疗效在子群间显著不同;否则,整体结果适用于所有子群。但需注意,亚组分析易受小样本影响(增加假阳性风险),建议作为探索性分析,仅在生物学合理时解读。系统自动生成单因素(未调整)和多因素(调整协变量)结果,支持分类子群变量(水平较少,避免小样本子群事件数不足导致HR极端)。
本部分仅支持两组疗效比较(三组以上暂不支持),因为多组交互计算复杂,可能导致结果不稳定。需在疗效比较分析完成后进行(使用相同数据和模型设置)。如果前一步选择了多因素调整,这里会自动包括调整后的亚组结果;否则仅单因素。
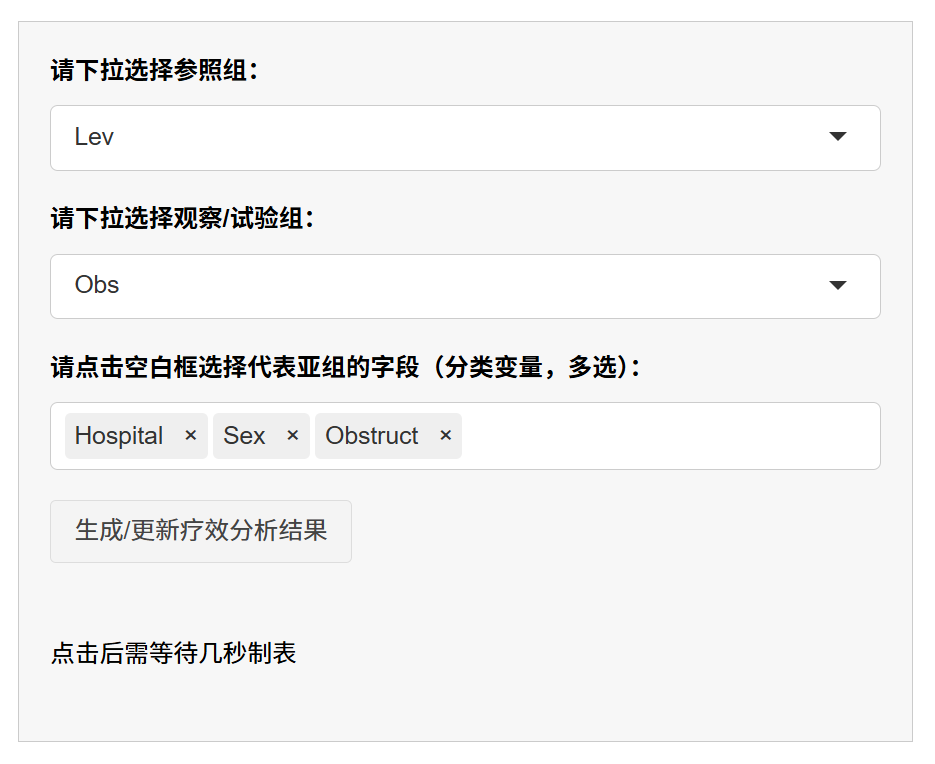
操作步骤如下:
进入“亚组分析”标签:确认前一步疗效分析已完成,且分组为两组(系统会自动校验,如果分组超过两组,无法 proceeding)。这一步使用主分析的生存时间、状态和分组变量,确保一致性。
选择参照组和观察组:从下拉菜单选择参照组(基准组,如标准治疗组)和观察组(比较组,如新治疗组)。菜单仅显示两个取值(基于主分析的分组)。参照组是计算HR的参考(HR=观察组风险/参照组风险),通常选对照组,便于解读正向疗效(HR<1表示观察组更好)。
原理:亚组分析聚焦二元比较,确保HR方向统一。选错组别会反转结果,但不影响统计显著性。
- 选择亚组变量:从下拉菜单多选分类变量作为子群划分依据(如年龄分组<60 vs ≥60、性别男 vs 女)。变量必须有2-29个水平(太多水平导致子群过细,计算失败或结果不可靠)。建议选临床意义强的变量(如3-5个),避免无关或高维度变量(如医院名称)。
原理:每个变量按水平分层,系统在全人群(Overall)和每个子群内分别建模,计算HR。整体行无交互P值(正常),子群行显示事件分布(事件数/总数 (%)),帮助评估子群样本充分性(小子群事件少,HR CI宽、不稳定)。
- 点击生成结果:点击“生成/更新疗效分析结果”按钮,系统自动计算并显示亚组分析表(单因素或单+多因素,取决于是否调整协变量)。表格结构:
子群列:整体(Overall)和每个变量的水平(子水平缩进显示,如“年龄”下“<60”和“≥60”)。
组别事件率列:参照组和观察组的事件数/总数(%),如“10/50 (20.0)”。显示子群内事件发生情况(仅两组比较)。
HR (95% CI)列:子群内风险比及其置信区间(如1.20 (0.80-1.80))。单因素为未调整,多因素为调整后(控制协变量,如年龄对生存影响)。
P值列:子群内HR的显著性(<0.05表示组间差异)。
交互P值列(P for interaction):检验治疗效果在子群间的异质性(<0.05表示显著差异,如治疗在<60岁组更有效)。
表格底注注明调整协变量(若有)。如果HR为0/Inf/NA或极大,表示子群数据问题(样本/事件太少),需返回合并水平、填补缺失或移除变量。生成后,可用AI描述模块点击“用AI描述此表”获取结果段落草稿,便于论文写作。
结果可迭代更新(如添加/移除子群变量)。如果子群过多或样本小,优先报告交互P值显著的亚组,避免过度解读。
亚组分析森林图
亚组分析森林图是亚组结果的可视化呈现,用于直观展示每个子群的风险比(HR)及其置信区间(CI),以及整体异质性。通过线段(森林线)和点(效应量估计)表示HR,线段越短表示精度越高;中轴线(通常HR=1)分隔有利/不利效果,便于快速识别子群差异和交互作用。原理基于图形化统计:森林图汇总多子群结果,突出模式(如某些子群线段不跨中轴线,表示显著差异),并通过底箭头标注疗效方向(需用户自定义,避免主观偏差)。它补充表格,帮助读者一眼把握关键发现,但需注意小子群CI宽(不确定性大)。本工具允许编辑数据和自定义外观,确保图符合期刊要求(如NEJM风格)。需在亚组分析完成后进行,否则无数据。
操作步骤如下:
进入“亚组分析森林图”标签:确认前一步亚组分析已生成表格(系统自动加载结果)。如果无数据,需返回上一标签完成分析。
查看并编辑可编辑表格:主面板显示亚组结果的交互表格(DT格式),每行对应一个子群或整体,每列包括子群名称、组别事件率、HR、CI、P值、交互P值。双击任意单元格编辑内容(如修正P值四舍五入、调整HR显示格式,或处理极端值如Inf/NA)。编辑后点击生成按钮更新图。
原理:表格是森林图的数据源,编辑允许用户校正计算误差或自定义(如将NA改为“-”),确保准确性。极端值(如HR=Inf)常因小子群事件0导致,编辑可标记为空,避免误导。
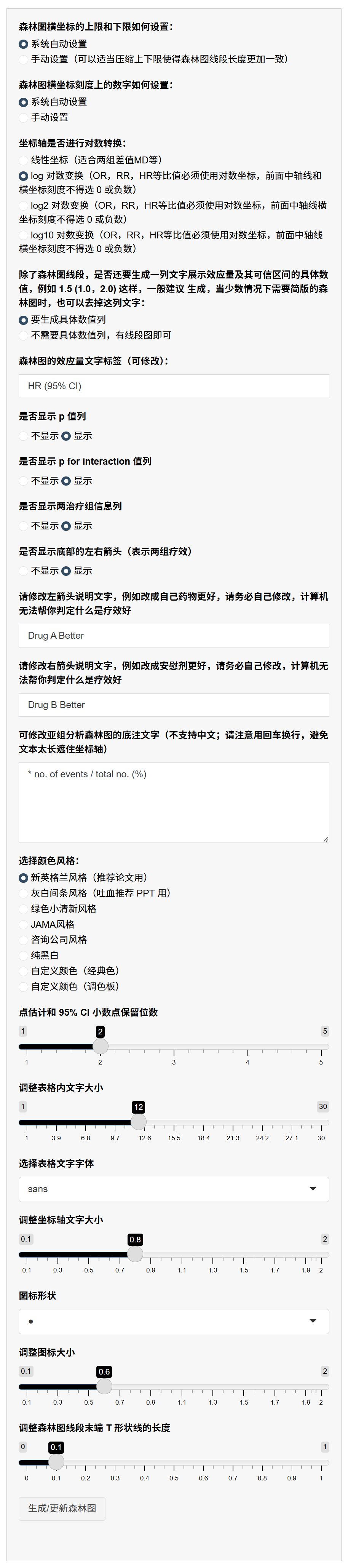
- 调整森林图外观选项:侧边栏提供丰富自定义:
横坐标限和刻度:选择自动或手动设置限值(如下限0.5、上限5)和刻度数字(逗号分隔,如“0.5,1,2,3”)。手动压缩限值使线段更一致,美化图。
坐标变换:选择线性(适合差值)或对数(log/log2/log10,适合HR/OR,避免0或负数)。
数值列显示:选择是否额外列出HR (95% CI)文本(如“1.5 (1.0-2.0)”),简化版可隐藏。
效应量标签:修改HR列标题(如“Adjusted HR (95% CI)”)。
P值和交互P列:选择显示/隐藏,聚焦关键信息。
组信息列:选择显示/隐藏事件率或N(样本数)。
底箭头(两组比较):选择显示,并自定义左右箭头文本(如左“Drug A Better”、右“Drug B Better”),表示HR<1/ >1的疗效含义。需用户判断方向。
底注:文本框编辑脚注(如“*事件数/总数 (%) **调整协变量:年龄、性别”),支持多行(回车换行),注明调整因素。
颜色风格:选择预设(如NEJM白底、灰白条纹、绿色等)或自定义(两色交替,经典或调色板)。
数字和图形调整:设置小数位(1-5)、表格字体大小/类型、坐标轴字体、图标形状/大小、线段末端T线长度。
原理:自定义确保图专业(如对数轴使HR对称,便于比值解读;颜色提升可读性)。自动限值基于数据范围,手动优化避免线段过长/短。
- 点击生成森林图:点击“生成/更新森林图”按钮,系统计算并显示图。图包括:
子群列(缩进显示水平)。
事件率或N列(可选)。
HR点和线段(点大小表示权重,线不跨中轴表示显著)。
P值和交互P列(可选)。
中轴线(HR=1)和底箭头(方向指示)。
如果HR极端(如0/Inf),线段为空白,需检查数据。
原理:图汇总亚组HR,视觉化异质性(交互P标注)。交互P检验治疗-子群交互,指导是否报告子群特异效果。
- 下载森林图:生成后,点击下载PNG(高清图片)、PPT(幻灯片)或PDF(矢量图)。调整大小确保不失真。
结果可迭代(如编辑表格后重新生成)。森林图适合论文结果或讨论部分,突出关键子群(如交互显著者),但避免过度分割数据导致假发现。
第五部分 下载Word报告或论文
这一部分用于生成完整的Word报告或论文模板,整合所有分析结果和图表。需在完成前述步骤后进行,确保数据和分析已就绪。报告分为英文版(适合国际期刊)和中文版(适合国内投稿),自动嵌入高清图表和表格。
操作步骤如下:
进入“下载Word报告或论文”标签:点击标签,界面显示英文和中文下载按钮。点击任一按钮,弹出信息收集模态对话框(窗口)。窗口从上到下逐项填写,必填完整才能下载。
填写患者人群描述:在第一个文本框输入研究对象人群(如“接受EGFR-TKI治疗的晚期非小细胞肺癌患者”)。必须填写完整,否则无法显示后续项。示例:接受一线EGFR-TKI治疗的晚期非小细胞肺癌患者;若非患者,填“健康人群”。
填写各分组水平描述:根据分组变量的水平(自动列出,如“Lev”、“Obs”),逐个文本框输入每个组的详细治疗方案(如“nivolumab 240 mg 静脉输注,每两周一次”)。每个水平需独立描述(如剂量、途径、频率),安慰剂填“安慰剂”,无治疗填“常规护理”。必须全部填写,否则无法下一步。示例基于常见方案,但需根据实际修改。
选择研究类型:单选“前瞻性研究”或“回顾性研究”。选择后解锁后续。
如果选择前瞻性,选具体设计:单选“随机对照试验 (RCT)”或“观察性研究”。
如果选择RCT,选盲法类型:单选“双盲”、“单盲”或“开放标签(非盲)”。
填写主要终点描述:在最后一个文本框输入主要结局(如“总生存”)。仅填一个核心指标,示例:Overall survival; progression-free survival 等。
点击下载英文或中文报告:填写完,点击相应按钮生成DOCX文件(文件名随机,如“efficacy3_report_en_1234.docx”)。系统处理几分钟(进度条显示),下载报告。
报告内容包括生成的标题、摘要(分Objective、Method、Result、Conclusion,附关键词)、引言、方法(患者数据、入排标准、干预、随访、统计)、结果(嵌入基线表、生存率表、中位生存表、HR表、生存曲线、亚组表、森林图、PH检验)、讨论,以及附录。每个部分有AI辅助文本描述结果。下载后,用Word打开检查内容(如参考文献真实性、事实准确),手动编辑补充细节(如具体医院、日期)。如果生成失败或不满意,重新填写或下载。

4.10 倾向性评分匹配(PSM)
这是一个全自动做倾向性评分匹配(PSM)的工具。
具备以下功能:
1)瞬间自动生成匹配前后基线特征表和 love plot;
2)可以边看匹配后的结果表格边调匹配参数,实时调整结果,所见即所得;
3)匹配完成后可以继续在匹配前和匹配后的数据基础上做两组疗效比较分析;
3)自动生成Word报告,论文里需要的图表一分钟给您全部准备好;
4)可下载匹配后的数据自行分析。
所谓倾向性评分匹配,用粗俗的话说来就是在非随机对照研究中,因为没有随机分配患者,所以观察组和对照组基线特征有差异,俗称基线不平衡。会使得读者质疑你的疗效分析结果。所以我们只好牺牲一些样本量,从对照组中选择一部分和观察组基线差异较小的患者,来进一步分析疗效(有时候为了效果,观察组也要牺牲掉一部分样本)。
4.10.1 准备数据
首先按照下面的格式准备数据:
下载Excel样例数据(右击另存为)
请务必下载下来参考
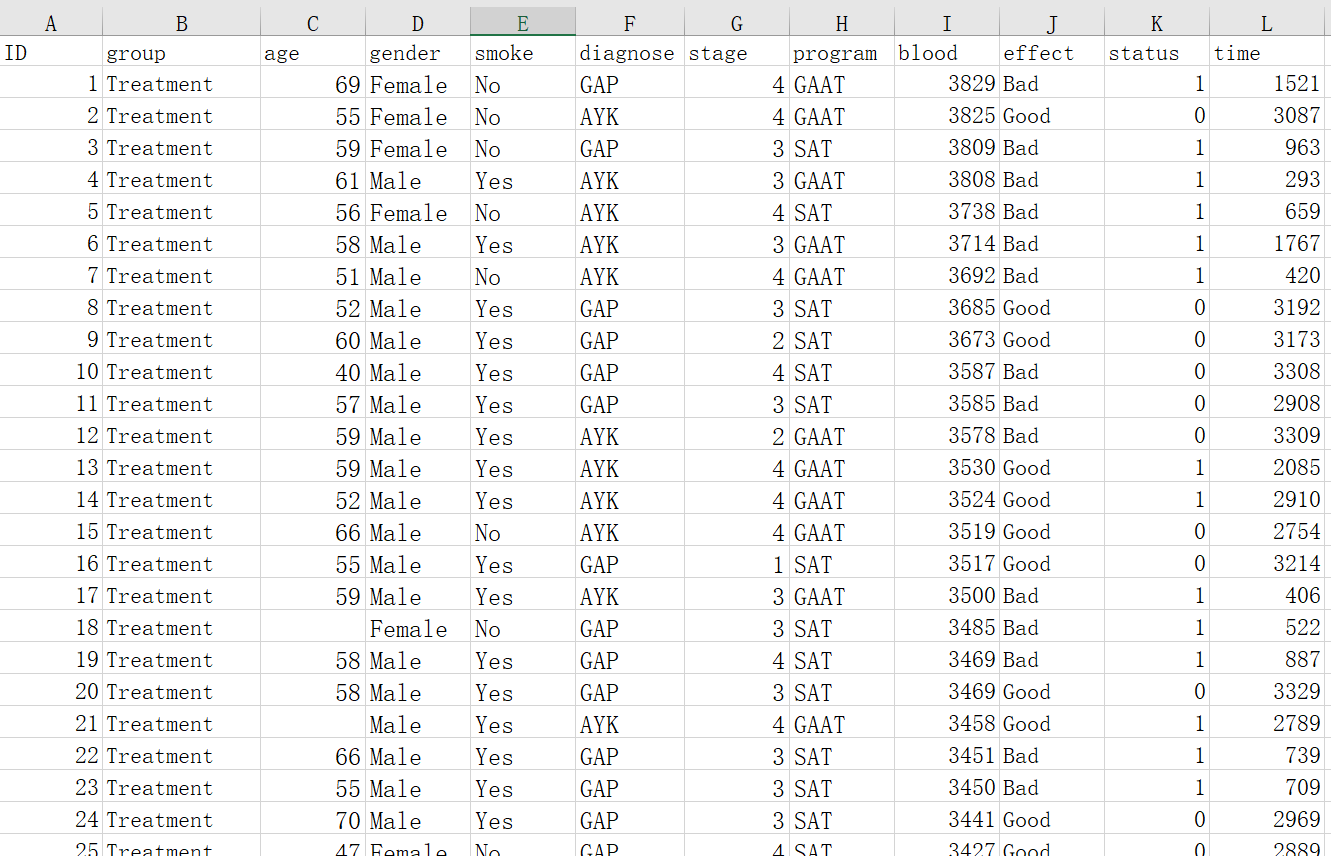
数据包括ID号,代表组别的变量如group, 以及需要调整和匹配的协变量如age, gender, smoke, diagnose, stage, program等。另外,还有代表结局的变量,如 blood(连续性),effect (二分类),time 和status (生存)等。
应当注意的是,代表组别的变量, 下面只能包含两个组,如”Treatment” ,“Control”,或者GroupA GroupB等。不能包含两个以上组。三组的PSM本工具暂不提供。
4.10.3 基础设置
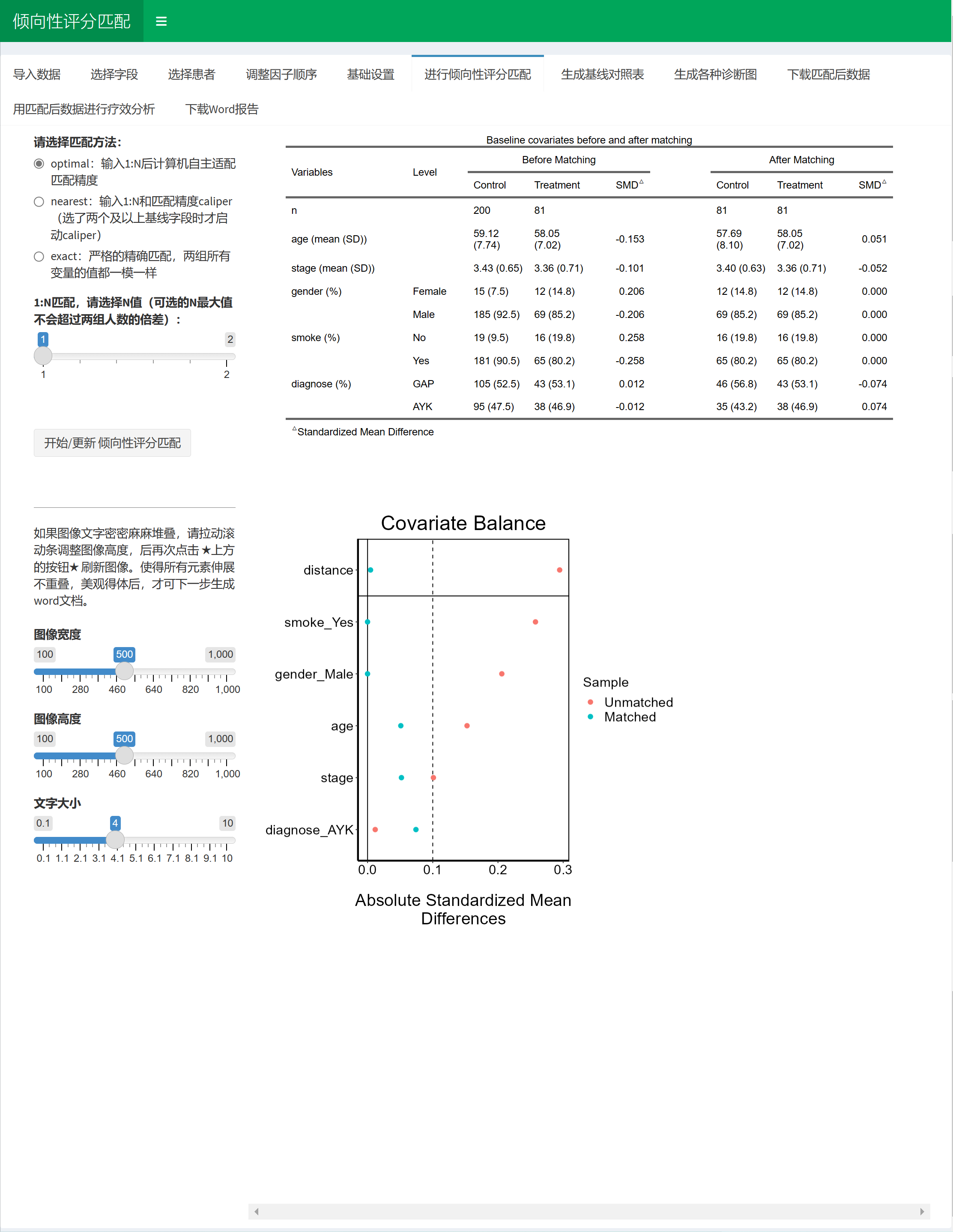
首先选择代表组别的字段,这个案例里是group, group字段里面包含Treatment 和 Control两个组,在这两个组间进行PSM。千万不要把ID号、age这样的连续性变量设为组别,程序会崩溃。
然后点击基线变量选择框,按照自己想要的顺序选择需要匹配的变量。
然后点击选择疗效结局指标,这里把结局列出来是防止大家把它们选到基线那里去匹配了,起到个提醒作用。
最后,选定处理缺失值的方式,这里提供了两种方式处理缺失数据,第一种简单粗暴,只要有任何一个进行PSM的字段有缺失值,就把这个患者直接剔除。第二种是用kNN法填补缺失值。大家可以综合自己的数据缺失程度考虑哪种方法。
点击处理缺失值后,即可下一步。这里也可以下载处理缺失值后的数据到自己的电脑。
4.10.4 进行倾向性评分匹配
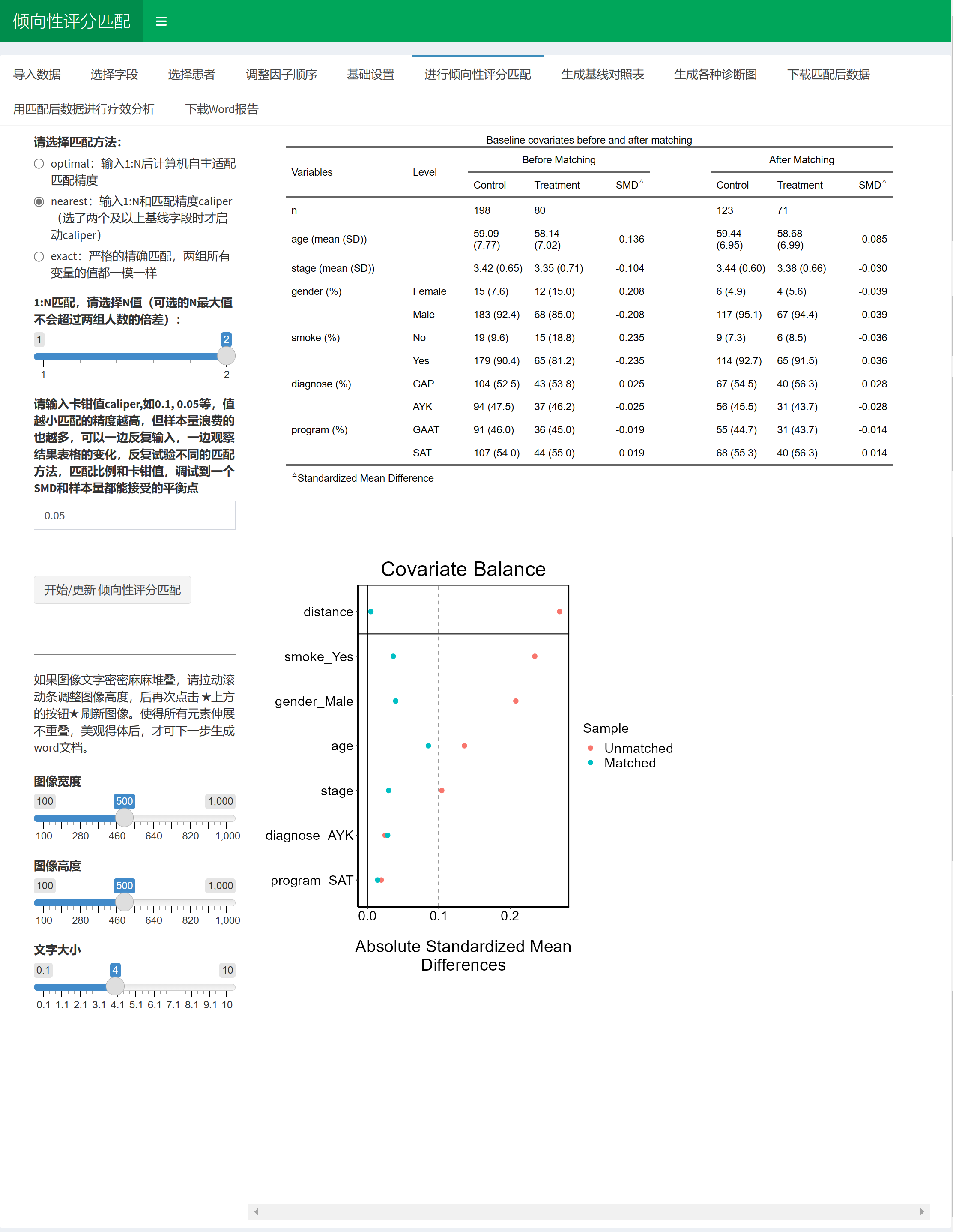
先选匹配方法,可选的匹配方法现在放出来的主要是optimal, nearest, exact。
下面是文献中对这几种方法的说明:
"Optimal" performs optimal pair matching. The matching is optimal in the sense that that sum of the absolute pairwise distances in the matched sample is as small as possible. Advantages of optimal pair matching include that the matching order is not required to be specified and it is less likely that extreme within-pair distances will be large, unlike with nearest neighbor matching. Generally, however, as a subset selection method, optimal pair matching tends to perform similarly to nearest neighbor matching in that similar subsets of units will be selected to be matched.
"Nearest" performs greedy nearest neighbor matching. A distance is computed between each treated unit and each control unit, and, one by one, each treated unit is assigned a control unit as a match. The matching is “greedy” in the sense that there is no action taken to optimize an overall criterion; each match is selected without considering the other matches that may occur subsequently.
"Exact" performs exact matching. With exact matching, a complete cross of the covariates is used to form subclasses defined by each combination of the covariate levels. Any subclass that doesn’t contain both treated and control units is discarded, leaving only subclasses containing treatment and control units that are exactly equal on the included covariates. The benefits of exact matching are that confounding due to the covariates included is completely eliminated, regardless of the functional form of the treatment or outcome models. The problem is that typically many units will be discarded, sometimes dramatically reducing precision and changing the target population of inference.
然后optimal 和 nearst 法可选择1:N匹配。
可选的N值上限是程序根据您两组的样本量自动计算的,程序自动认定不会超过两组患者数的比值。
另外,nearest可选caliper, caliper 可以自己随便调整,比如从0.01调整到0.5都可以,值越小,则匹配越精切,但样本量损失就越多。大家可以根据提示,看着生成的图表来调参,一边调整caliper一边看图形,以达到满意的结果。
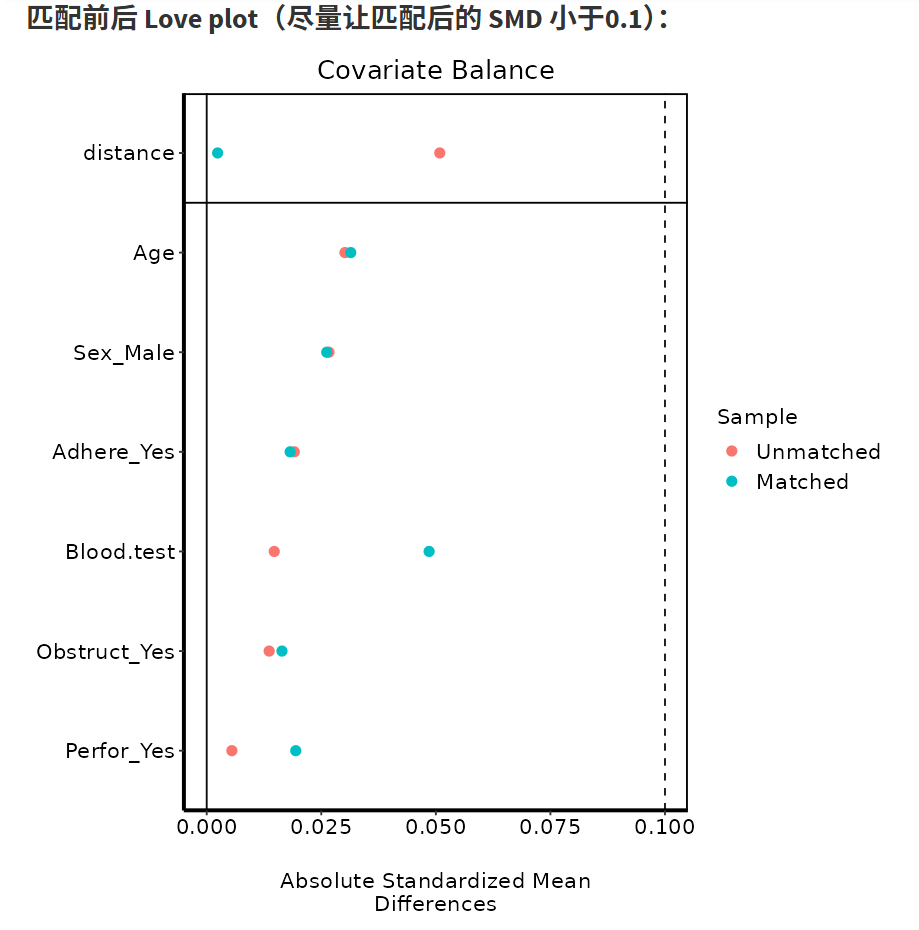
在生成的表1中,可以实时看到匹配前后的样本量和SMD值。尝试改变各种参数使得SMD值低于0.1即可。
可以看着下面生成的图调整:
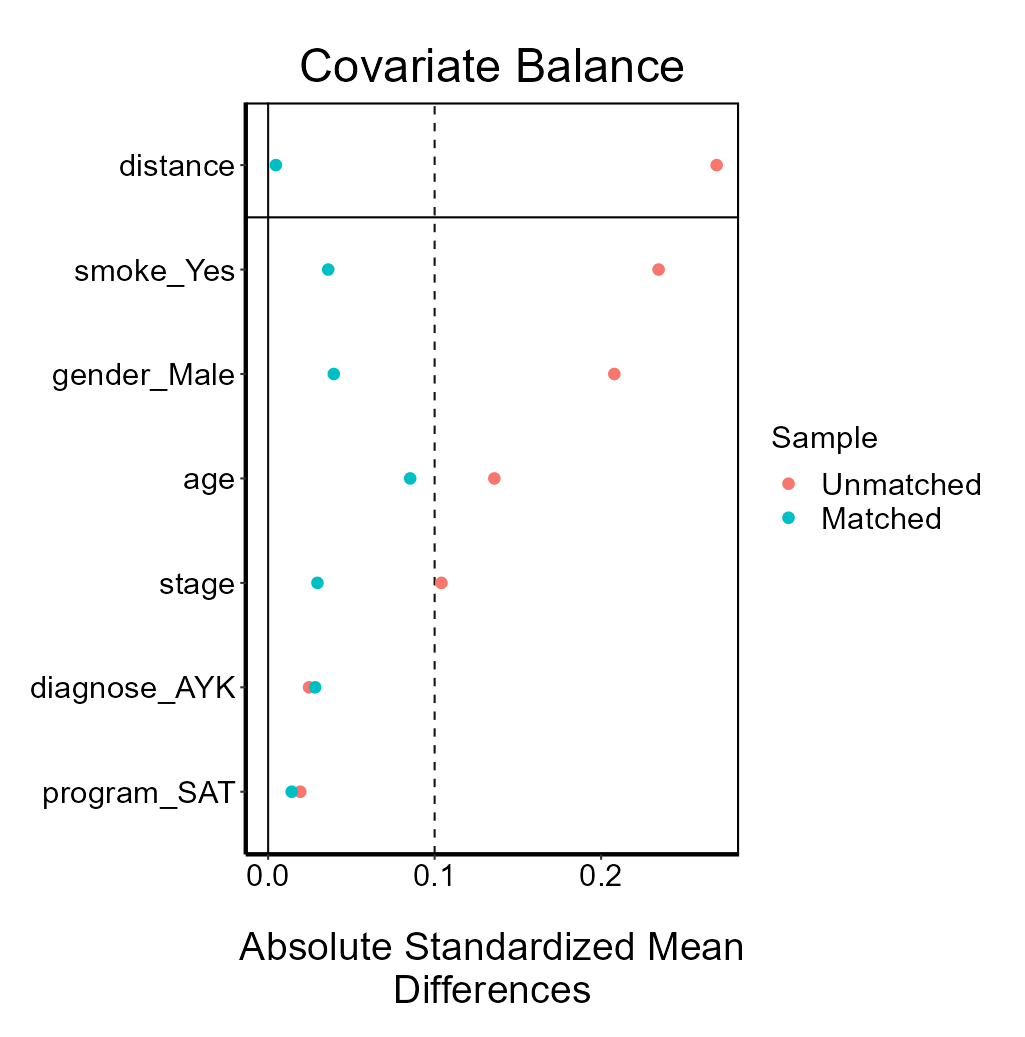
调整参数使得绿色的点全部位于虚线左边就算成功。当然,有个别的点,实在没办法低于0.1也不要紧。科研嘛,还是要考虑科学性和现实性的平衡。
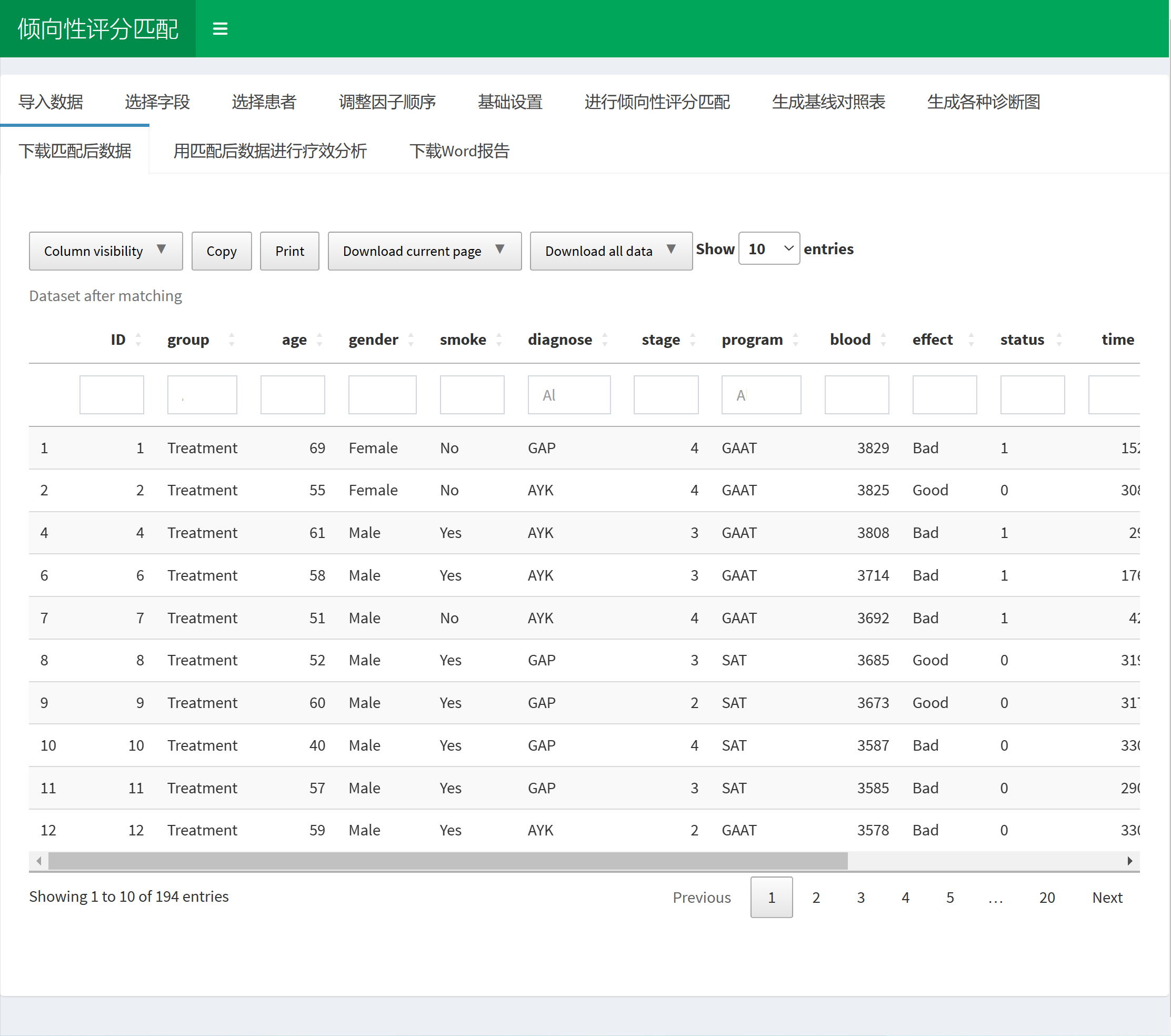
4.10.7 下载匹配后数据
点击”下载匹配后数据”选项卡,可以看到匹配后的数据,从ID号我们可以看出,有一部分人已经被剔除了。
点击 “download all data” 即可下载,下载到自己电脑上后可以自己随便玩,当然也可以在本APP上继续往下走做匹配后的疗效分析。
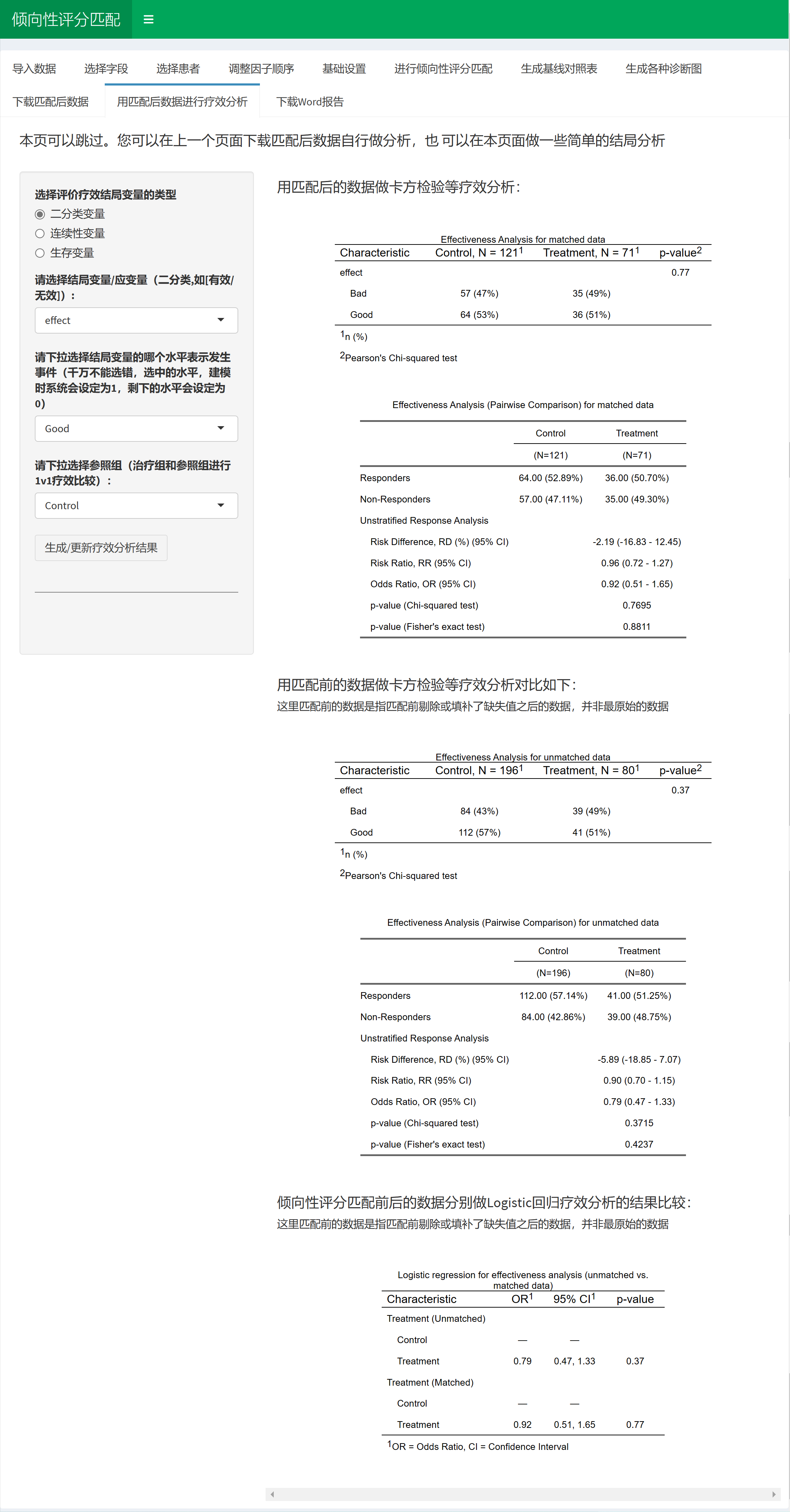
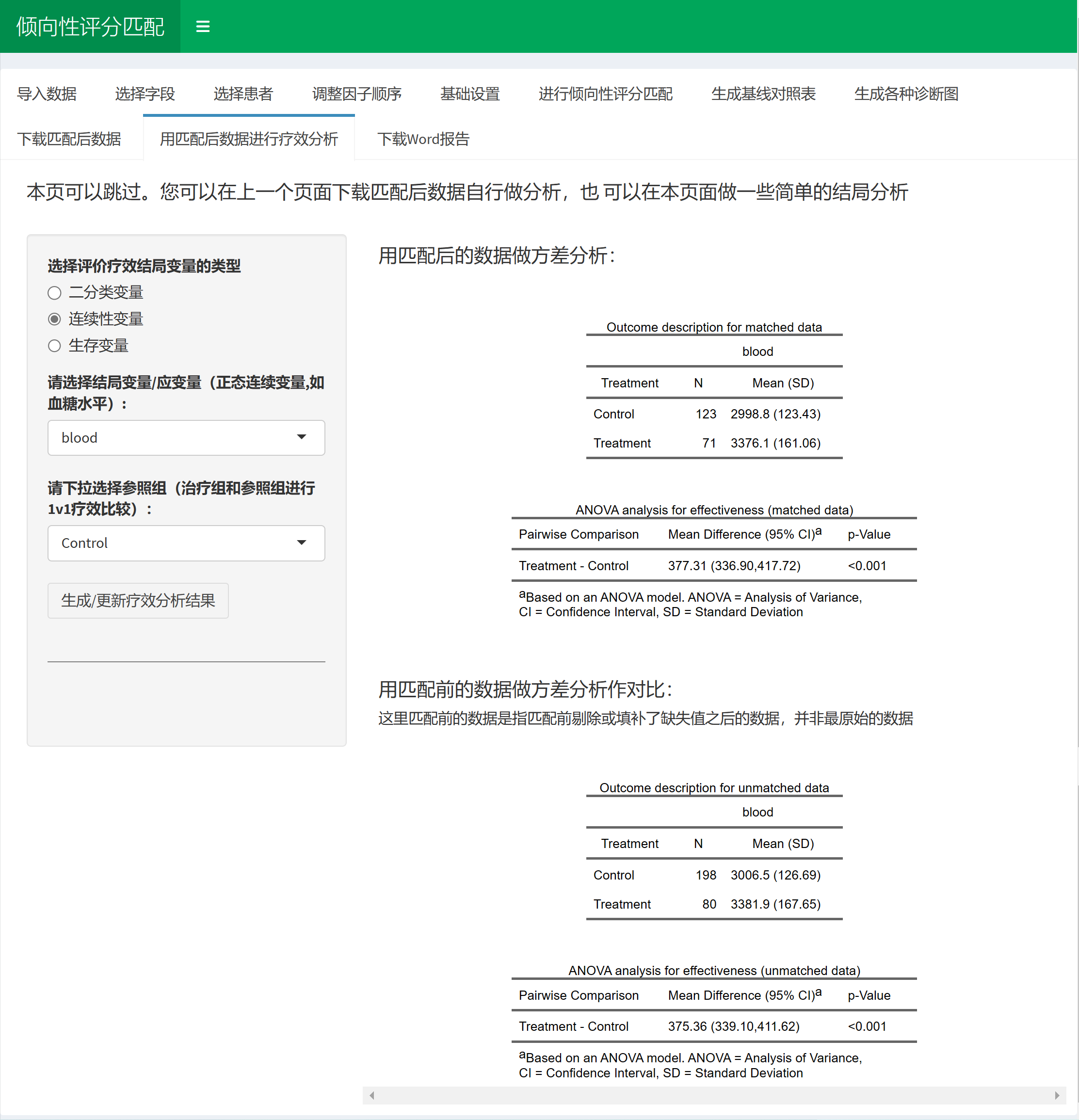
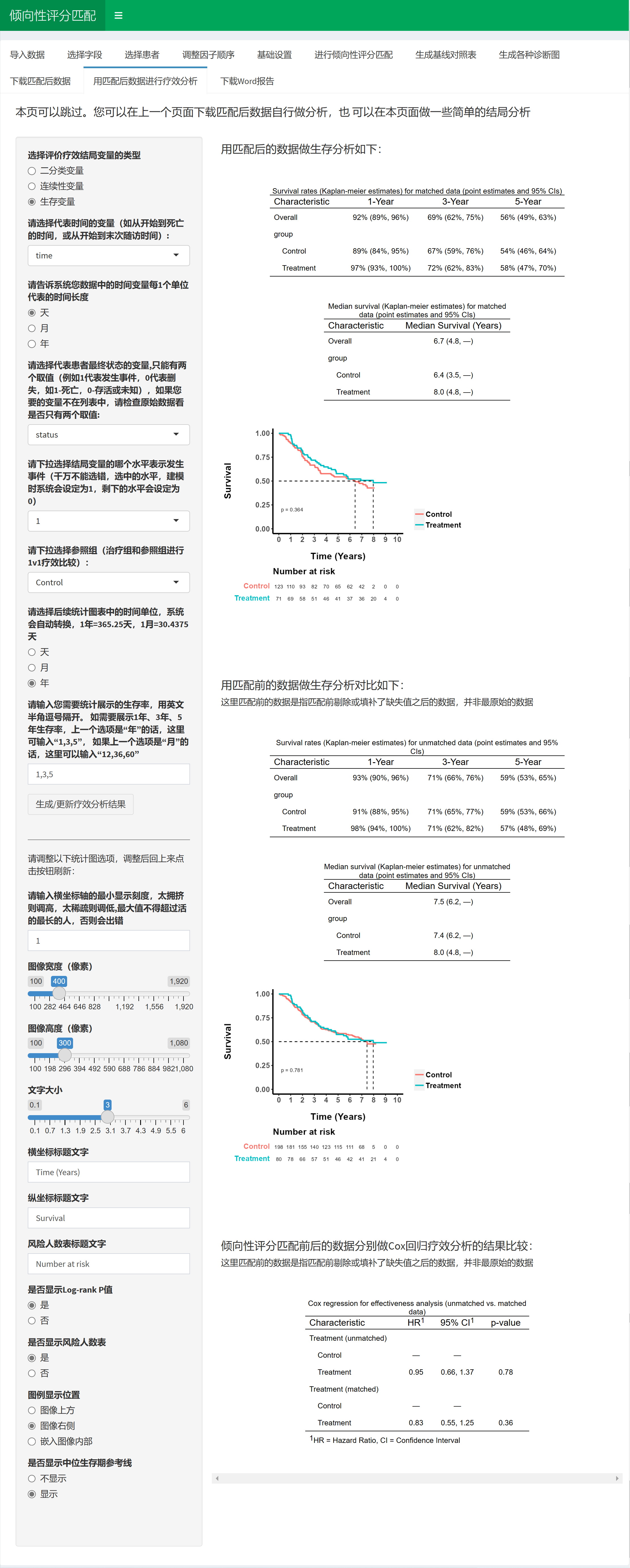

4.11 寻找治疗有效和无效人群(治疗组和一个连续性指标的交互作用限制性立方样条图)
交互作用立方样条图是一种在统计分析中用于探索和解释变量之间相互作用的可视化工具,特别是在处理治疗组(如药物治疗与否)与一个连续性变量(如年龄、血压等)之间的交互作用时。这种方法通过使用限制性立方样条(restricted cubic splines,RCS)来灵活建模连续变量,从而允许研究者准确估计治疗效果如何随连续变量的不同水平而变化。
在医学研究中,理解和解释治疗效果如何受到其他连续性生物标志物或临床指标的影响是至关重要的。例如,在研究某种新药对高血压患者的效果时,研究者可能需要考虑药物效果如何随患者年龄的不同而改变,因为年龄可能会影响药物的代谢和效能。通过使用交互作用立方样条图,研究者能够直观地展示出治疗效果随着年龄变化的趋势,进而为个性化医疗提供依据。
具体来说,这种分析方法可以帮助解决如下问题:
确定某一治疗是否对不同子群体有不同的效果;
研究连续性变量如何调节(即加强或减弱)治疗效果;
为临床决策提供更精细化的指导。
案例 1:
在一项关于新型心血管疾病药物治疗的研究中,研究者可能专注于探讨药物对降低心血管事件(如心肌梗死或中风)发生风险的效果,特别是这种效果如何随着患者的胆固醇水平变化而变化。在这个例子中,治疗的结局是二分类的:心血管事件的发生(是/否),而胆固醇水平是一个重要的连续性变量,可能会影响药物的疗效。
研究的目标是确定在哪个胆固醇水平区间内,患者从药物治疗中获得的心血管保护效果最大。通过构建一个包含药物治疗与胆固醇水平交互作用的逻辑回归模型,并利用限制性立方样条(RCS)来灵活描述胆固醇水平的影响,研究者可以评估心血管事件风险随胆固醇水平变化的趋势。
研究结果可能表明,对于中等胆固醇水平的患者,新型药物显著降低了心血管事件的风险;然而,在非常高或非常低的胆固醇水平中,药物的保护作用减弱。这表明胆固醇水平在药物疗效中扮演了调节作用,且存在一个最优的胆固醇水平区间,使得心血管保护效果最大化。
通过绘制交互作用立方样条图,研究者可以直观地展示药物预防心血管事件的效果如何随胆固醇水平的不同而变化,从而为医生提供了一个有力的工具来判断在何种胆固醇水平下推荐该药物治疗,以最大限度地减少患者心血管事件的风险。这种方法促进了针对特定胆固醇水平患者群体的个性化治疗策略的发展,有助于更精确地定位治疗效果,提高临床治疗的整体效能。
案例 2:
在心血管疾病的预防研究中,研究者可能会关注一种新的生活方式干预措施(如定期运动)对于不同血压水平人群的效果。这项研究的目的是探索血压这一连续性变量的特定取值范围内,哪些人群在接受干预后能获得更显著的健康效益。使用交互作用立方样条图,可以灵活地描绘出干预效果随着血压不同水平的变化趋势。
具体而言,研究可以建立一个模型,将参与者分为接受生活方式干预的组和未接受干预的对照组,同时考虑血压作为连续性变量的影响。通过应用限制性立方样条(RCS),模型能够灵活地捕捉干预效果随血压变化的非线性关系。
例如,研究结果可能显示,在正常血压和轻度高血压的人群中,生活方式干预能显著降低心血管疾病的风险;而在已经有严重高血压的人群中,干预的效果减弱。这种分析不仅揭示了哪一范围的血压水平下干预最有效,也为针对特定血压水平的人群设计更个性化的预防策略提供了依据。
此外,通过绘制交互作用立方样条图,研究者可以直观地展示干预效果如何随着血压水平的不同而变化,从而为医生和患者提供更明确的指导,帮助他们理解在何种血压水平下采取生活方式干预措施能获得最大的健康益处。这样的研究不仅有助于优化干预策略,还能促进个体化医疗的发展。
本软件功能:
一键计算交互作用 p for interaction。
一键绘制交互作用限制性立方样条图。
一键标记干预有效范围的拐点。
一键拆分亚组做阈值分析。
一键绘制亚组分析森林图。
支持 线性/Logistic/Cox 回归
交互作用RCS:
阈值/亚组分析:
亚组分析森林图:
方法学来源:
2022年的一篇 JAMA 子刊:

另外的文献举例:
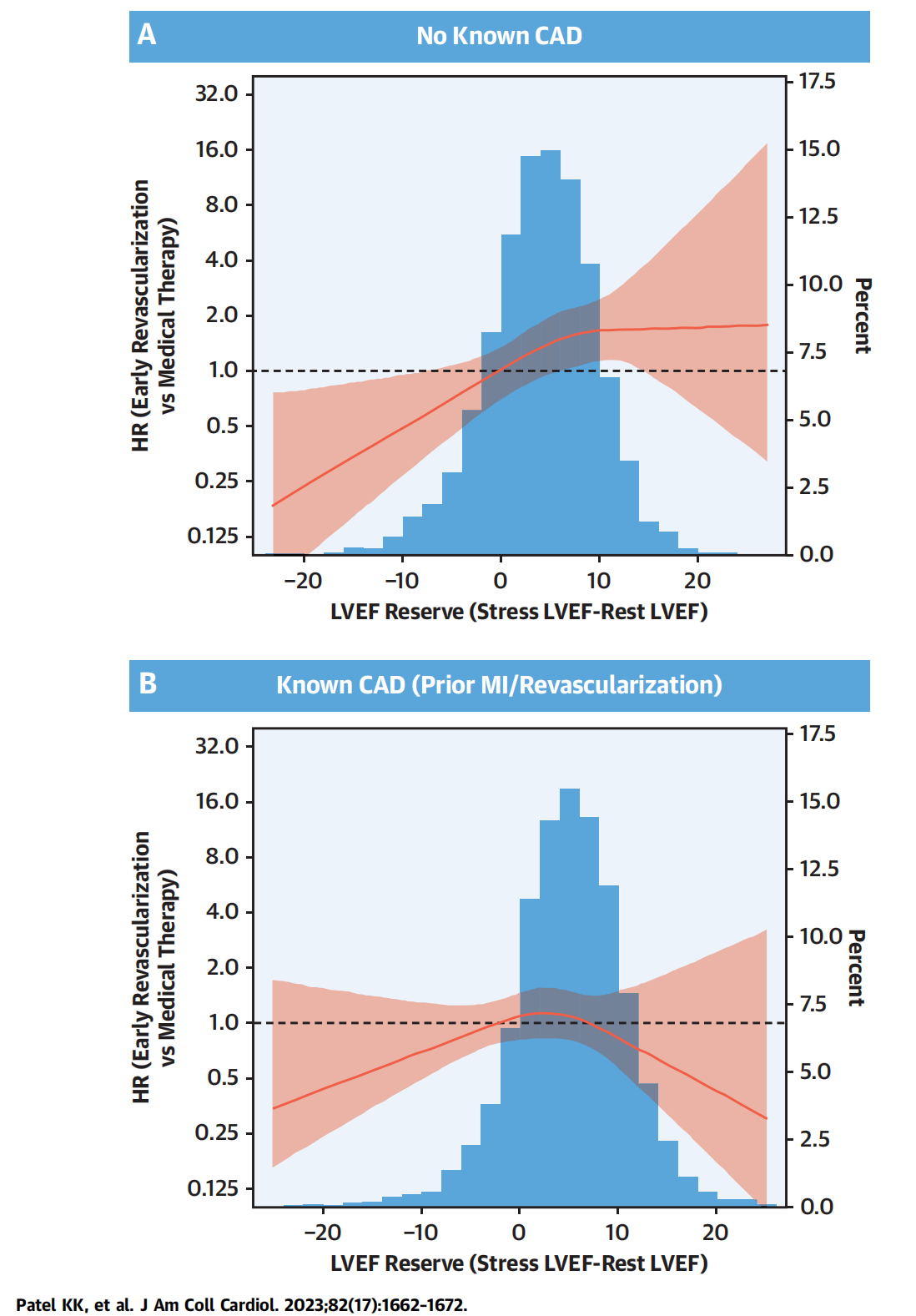
准备自己的研究时,可以参考一下几篇文章,照猫画虎很快就模仿出来高分 SCI 了:
Marston NA, Pirruccello JP, Melloni GEM, et al. Predictive Utility of a Coronary Artery Disease Polygenic Risk Score in Primary Prevention. JAMA Cardiol. 2023;8(2):130–137. doi:10.1001/jamacardio.2022.4466
Patel KK, McGhie AI, Kennedy KF, Thompson RC, Spertus JA, Sperry BW, Shaw LJ, Bateman TM. Impact of Positron Emission Tomographic Myocardial Perfusion Imaging on Patient Selection for Revascularization. J Am Coll Cardiol. 2023 Oct 24;82(17):1662-1672. doi: 10.1016/j.jacc.2023.08.027. PMID: 37852696.
4.11.1 准备数据
首先务必按照下面的格式准备数据(网站上可下载,下载后在此基础上修改):
打开如下图:
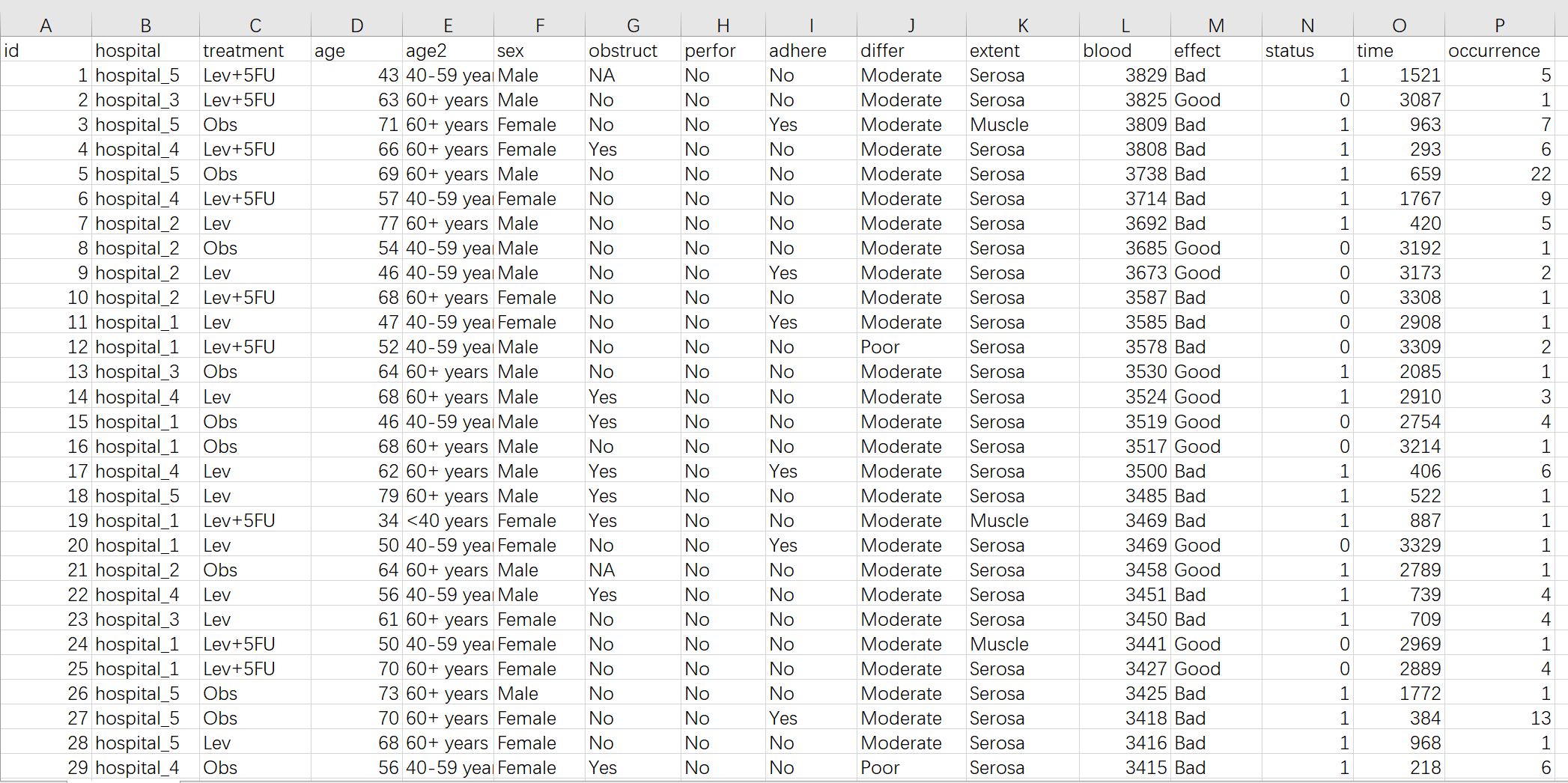
本样例数据的规则:
一个患者一行(这是准备数据最重要的前提)。
每个患者准备两大类数据,影响因素变量和结局变量:
如图所示,hospital, treatment, age, age2, sex, obstruct, prfor, adhear, differ, extent 为影响因素(自变量),而blood, effect, status, time, occurrence在本例中是结局变量。
影响因素变量有两种,连续性变量(值是连续数据,它可以在变量值所属区间内任意进行取值,如年龄(岁)、血糖值、人的身高、智商等)以及分类变量(是说明事物类别的一个名称,其取值是分类数据。如”性别”就是一个分类变量,其变量值为”男”或”女”;“行业”也是一个分类变量,其变量值可以为”零售业”、“旅游业”、“汽车制造 业”等),在本例中 age是连续性变量(numeric), 其他的是分类变量(factor)。age单位为”岁”时为连续变量,而age2为年龄段分组,这时候为分类变量。
以上概念很重要,后面有一个页面专门设置连续变量和分类变量。
结局变量在本工具中分为几类:
连续型结局变量
如本例中的blood(某血液检测指标)
二分类结局变量
如本例中的effect(疗效)为二分类变量(Good,Bad)
生存型结局变量
需要用两个变量组合来表示,如本例中的status和time。
status代表患者在研究结束时的状态,在本工具中只能取0和1两个数字,不要用字符文本,否则会出错。0 代表没观察到事件发生(如没死或者失访),1 代表观察到了事件发生(如已经死亡且录入了死亡日期)。
time代表从开始日期(开始日期的定义由你的研究目的决定,如随机对照研究往往取随机化入组的那一天为开始日期,而观察性研究可以取首次诊断日期或首次治疗日期等等根据研究目的而定)到结局日期的时间差。当status=1时,结局日期为发生事件(如死亡)的日期,当status=0时,结局日期为最后一次活着的日期(如研究结束日,或随后一次随访日)。
总之,time是一个数值型变量,您需要填入患者从开始到死亡或者随后一次随访时,一共活着的天数。如time为56,status为1时代表患者从开始到死亡活了56天;当time为56,status为0时代表患者没观察到死亡,从开始到最后一次随访,活了56天。
准备数据时,time填入一个非负的整数,status填入0或1,time和status都不能为空,每个患者都必须填入数字。time或status不确定(缺失)时,该患者最好不要放入本数据库。
4.11.2 进入模块
接下来我们进入模块,点击软件顶部菜单的“疗效和安全性分析”,然后点击“10+ 分 SCI 神套路,寻找治疗有效和无效人群:连续性变量和治疗组交互作用的立方样条图(2023 JAMA 子刊的新方法,大热中)” 进入模块:
4.11.3 生成交互作用限制性立方样条图
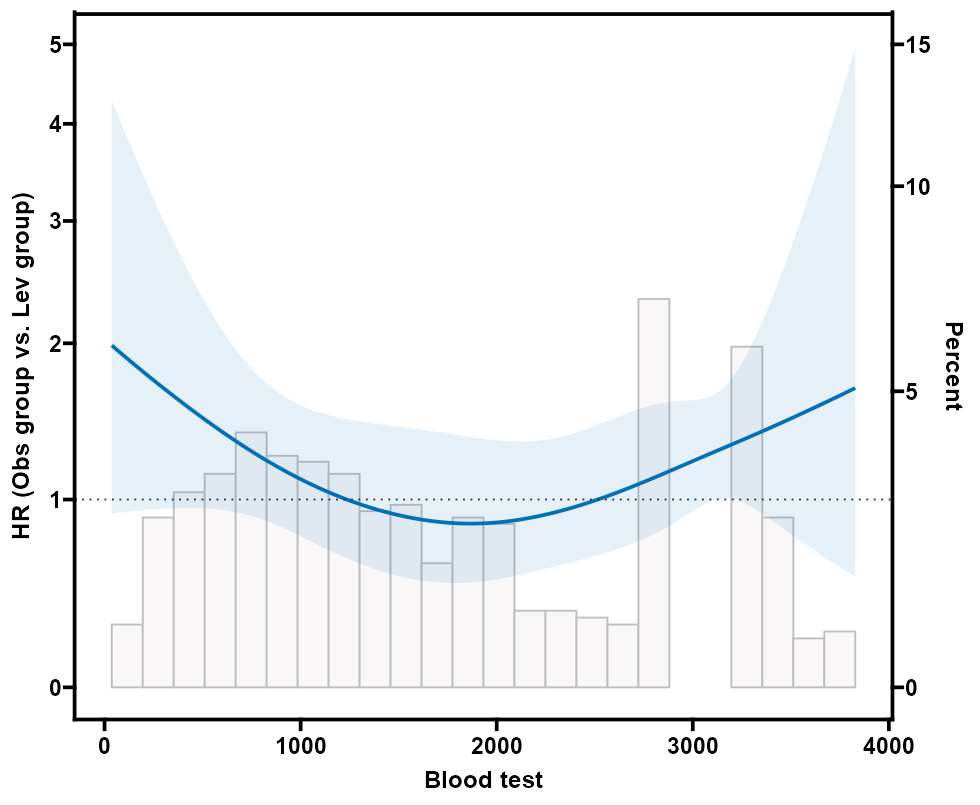
4.11.6 阈值分析/亚组分析
如何在我们的软件中进行人群的阈值分析/亚组分析,以便探讨不同人群在特定阈值下的疗效差异。以下是详细的操作步骤:
4.11.6.2 输入分割点的值
根据您选择的亚组数量,软件将要求输入相应数量的分割点值。例如,如果您选择将人群分割成3个亚组,则需要输入2个分割点的值,这些值将用于划分人群。
为每个分割点提供一个输入框,用户需要在每个输入框中填写分割点的具体值。
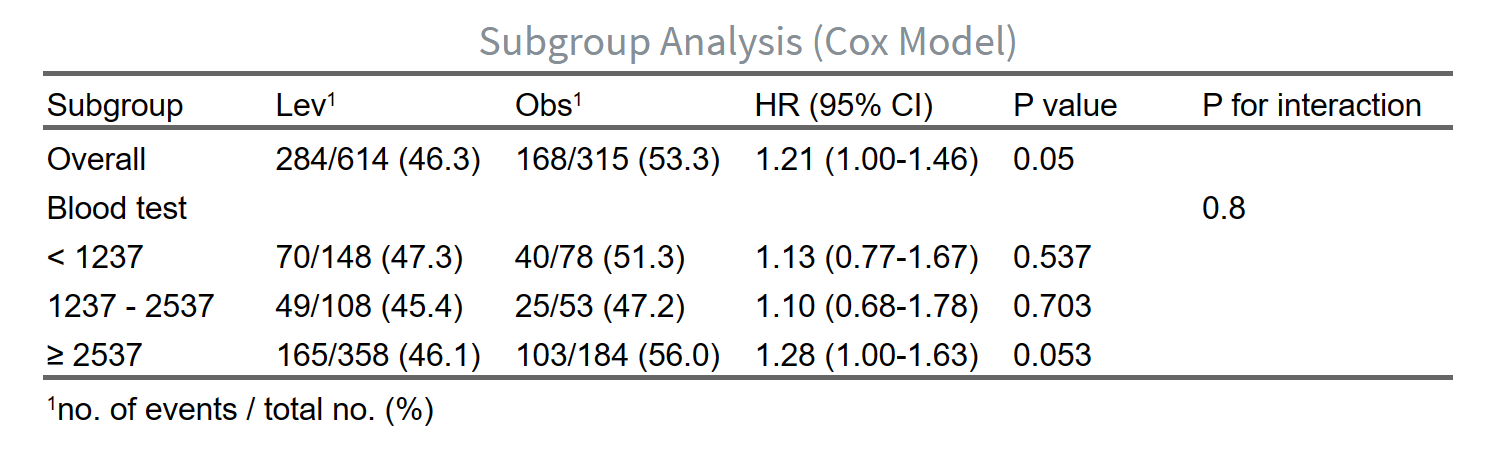
4.12 安全性分析和不良反应AE表格
4.12.1 安全性分析与AE表格概念
安全性分析: 在临床试验中,安全性分析是一个关键环节,它涉及监测和评估药物或治疗方法对参与者的潜在不良影响。这种分析的主要目的是确定治疗的风险和益处,确保患者安全。
AE表格: AE(Adverse Events,不良事件)表格是安全性分析的一个重要组成部分。它记录了临床试验中患者所经历的所有不良事件,包括事件的类型、发生频率、严重程度以及与治疗的关联性。这些表格有助于临床研究员快速了解治疗方法的安全性状况。
4.12.2 数据集准备
在使用本软件之前,需要准备两种数据集:
ADAE 数据集 - 这是一个包含不良事件信息的CSV格式数据集。它应包含临床试验期间记录的所有不良事件,以及相关的详细信息。
ADSL 数据集 - 这是另一个CSV格式数据集,包含患者的基本特征信息。这些信息可能包括年龄、性别、病史等。
如果您的临床试验数据是 CDISC 标准格式,请直接上传 ADAE 和 ADSL 这两个名称的数据集即可,如果您的数据不是 CDISC 格式,是您自己收集的数据,请按照以下模板来准备数据:
ADSL:
ADSL 数据集的特点是一个患者一行,包含所有的患者,每个患者有一个ID号如 USUBJID,这个ID号是不能重复的,
这个数据集主要是提供所有患者的ID号以及治疗分组(ARM),用来做 AE 表格的总人口分母。
ADAE:
ADAE 的特点是只包括发生AE的患者,且一个患者多行。患者 ID号例如 USUBJID 需要和 ADSL 里的 ID 号相同,可以重复多次,每个患者可以发生多次 AE,因此 ID 号可以重复。治疗组别 ARM 也必须和 ADSL 保持一致。AEDECOD 表示具体的AE名称,例如头痛,虚弱等;
AEBODSYS 表示AE的类型,例如神经系统AE,消化系统AE,用来归类。
一个患者可以发生多次头痛,需要重复多行,每行代表发作一次(发作的时间可以记录在另一个字段中)
4.12.4 软件操作步骤
启动软件并加载数据:
打开软件,你将看到一个用户界面,其中包含多个选项卡。
选择”生成不良事件AE表格”选项卡。
通过点击相应的按钮上传ADAE和ADSL数据集。
配置表格选项:
根据上传的ADAE数据集,动态生成下拉菜单以选择特定字段,如治疗组别、患者ID、AE名称和AE系统分类。
根据所选字段,软件将处理数据并准备生成AE表格。
生成AE表格:
点击”生成/更新AE表”按钮。
软件将根据选择的字段和上传的数据生成AE表格。
生成的表格将在主面板中显示。
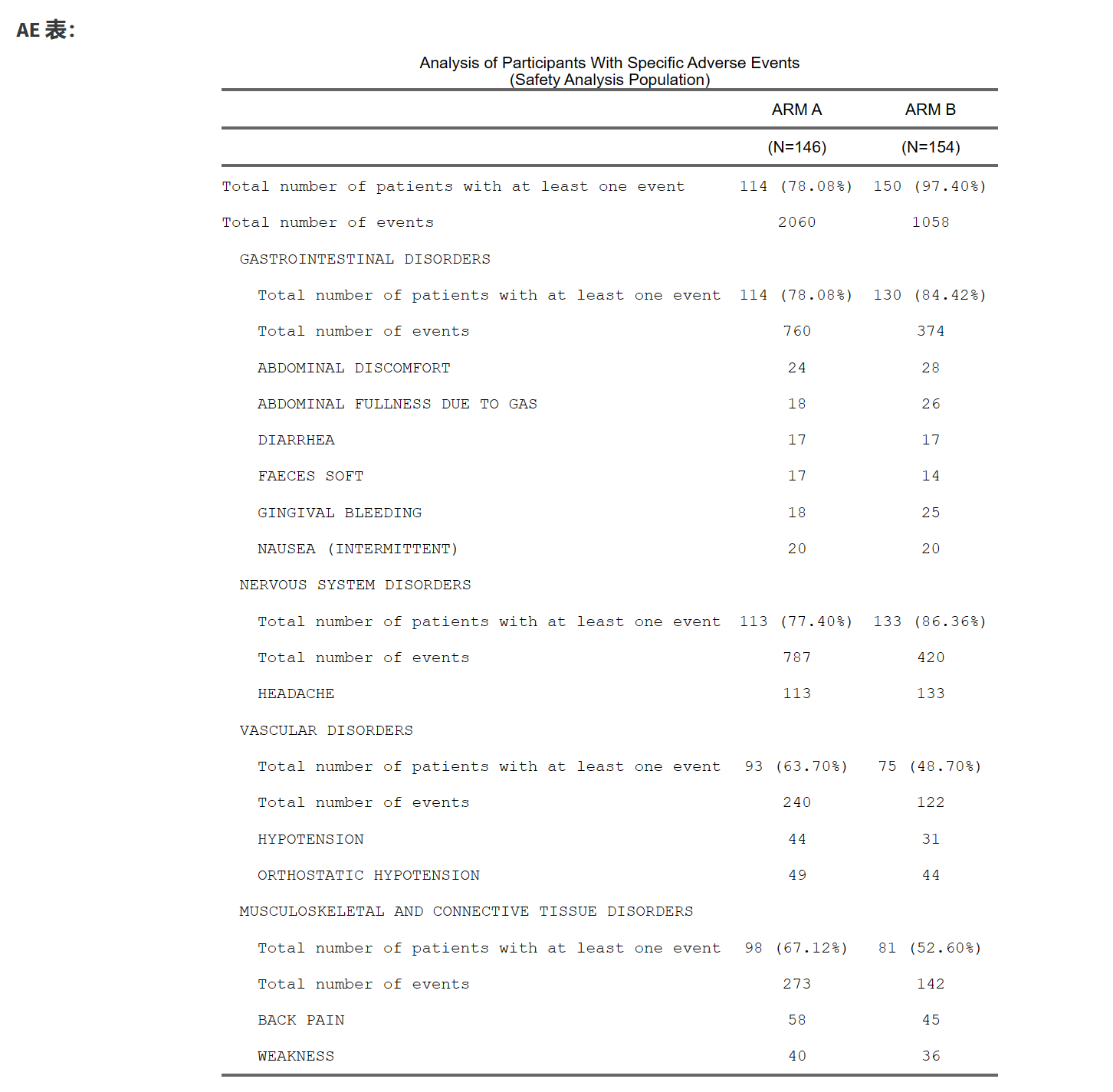
下载报告:
切换到”下载Word报告”选项卡。
点击”点此下载word文档”按钮,即可下载包含AE表格的Word文档。