Chapter 8 复杂抽样加权(用于 NHANES 等数据库分析)
8.1 基线人口学特征表 Table one(复杂抽样加权)
这是一款智能进行统计分析的工具,用来生成复杂抽样设计(如NHANES等)基线人口学特征表(Table one)。
主要特点:
根据上传的科研数据,设置分层变量strata,主要抽样单位 PSU,权重 weights 后,自动生成基线特征统计表
支持一维表(不分组)、二维表(分组)、三维表(分层+分组)
支持自动和手动指定组间比较的统计方法
采用复杂抽样 survey design 进行均值、中位数计算,进行 Survey t 检验、Survey 秩和检验比较组间 P值
支持人工智能生成描述性文字
生成投稿格式的word统计报告
针对 NHANES 等复杂抽样的数据,其基线人口学特征表(Table one)有多种表现形式,既可以用非加权的方式以常规 方法对样本数据直接分析(可到本软件常规描述统计模块做基线表),可也可以使用复杂抽样加权的方式展示。在动手分析 前请下载以下参考文献:
Inoue K, Seeman TE, Nianogo R, Okubo Y. The effect of poverty on the relationship between household education levels and obesity in U.S. children and adolescents: an observational study. Lancet Reg Health Am. 2023. 25: 100565.
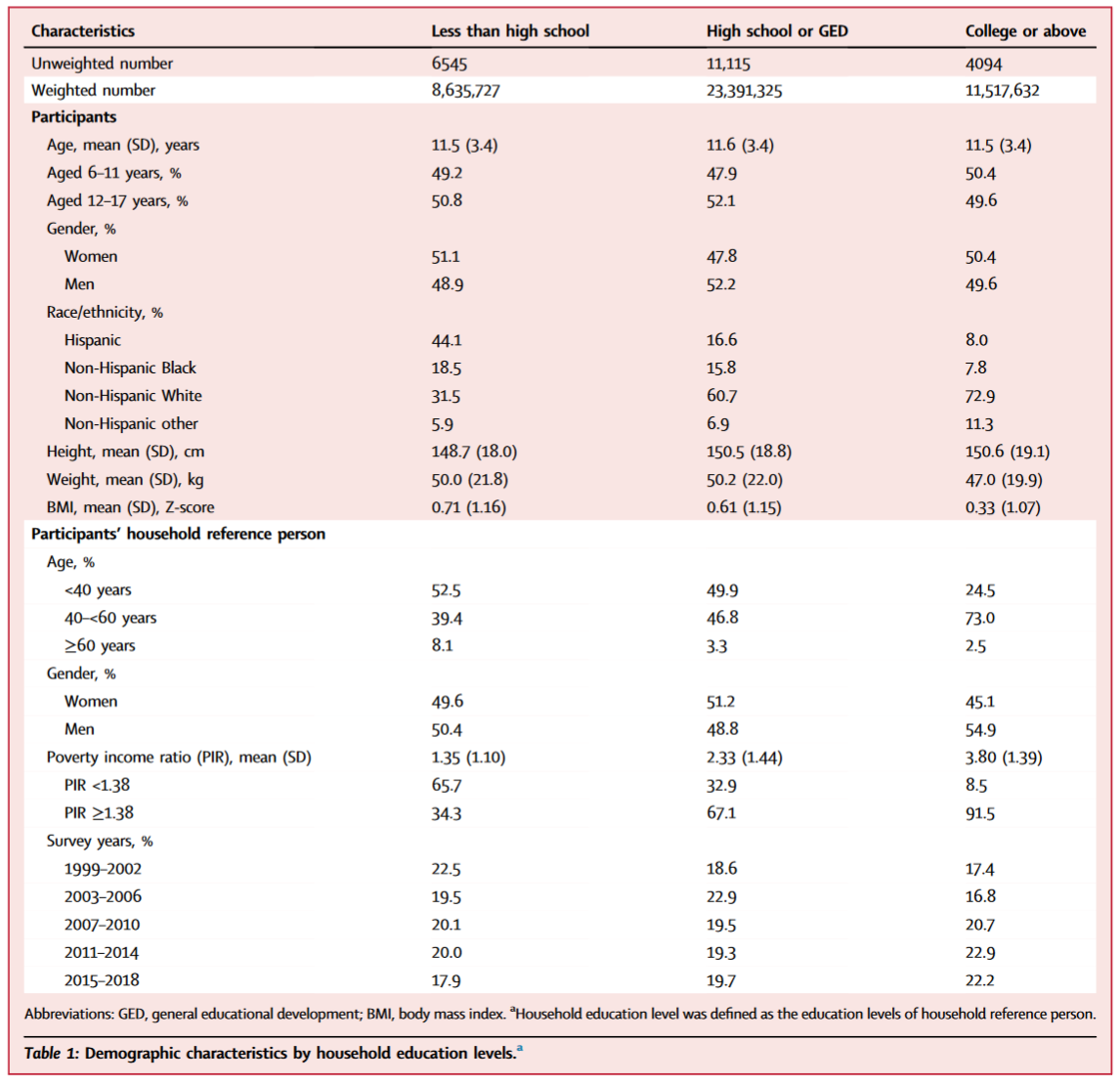
这篇 Lancet 子刊虽然 IF 不是最高,但 Table one 比较有代表性:
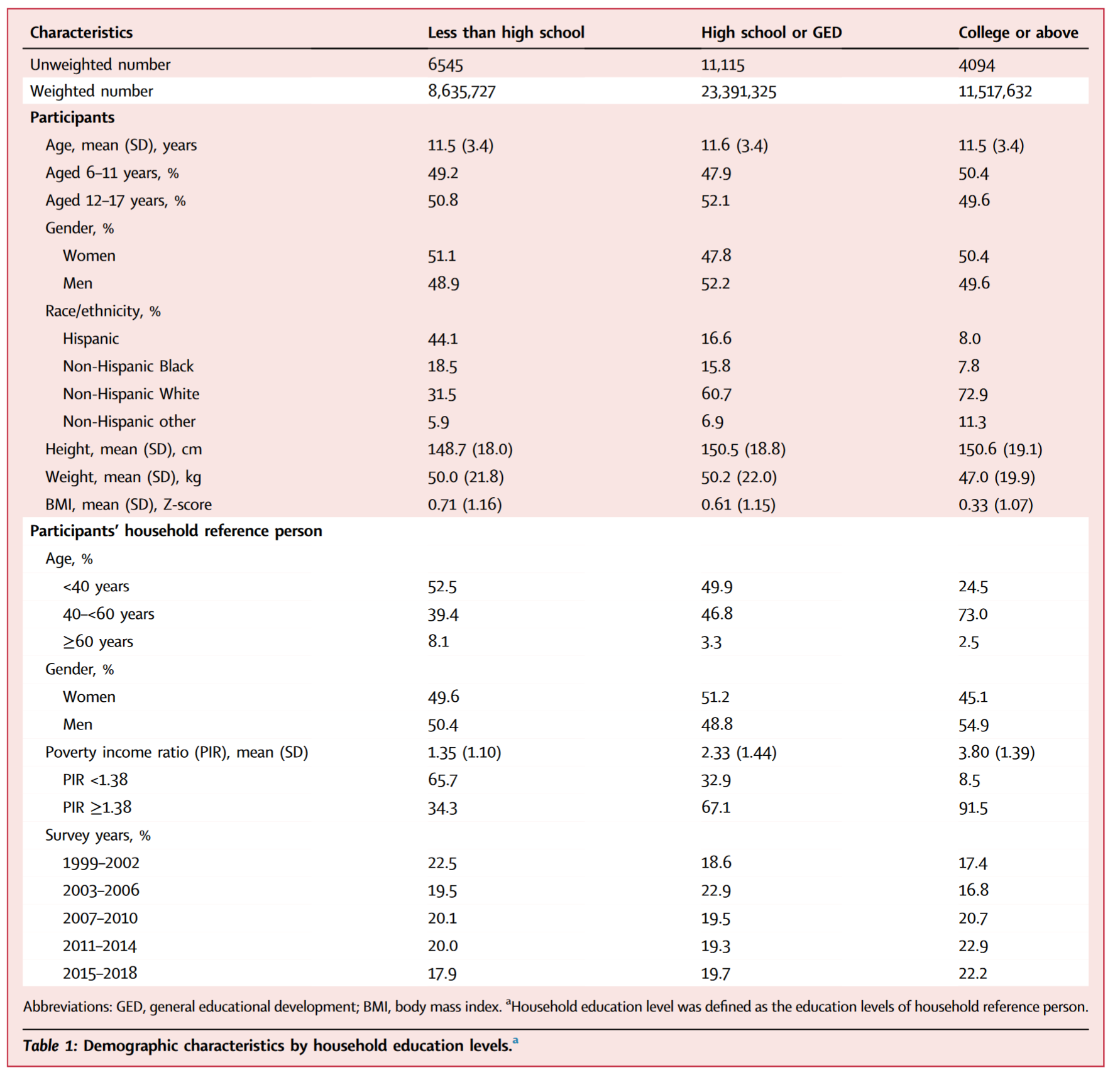
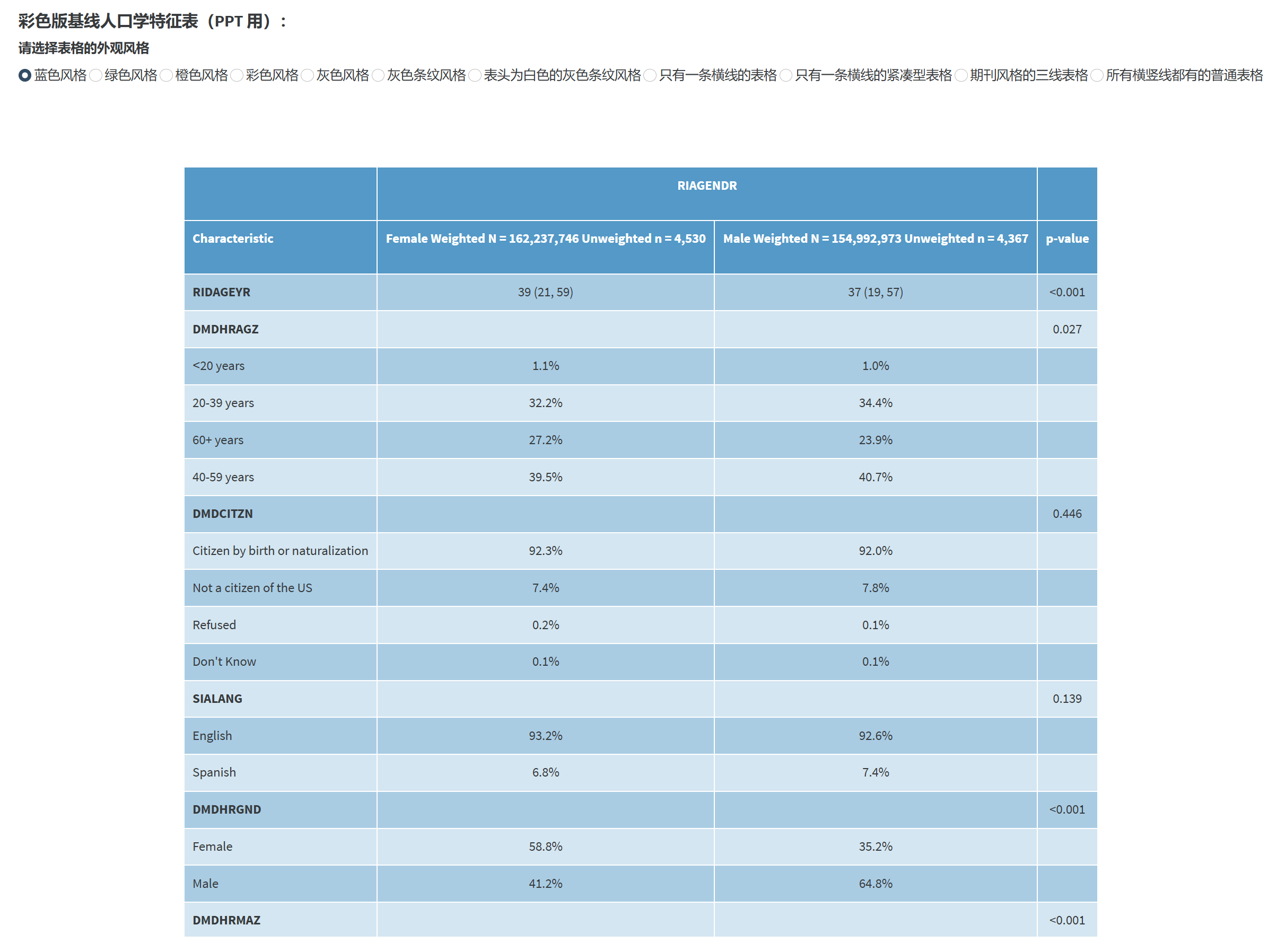
我们可以看到,这个表首先在最上面的两行表头,分别展示了 Weighted N 和 Unweighted n 的数量,在主表中,连续性 变量的 mean(SD) 或 Median(IQR) 均为加权后的值,而分类变量不用 n(%)表示,仅用 % 表示,这个百分比,是加权 之后的百分比。这是一种常见的表示方式。这个表不做组间的比较,不给出 P 值。
另外如果分类变量想用 n(%) 表示,其中的 n 可以用加权后的 n, 也可以用未加权的 n,这个可以在左侧面板进行选择。 参考文献见:
Liu F, You F, Yang L, et al. Nonlinear relationship between oxidative balance score and hyperuricemia: analyses of NHANES 2007-2018. Nutr J. 2024. 23(1): 48.
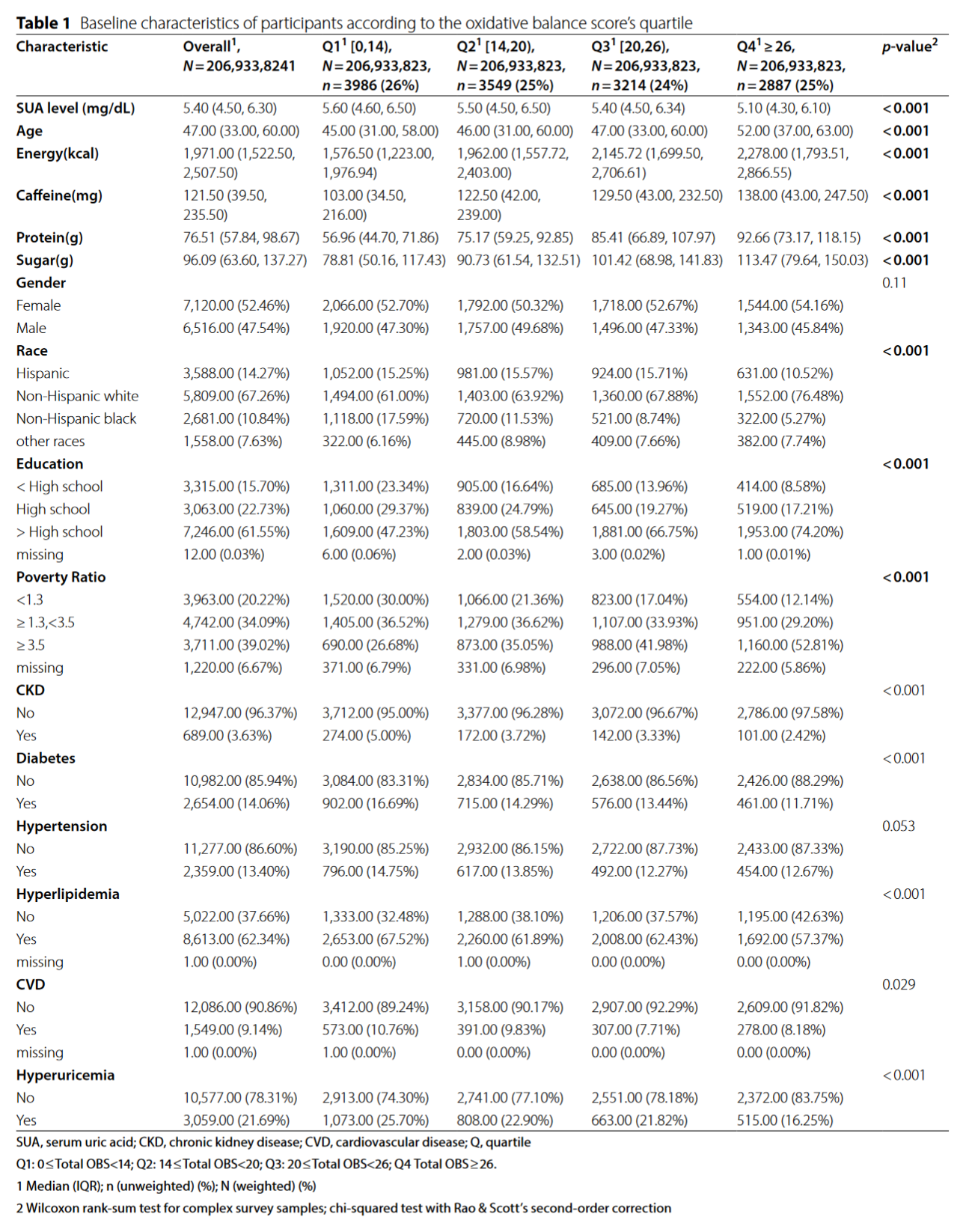
这里同样表头展示 Weighted N 和 Unweighted n 的数量,而分类变量用了 unweighted n (%),这里要注意 n 用了未加权的 n,但 % 是用了加权的百分比,n 和 % 并不匹配(这并不是作者出错),这也是常见的做法。组间比较 P 值, 连续性变量用 Wilcoxon rank-sum test for complex survey samples; 分类变量用 chi-squared test with Rao & Scott’s second-order correction,和本软件默认的统计方法相同,当然 您也可以手动改成 t test for complex survey sample。
如果是 NHANES 数据库,加权后的 N 代表美国人口,如果不是亚组分析而是全集分析,不 剔除缺失值时,总样本量 N 加起来约为 3.1-3.3 亿左右,如果根据 NHANES 的说明书,对权重进行了减少,则样本量 N 可能会低于美国人口数,这都是正常的。
8.1.1 背景知识
在研究中,我们通常感兴趣的是量化某些群体特征,例如某种病症的患病率、某一测量值的平均值,或暴露与疾病之间的关联性。通常,我们会在总体中抽取一个样本,并利用样本中的信息对总体特征进行推断。样本单位可以是个人、社区、医院、县甚至国家。
8.1.1.1 简单随机抽样
简单随机抽样是一种最基础的抽样方法,其特点是总体中每个单位被选中的概率相等。这种方法的优点是计算简单,分析方便,且能够保证样本统计量是总体参数的无偏估计。
例子:假设我们要研究一个城市中居民的平均收入。我们可以将这个城市的所有居民列成一个清单,然后随机选取其中的100人进行调查。每个居民被选中的概率都是相同的。在这种设计下,样本均值、样本方差等统计量都是总体参数的无偏估计,可以直接用来推断总体。
8.1.1.2 复杂抽样设计
许多调查使用复杂抽样设计而非简单随机抽样。这有多种原因。例如,如果构建列出总体中每个单位的抽样框架很困难或可能导致错误,可以使用多阶段抽样,先抽取较大且易于列出的单位群体,然后在每个群体内调查某些或全部单位,这样可以在现场构建准确的抽样框架。在多阶段抽样中,首先抽取主抽样单位(PSU)(例如,家庭),然后在每个PSU内抽取单位(例如,家庭中的个体)。当然,可以有超过两个阶段的抽样。早期阶段的单位形成簇。
另一个使用复杂抽样设计的原因是简单随机样本可能会导致某些感兴趣的子群体样本量过小。例如,如果关注种族/民族特定的平均血压,研究人员可能希望增加较小子群体的样本量。简单随机样本可能会导致多数种族/民族的样本量较大,而少数群体的样本量较小。与其增加总体样本量以确保较小群体的足够样本量,不如使用不等概率抽样对大群体进行欠抽样,对小群体进行过抽样,这样更具成本效益。
一种不等概率抽样的方法是在一些多阶段抽样设计中按比例概率抽样(PPS),其中较大的PSU有更大的被选中概率。另一种是分层随机抽样,即首先将总体非随机地分成若干层(例如,地理区域),然后在每层内进行简单随机抽样。将总体分层成不等大小的层,然后在每层内进行简单随机抽样,会导致不等概率抽样,因为较小层中的个体有更大的被选中概率。
8.1.1.3 NHANES
国家健康与营养检查调查(NHANES)是一个具有复杂设计的调查的例子。
NHANES样本不是简单随机样本,而是使用复杂的多阶段概率抽样设计来选择参与者,以代表美国民间非机构化人口。还对某些人口子群体进行过度抽样,以提高这些特定子群体健康状况指标估计的可靠性和精确性。研究人员需要在分析中适当指定抽样设计参数。
简而言之,NHANES采用了分层四阶段抽样设计。首先,根据人口普查区域和其他地理信息构建分层(非随机)。在每个分层内,随机选取美国县(PSU),较大的县有更大的被选中概率。在县内,按比例选取街区。在街区内,随机选取家庭,并对某些年龄、种族和收入群体进行过度抽样(较高的选中概率)。最后,在家庭内随机选取个体。有关NHANES复杂抽样设计的完整描述,请参见官方NHANES教程。
NHANES网站提供了使用survey软件包分析NHANES数据的示例R代码,以及在分析NHANES数据时的一些特殊考虑。
8.1.2 准备数据
NHANES数据的下载地址在 https://wwwn.cdc.gov/nchs/nhanes/
这里我们可以点击下方下载一段样例数据片段来做测试:
在本说明书中,我们使用了2017周期的NHANES数据,因此以下信息来自该周期。数据集中包含以下变量以考虑抽样设计:
分层变量(SDMVSTRA):共有15个分层。
主要抽样单位(SDMVPSU)
访谈抽样权重(WTINT2YR)
检查抽样权重(WTMEC2YR)
空腹子样本抽样权重(WTSAF2YR):
在使用NHANES数据时,请务必查阅相关数据文档和代码手册,以确保使用适当的抽样权重。
复杂抽样设计的基线表 Table 1 应该遵循什么样的格式呢?
8.1.4 操作步骤
进入软件界面,首先进行如下设置:

8.1.4.1 设置复杂抽样参数
请按照以下步骤设置您的复杂抽样参数:
选择分层变量
在设置界面中,找到“请选择代表分层(strata)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的分层信息。例如,在NHANES数据库中,这个变量通常是SDMVSTRA。
背景知识:分层抽样(Stratified Sampling)是一种将总体分为若干个互不重叠的层,然后在每个层内进行随机抽样的方法。这种方法可以提高估计的精确性,特别是在总体内部具有较大异质性的情况下。例如,在NHANES中,不同地理区域(如不同的州或县)可能存在健康状况的差异,通过分层抽样可以确保每个区域的代表性。
如果您的数据不需要分层,请选择“无”。
选择主抽样单位(PSU)变量
选择完分层变量后,系统会自动弹出“请选择代表主抽样单位(id)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的主抽样单位(PSU)。例如,在NHANES数据库中,这个变量通常是SDMVPSU。
背景知识:主抽样单位(Primary Sampling Unit, PSU)是多阶段抽样中的第一层单位。在NHANES中,PSU通常是县或县级等价单位。在每个PSU内,再进一步抽取次级单位(如家庭或个人)。这种方法可以减少调查成本,提高抽样效率。
确保所选变量不同于分层变量。
选择权重变量
选择完PSU变量后,系统会自动弹出“请选择代表权重(weights)的变量”选项。
从下拉菜单中选择一个权重变量。权重变量有助于确保样本的代表性。在NHANES数据库中,常见的权重变量有WTINT2YR、WTMEC2YR等。
背景知识:权重(Weights)是用于调整样本统计量以反映总体参数的因子。在复杂抽样设计中,由于不同单位被抽中的概率不同,直接使用样本统计量可能会产生偏差。权重的作用是校正这种偏差,使估计值更接近于总体参数。例如,在NHANES中,不同个体的被抽中概率不同,通过使用合适的权重,可以确保结果具有全国代表性。
选择权重的指南(简化版,仅做示例):
访谈权重(WTINT2YR):如果您的分析仅使用在访谈中收集的数据,则选择此权重。每个参与者都接受了访谈,因此每个人的访谈抽样权重都大于0。
检查权重(WTMEC2YR):如果您的分析包含体检数据,则应选择此权重。大多数参与者在移动检查中心(MEC)接受了体检,收集了客观测量数据。
空腹子样本权重(WTSAF2YR):如果您的分析包含空腹血液测量数据,则应选择此权重。只有部分参与者在空腹状态下提供了血液样本,因此需要使用相应的权重进行调整。
注意:选择权重变量非常复杂,以上只是一个简要规则,实际规则比这个复杂,请务必登录和参考NHANES官网的说明书,对于选择哪个权重有详细的规则说明,以确保选择适当的权重。
处理权重缺失值
在权重变量选择下方,您需要选择如何处理权重变量中的缺失值。
选项包括:
将权重缺失值用0填充
将权重缺失的数据整行删除
将权重缺失以及权重≤0的数据整行删除(Cox回归请勾选此项)
背景知识:在调查数据中,权重缺失值可能会影响分析结果的准确性。不同处理方法可以应对不同的分析需求和数据质量问题。例如,将缺失值填充为0可以保留数据行,但可能导致偏差;而删除权重缺失的数据则可以提高结果的准确性,但会减少样本量。
设置嵌套集群标识(Nest)
选择是否应用嵌套集群标识。如果您的数据集的ID值在分层中是嵌套的(如NHANES数据库),推荐选择“是”。
选择“是”可以确保在每个分层内,集群ID是唯一的,避免分析时出现问题。
背景知识:嵌套集群(Nested Clusters)是指在复杂抽样设计中,主抽样单位ID在不同分层内可能重复。通过设置嵌套集群标识,可以确保每个分层内的集群ID是唯一的,从而避免在数据分析时出现混淆和错误。例如,在NHANES中,不同地理区域可能有相同的PSU ID,通过嵌套设置可以确保分析的准确性。
8.1.5 绘制基线表
8.1.5.1 选择分组方式
进入“Table 1 设置”页面。
选择是否进行分组统计:
整体人群单组描述(一维表)
分组分析描述(二维表)
分层+分组分析描述(三维表) 默认选择为“分组分析描述(二维表)”。
8.1.5.3 选择组别变量
选择分组分析描述(二维表)或分层+分组分析描述(三维表)后,会提示选择一个组别变量。
如果数据库中没有可用的分类变量,将显示提示信息。
在下拉菜单中选择一个分类变量作为组别变量。
8.1.5.7 选择统计方法
选择连续性变量描述及组间比较的统计方法:
均值(标准差)统计,用 survey t test 检验
中位数(IQR)统计,用 survey Wilcoxon rank-sum test 检验
均值(标准差)、中位数(IQR)(最小值,最大值)统计,用 survey t test 检验
均值(标准差)、中位数(IQR)(最小值,最大值)统计,用 Wilcoxon rank-sum test 检验
自己选择每个变量用的统计学方法
8.1.5.8 选择统计方法标注方式
标注连续性变量统计方法的方式(例如均值±标准差还是中位数):
在表格下方统一底注
对每个字段分别标注
分类变量的 n(%) 显示方式:
不显示 n
显示加权后的 N
显示未加权的 n

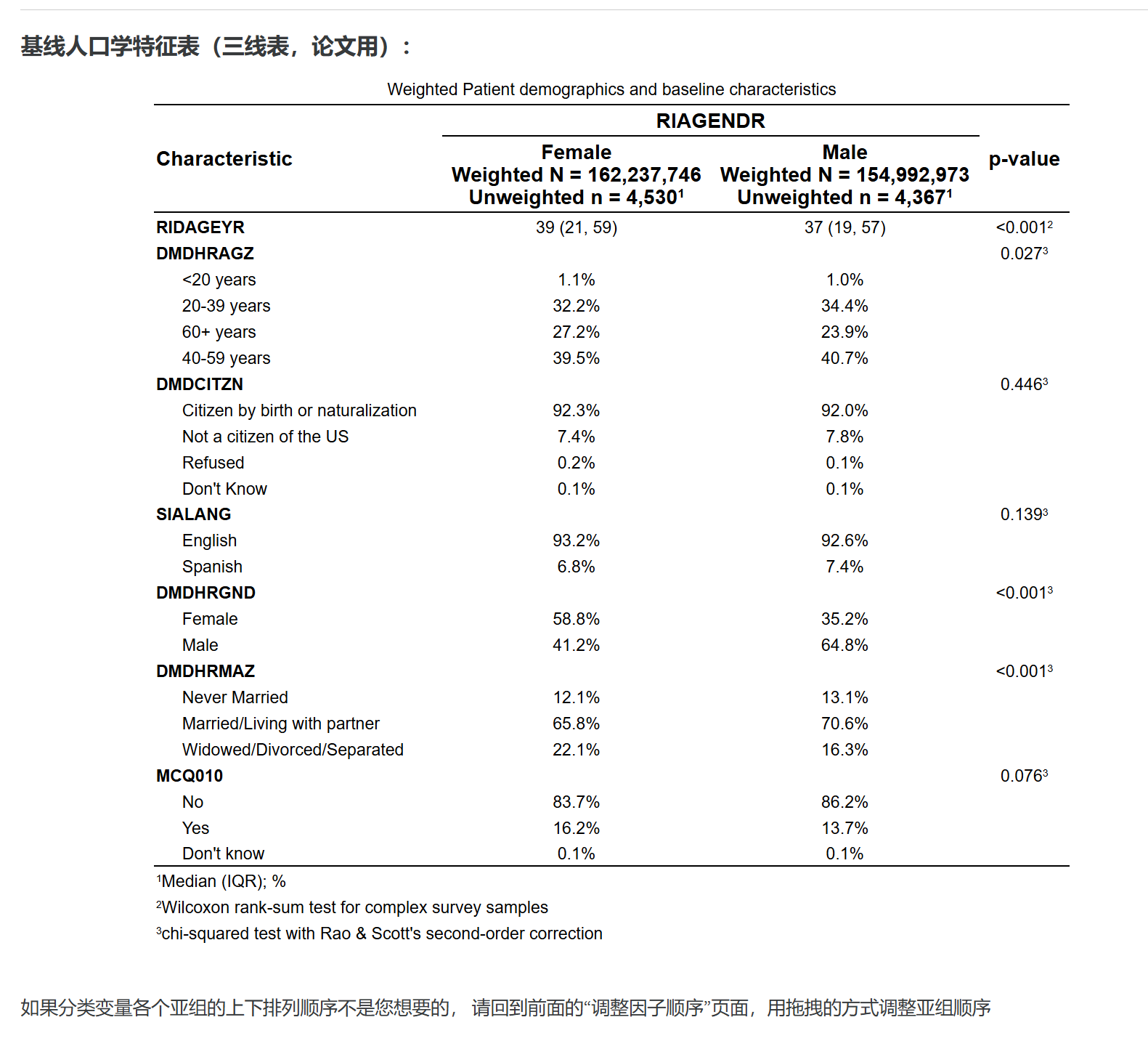
8.2 单因素+多因素回归分析表(复杂抽样加权,svy-Linear/svy-Logistic/svy-olr/svy-Cox/svy-Poisson回归)
8.2.1 背景知识
在研究中,我们通常感兴趣的是量化某些群体特征,例如某种病症的患病率、某一测量值的平均值,或暴露与疾病之间的关联性。通常,我们会在总体中抽取一个样本,并利用样本中的信息对总体特征进行推断。样本单位可以是个人、社区、医院、县甚至国家。
8.2.1.1 简单随机抽样
简单随机抽样是一种最基础的抽样方法,其特点是总体中每个单位被选中的概率相等。这种方法的优点是计算简单,分析方便,且能够保证样本统计量是总体参数的无偏估计。
例子:假设我们要研究一个城市中居民的平均收入。我们可以将这个城市的所有居民列成一个清单,然后随机选取其中的100人进行调查。每个居民被选中的概率都是相同的。在这种设计下,样本均值、样本方差等统计量都是总体参数的无偏估计,可以直接用来推断总体。
8.2.1.2 复杂抽样设计
许多调查使用复杂抽样设计而非简单随机抽样。这有多种原因。例如,如果构建列出总体中每个单位的抽样框架很困难或可能导致错误,可以使用多阶段抽样,先抽取较大且易于列出的单位群体,然后在每个群体内调查某些或全部单位,这样可以在现场构建准确的抽样框架。在多阶段抽样中,首先抽取主抽样单位(PSU)(例如,家庭),然后在每个PSU内抽取单位(例如,家庭中的个体)。当然,可以有超过两个阶段的抽样。早期阶段的单位形成簇。
另一个使用复杂抽样设计的原因是简单随机样本可能会导致某些感兴趣的子群体样本量过小。例如,如果关注种族/民族特定的平均血压,研究人员可能希望增加较小子群体的样本量。简单随机样本可能会导致多数种族/民族的样本量较大,而少数群体的样本量较小。与其增加总体样本量以确保较小群体的足够样本量,不如使用不等概率抽样对大群体进行欠抽样,对小群体进行过抽样,这样更具成本效益。
一种不等概率抽样的方法是在一些多阶段抽样设计中按比例概率抽样(PPS),其中较大的PSU有更大的被选中概率。另一种是分层随机抽样,即首先将总体非随机地分成若干层(例如,地理区域),然后在每层内进行简单随机抽样。将总体分层成不等大小的层,然后在每层内进行简单随机抽样,会导致不等概率抽样,因为较小层中的个体有更大的被选中概率。
8.2.1.3 NHANES
国家健康与营养检查调查(NHANES)是一个具有复杂设计的调查的例子。
NHANES样本不是简单随机样本,而是使用复杂的多阶段概率抽样设计来选择参与者,以代表美国民间非机构化人口。还对某些人口子群体进行过度抽样,以提高这些特定子群体健康状况指标估计的可靠性和精确性。研究人员需要在分析中适当指定抽样设计参数。
简而言之,NHANES采用了分层四阶段抽样设计。首先,根据人口普查区域和其他地理信息构建分层(非随机)。在每个分层内,随机选取美国县(PSU),较大的县有更大的被选中概率。在县内,按比例选取街区。在街区内,随机选取家庭,并对某些年龄、种族和收入群体进行过度抽样(较高的选中概率)。最后,在家庭内随机选取个体。有关NHANES复杂抽样设计的完整描述,请参见官方NHANES教程。
NHANES网站提供了使用survey软件包分析NHANES数据的示例R代码,以及在分析NHANES数据时的一些特殊考虑。
8.2.2 准备数据
NHANES数据的下载地址在 https://wwwn.cdc.gov/nchs/nhanes/
这里我们可以点击下方下载一段样例数据片段来做测试:
在本说明书中,我们使用了2017周期的NHANES数据,因此以下信息来自该周期。数据集中包含以下变量以考虑抽样设计:
分层变量(SDMVSTRA):共有15个分层。
主要抽样单位(SDMVPSU)
访谈抽样权重(WTINT2YR)
检查抽样权重(WTMEC2YR)
空腹子样本抽样权重(WTSAF2YR):
在使用NHANES数据时,请务必查阅相关数据文档和代码手册,以确保使用适当的抽样权重。
8.2.3 进入模块
接下来我们进入模块,点击软件顶部菜单的“复杂抽样加权(NHANES等)”,然后点击“单因素+多因素回归分析表(复杂抽样加权,svy-Linear/svy-Logistic/svy-olr/svy-Cox/svy-Poisson回归)” 进入模块。
进入软件界面,首先进行如下设置:
8.2.3.1 设置复杂抽样参数
请按照以下步骤设置您的复杂抽样参数:
选择分层变量
在设置界面中,找到“请选择代表分层(strata)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的分层信息。例如,在NHANES数据库中,这个变量通常是SDMVSTRA。
背景知识:分层抽样(Stratified Sampling)是一种将总体分为若干个互不重叠的层,然后在每个层内进行随机抽样的方法。这种方法可以提高估计的精确性,特别是在总体内部具有较大异质性的情况下。例如,在NHANES中,不同地理区域(如不同的州或县)可能存在健康状况的差异,通过分层抽样可以确保每个区域的代表性。
如果您的数据不需要分层,请选择“无”。
选择主抽样单位(PSU)变量
选择完分层变量后,系统会自动弹出“请选择代表主抽样单位(id)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的主抽样单位(PSU)。例如,在NHANES数据库中,这个变量通常是SDMVPSU。
背景知识:主抽样单位(Primary Sampling Unit, PSU)是多阶段抽样中的第一层单位。在NHANES中,PSU通常是县或县级等价单位。在每个PSU内,再进一步抽取次级单位(如家庭或个人)。这种方法可以减少调查成本,提高抽样效率。
确保所选变量不同于分层变量。
选择权重变量
选择完PSU变量后,系统会自动弹出“请选择代表权重(weights)的变量”选项。
从下拉菜单中选择一个权重变量。权重变量有助于确保样本的代表性。在NHANES数据库中,常见的权重变量有WTINT2YR、WTMEC2YR等。
背景知识:权重(Weights)是用于调整样本统计量以反映总体参数的因子。在复杂抽样设计中,由于不同单位被抽中的概率不同,直接使用样本统计量可能会产生偏差。权重的作用是校正这种偏差,使估计值更接近于总体参数。例如,在NHANES中,不同个体的被抽中概率不同,通过使用合适的权重,可以确保结果具有全国代表性。
选择权重的指南(简化版,仅做示例):
访谈权重(WTINT2YR):如果您的分析仅使用在访谈中收集的数据,则选择此权重。每个参与者都接受了访谈,因此每个人的访谈抽样权重都大于0。
检查权重(WTMEC2YR):如果您的分析包含体检数据,则应选择此权重。大多数参与者在移动检查中心(MEC)接受了体检,收集了客观测量数据。
空腹子样本权重(WTSAF2YR):如果您的分析包含空腹血液测量数据,则应选择此权重。只有部分参与者在空腹状态下提供了血液样本,因此需要使用相应的权重进行调整。
注意:选择权重变量非常复杂,以上只是一个简要规则,实际规则比这个复杂,请务必登录和参考NHANES官网的说明书,对于选择哪个权重有详细的规则说明,以确保选择适当的权重。
处理权重缺失值
在权重变量选择下方,您需要选择如何处理权重变量中的缺失值。
选项包括:
将权重缺失值用0填充
将权重缺失的数据整行删除
将权重缺失以及权重≤0的数据整行删除(Cox回归请勾选此项)
背景知识:在调查数据中,权重缺失值可能会影响分析结果的准确性。不同处理方法可以应对不同的分析需求和数据质量问题。例如,将缺失值填充为0可以保留数据行,但可能导致偏差;而删除权重缺失的数据则可以提高结果的准确性,但会减少样本量。
设置嵌套集群标识(Nest)
选择是否应用嵌套集群标识。如果您的数据集的ID值在分层中是嵌套的(如NHANES数据库),推荐选择“是”。
选择“是”可以确保在每个分层内,集群ID是唯一的,避免分析时出现问题。
背景知识:嵌套集群(Nested Clusters)是指在复杂抽样设计中,主抽样单位ID在不同分层内可能重复。通过设置嵌套集群标识,可以确保每个分层内的集群ID是唯一的,从而避免在数据分析时出现混淆和错误。例如,在NHANES中,不同地理区域可能有相同的PSU ID,通过嵌套设置可以确保分析的准确性。
8.2.4 影响因素分析
下一步就是影响因素分析啦:
8.2.4.1 选择结局变量
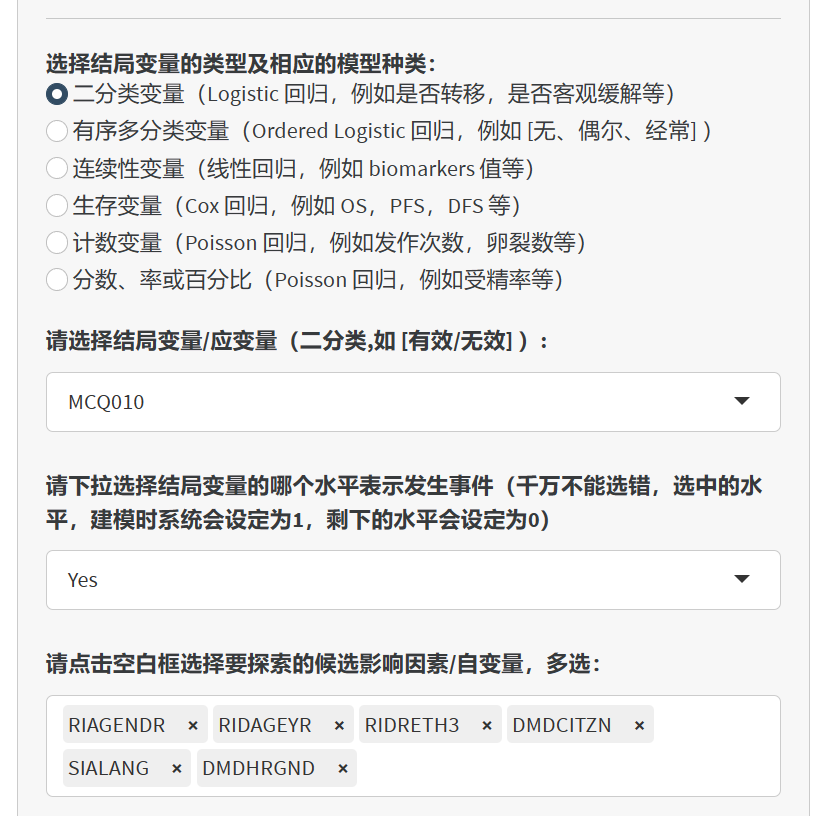
机器人根据结局变量的类型来选择分析方法。二分类变量,系统会选择logistic回归,如果是连续性变量,系统会选择一般线性回归。如果是生存变量Time和Status的组合,系统会采用Cox回归。如果是计次计数变量,系统会选择Poisson回归,当然如果是率或者百分比,也会采用Poisson/负二项回归。
8.2.4.2 选择影响因素变量
根据提示选择结局变量和影响因素变量,最后点击”生成/更新影响因素按钮”即可。这里要注意的是,如果上传的数据Excel文件里把连续性变量设置成了字符型,如年龄设置成了字符型,需要在前面”选择字段”功能里改回成numeric,如果按照分类变量放进影响因素分析,会因为分类巨多把服务器卡死。同理,如果把ID号也作为分类变量放进影响因素,服务器也容易卡顿死机。
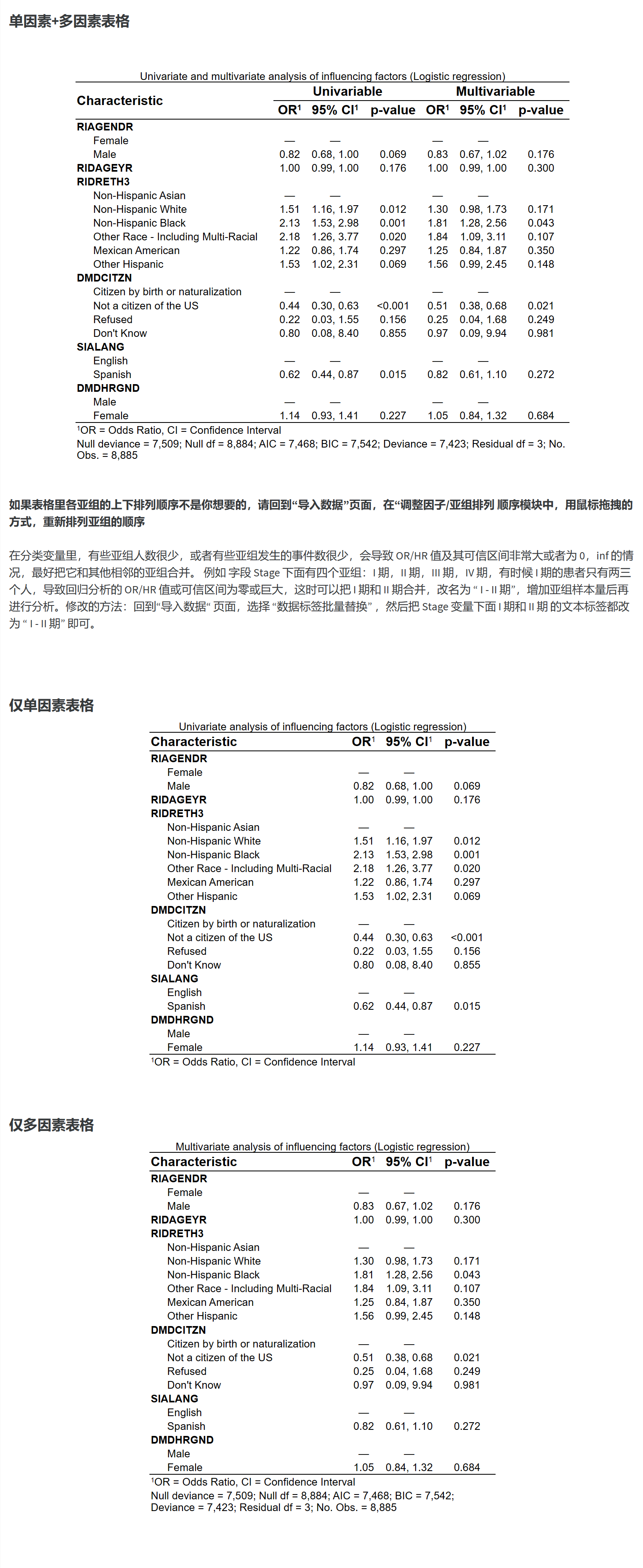
另外,在分类变量里,有些亚组人数很少,最好把它和其他亚组合并之后再传上来分析,亚组人数太少容易让可信区间特别宽,影响排版。当然,后续我们也会增加一个合并亚组的小工具。
8.2.4.3 哪些变量入选多因素模型
单因素和多因素分析时同时自动完成的。事先可以规定哪些变量从单因素模型入选多因素模型,可以选择全部都进入,或者部分筛选进入。一般可以全部都纳入多因素。但如果因素太多,十几个几十个,那就要筛选一下变量了,放入模型的变量数不应该超过 样本量N/20。我们的经验是放十个以下就可以了。 如果只放部分单因素变量进入多因素,可以点”选项2”,自行选择哪些变量纳入多因素分析,这时候主要是参考历史研究以及研究者的临床经验。另外也可以选逐步回归,StepAIC,然后系统会自动用backward法筛选纳入多因素的变量组合,筛选的标准是让模型的AIC最小。
当然,最好的方法可能是lasso 回归选择变量功能,这里我们郑重推荐本站另一个APP:“自动筛选单因素进入多因素模型变量” 的模块。大家可以在 www.mstata.com 网站进入Mstata医学统计机器人,在”影响因素研究” 菜单下可以找到,里面包括了逐步回归、最佳子集、lasso、岭回归、弹性网络等多种变量筛选方法,以及对多重共线性的判定。在另一个APP中完成变量筛选后,可以用筛选出来的变量,回到本APP这里,选择2,手工填入要进入多因素模型的变量,即可完成变量筛选。
8.2.4.4 连续性变量拆成分类变量
连续性变量需要拆成分类变量的场景有:
- 本身就是一个分类变量,如 I 期,II 期,III 期,IV 期等,只不过用了数字1,2,3,4来表示,这可以在前面筛选变量的界面直接把它设置为分类变量即可。
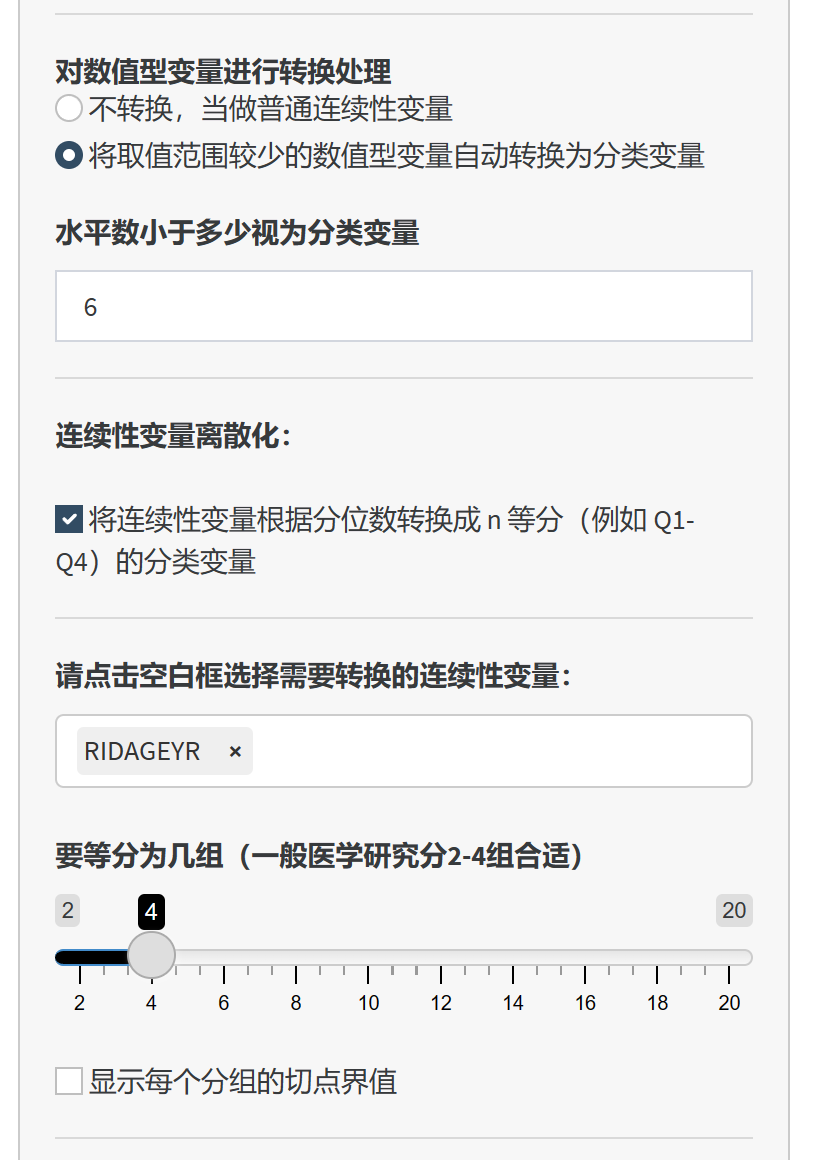
前面如果忘记了,或者不方便,这里提供了一个功能,可以设置唯一取值数小于多少个水平的变量,全部转换成分类变量。例如只有5个取值 (比如只有数字1-5可取)以下的变量,全部批量转换成分类变量;
- 本身是连续性变量,例如年龄、血糖等等,但需要转换成 低、高的二分类变量,或低、中、高的三分类变量,或Q1,Q2,Q3,Q4的四分位数分类变量,这里也提供了一个自动化转换工具,可以根据患者数量,平均拆分成N个组。
如图,对于只能取值6以下的变量,统统变成分类变量。
如上图,将 RIDAGEYR 连续性变量,切成四等分的分类变量
结果如下:
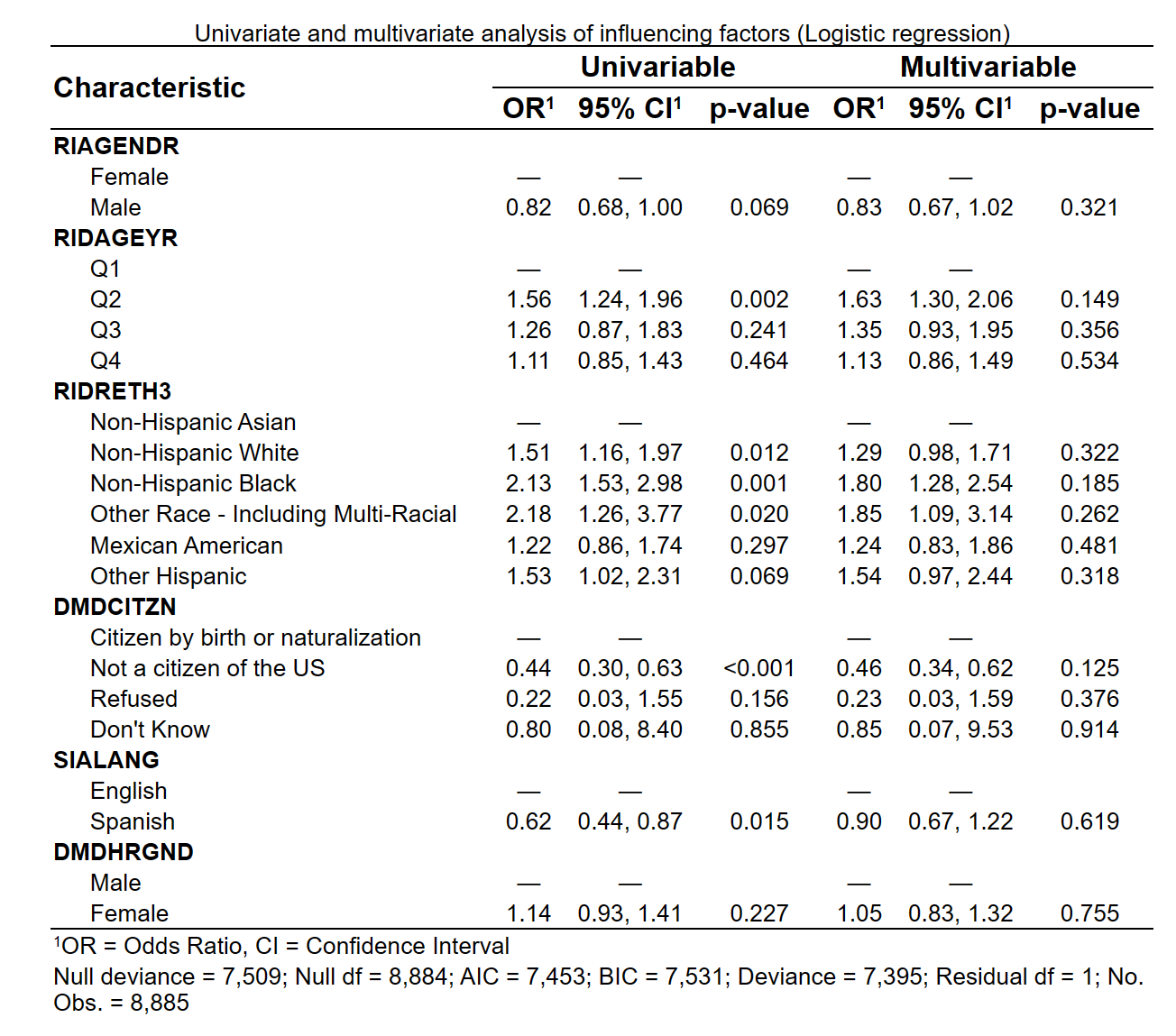
需要注意的是,Q1-Q4是根据整个数据集中的RIDAGEYR 进行分割的,如果其他变量有缺失数据,会导致最终纳入多因素分析的样本量减少,从而导致 RIDAGEYR 在单因素分析中是四等分的,在多因素分析中就不是四等分了。因此推荐进行缺失值填补。
另外也可以勾选显示分组的界值点:
结果如下:
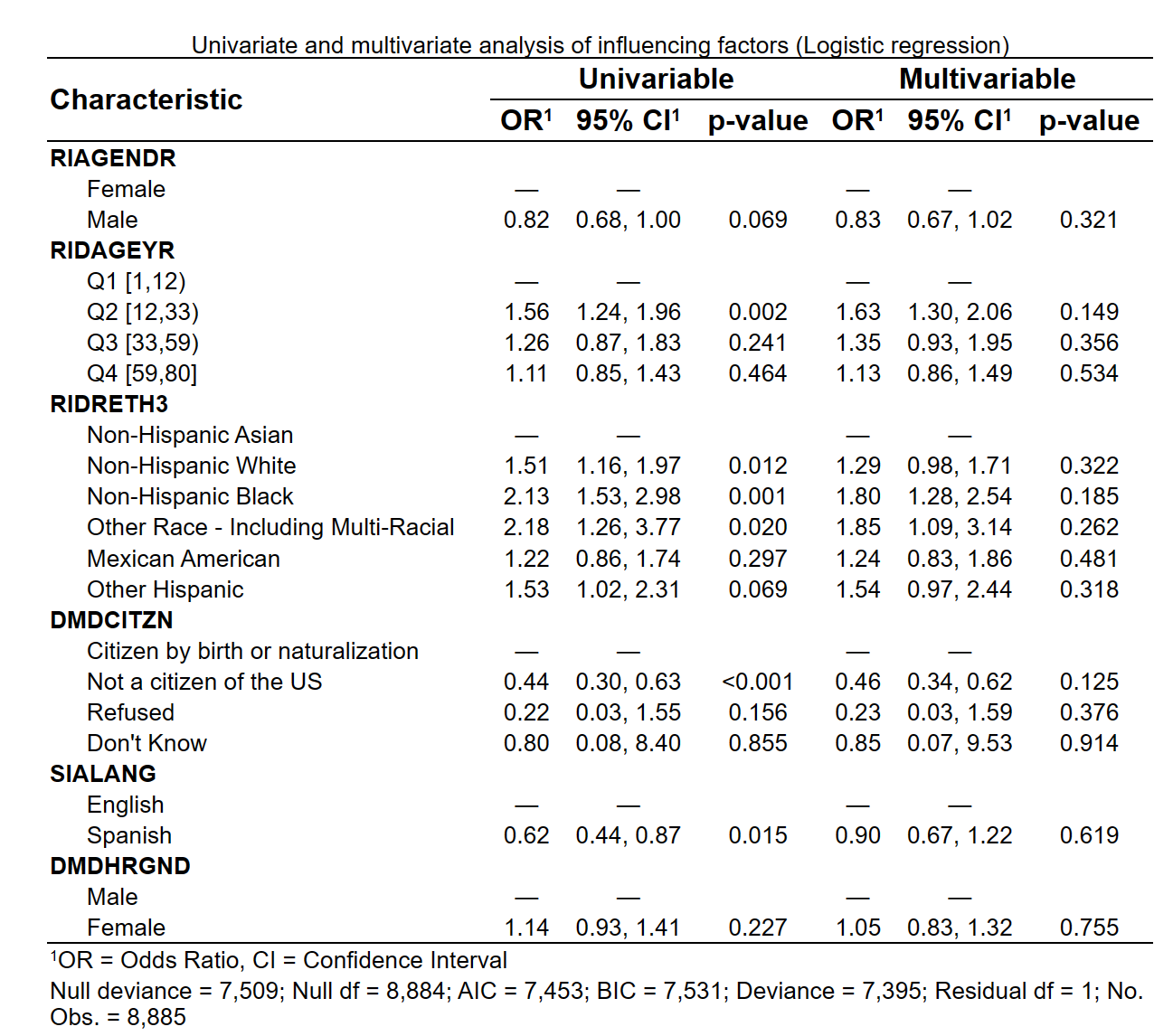
显示了切割分界点的界值。
多大支持切割成20组,因为更多分组没有太大医学价值。
如果需要更强大的分组功能呢,例如自定义切割点,如<10岁,>65岁等,或者用K-means 聚类分组等,可以去本站的 数据预处理模块,选择”数据离散化” 模块进行复杂的分组操作。
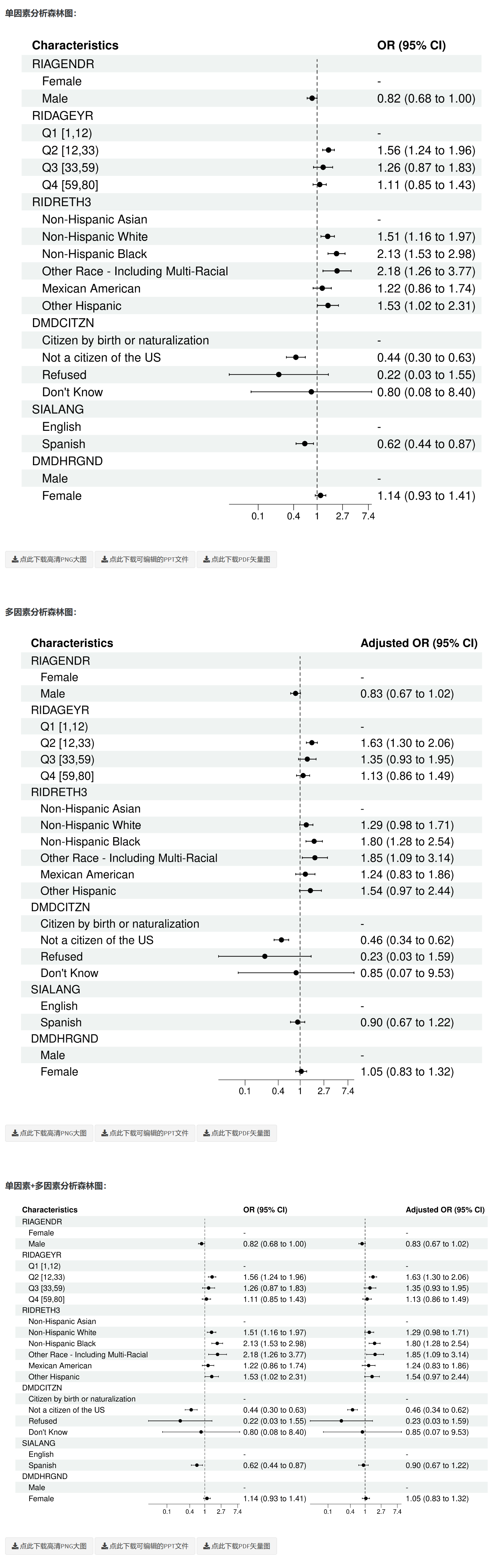
8.3 回归分析的亚组分析(复杂抽样加权,svy-Linear/svy-Logistic/svy-Cox/svy-Poisson回归)
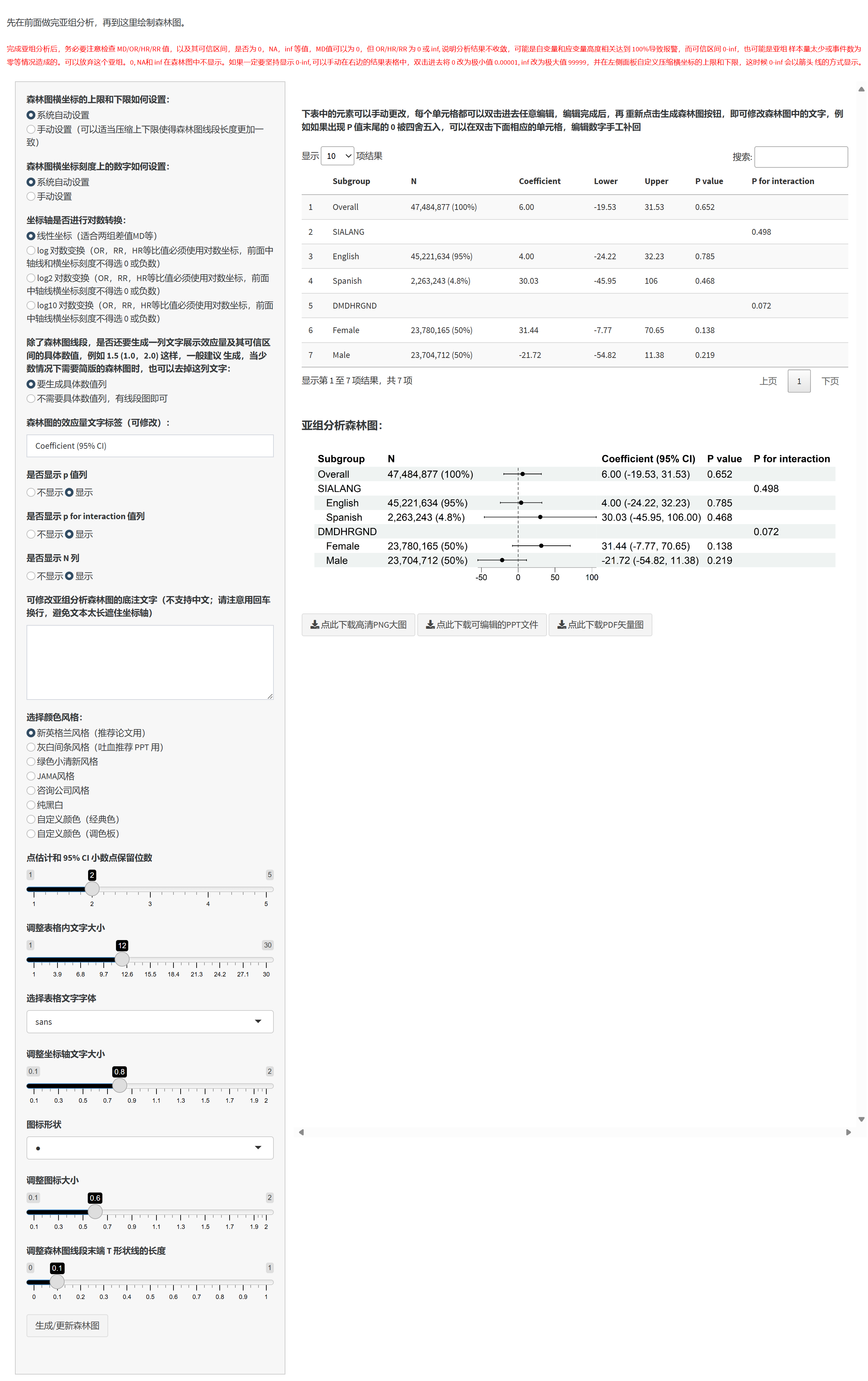
8.3.1 一键完成复杂抽样加权(NHANES 等)回归分析的亚组(分层)分析的论文发表级(Publication - ready) 表格:
当自变量为二分类(高中,高中以上两组)时:
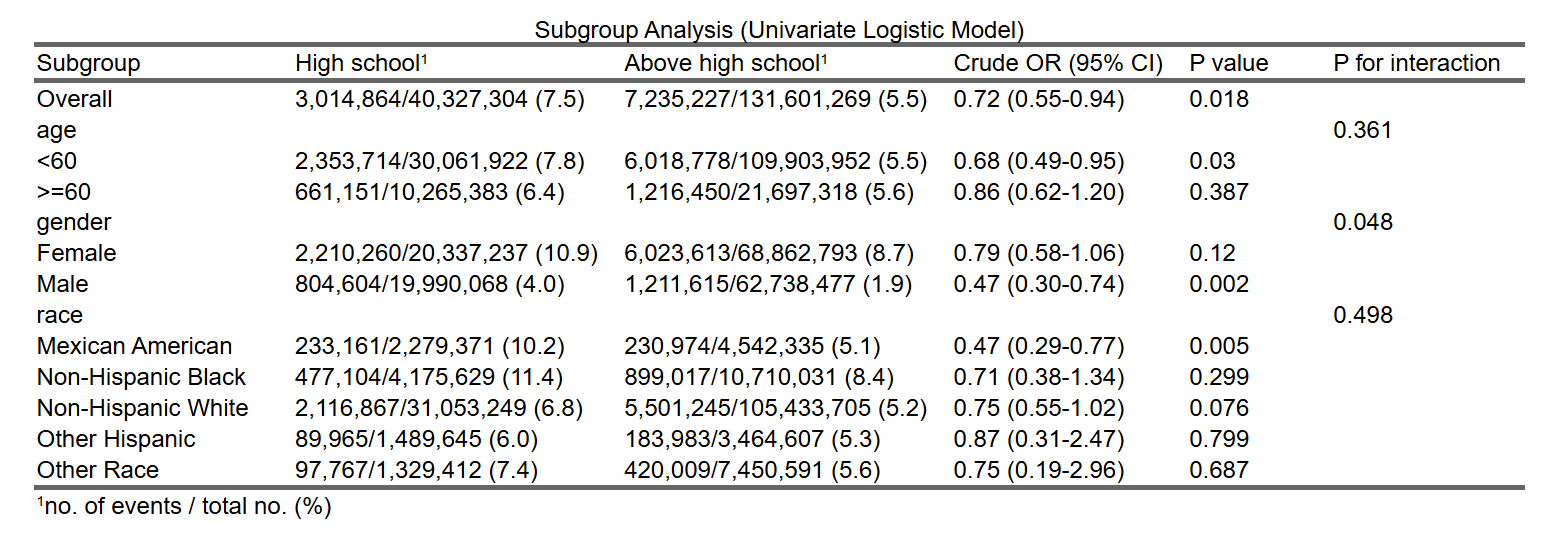
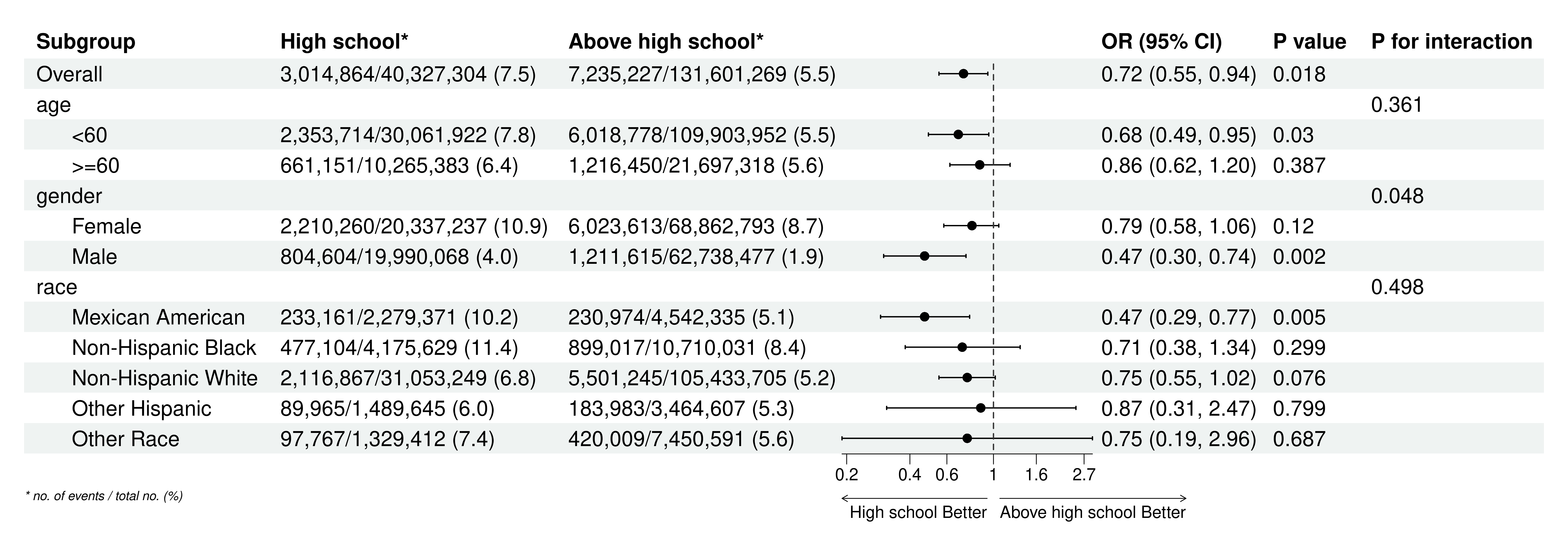
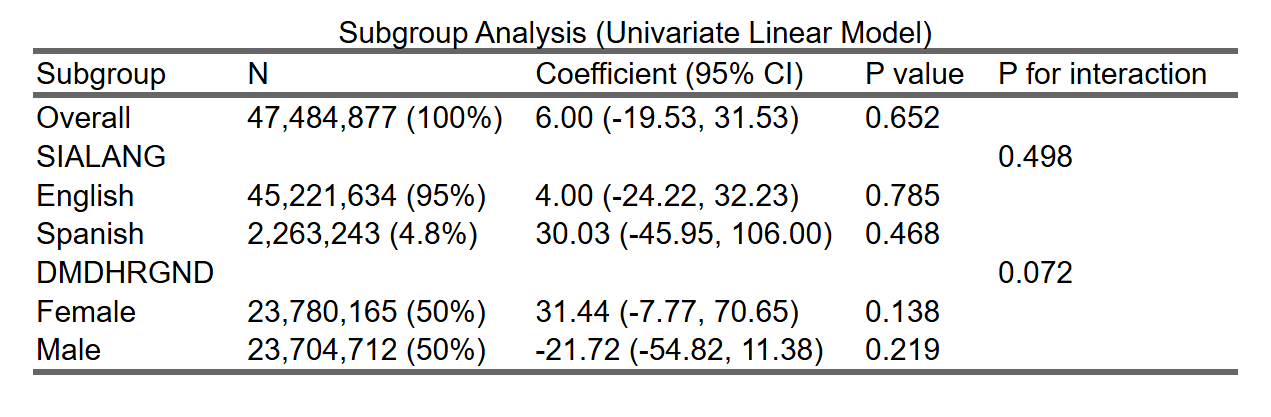
当自变量为 连续性变量(年龄):
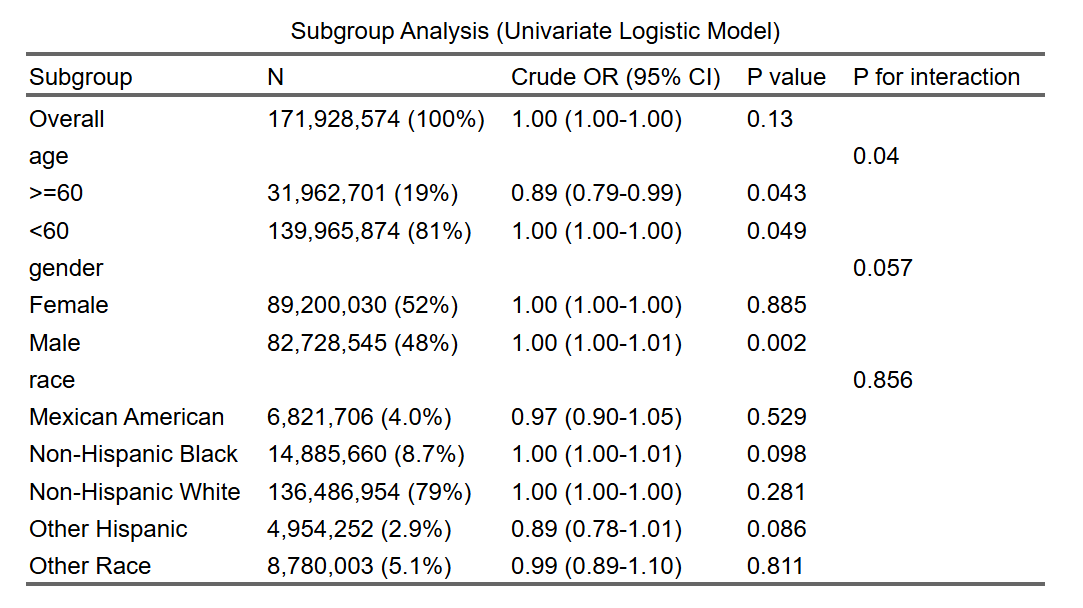
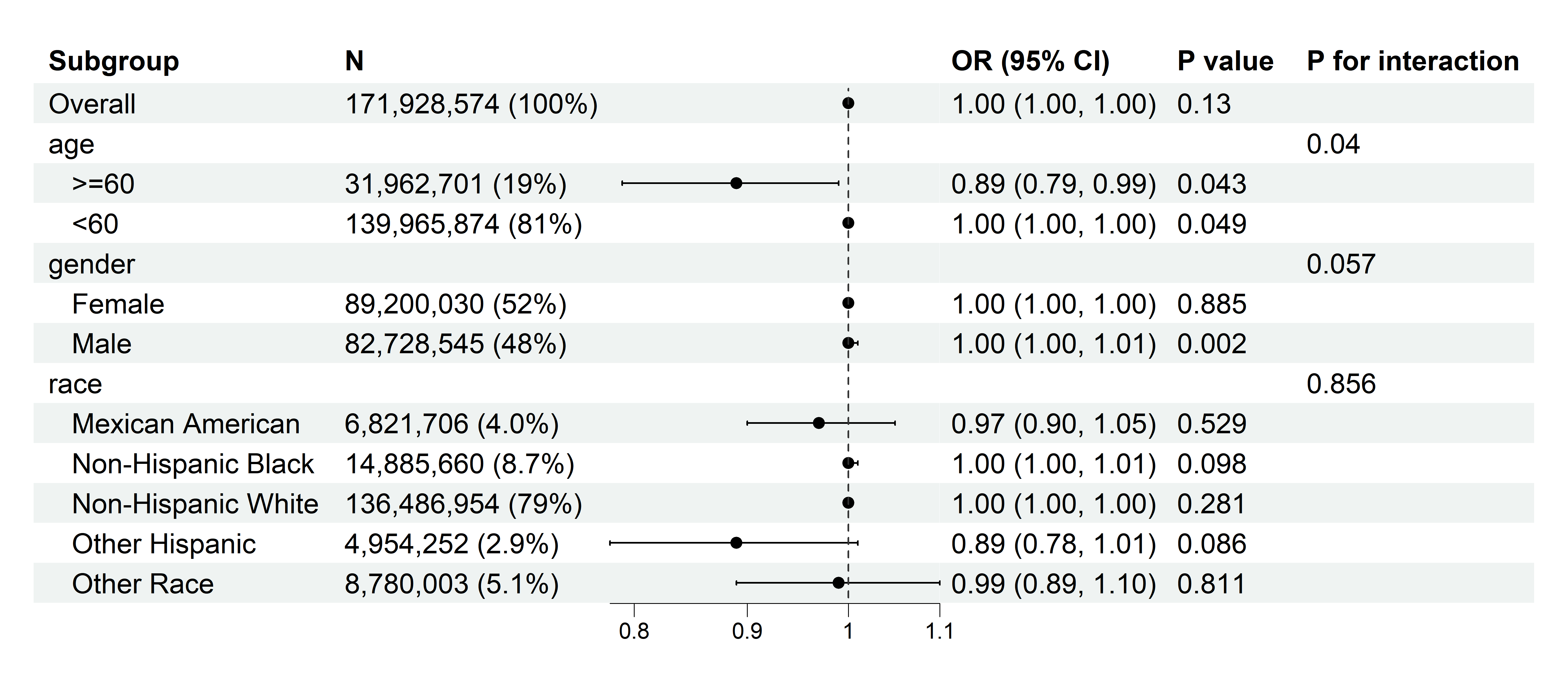
8.3.2 复杂抽样设计
许多调查使用复杂抽样设计而非简单随机抽样。这有多种原因。例如,如果构建列出总体中每个单位的抽样框架很困难或可能导致错误,可以使用多阶段抽样,先抽取较大且易于列出的单位群体,然后在每个群体内调查某些或全部单位,这样可以在现场构建准确的抽样框架。在多阶段抽样中,首先抽取主抽样单位(PSU)(例如,家庭),然后在每个PSU内抽取单位(例如,家庭中的个体)。当然,可以有超过两个阶段的抽样。早期阶段的单位形成簇。
另一个使用复杂抽样设计的原因是简单随机样本可能会导致某些感兴趣的子群体样本量过小。例如,如果关注种族/民族特定的平均血压,研究人员可能希望增加较小子群体的样本量。简单随机样本可能会导致多数种族/民族的样本量较大,而少数群体的样本量较小。与其增加总体样本量以确保较小群体的足够样本量,不如使用不等概率抽样对大群体进行欠抽样,对小群体进行过抽样,这样更具成本效益。
一种不等概率抽样的方法是在一些多阶段抽样设计中按比例概率抽样(PPS),其中较大的PSU有更大的被选中概率。另一种是分层随机抽样,即首先将总体非随机地分成若干层(例如,地理区域),然后在每层内进行简单随机抽样。将总体分层成不等大小的层,然后在每层内进行简单随机抽样,会导致不等概率抽样,因为较小层中的个体有更大的被选中概率。
8.3.3 NHANES
国家健康与营养检查调查(NHANES)是一个具有复杂设计的调查的例子。
NHANES样本不是简单随机样本,而是使用复杂的多阶段概率抽样设计来选择参与者,以代表美国民间非机构化人口。还对某些人口子群体进行过度抽样,以提高这些特定子群体健康状况指标估计的可靠性和精确性。研究人员需要在分析中适当指定抽样设计参数。
简而言之,NHANES采用了分层四阶段抽样设计。首先,根据人口普查区域和其他地理信息构建分层(非随机)。在每个分层内,随机选取美国县(PSU),较大的县有更大的被选中概率。在县内,按比例选取街区。在街区内,随机选取家庭,并对某些年龄、种族和收入群体进行过度抽样(较高的选中概率)。最后,在家庭内随机选取个体。有关NHANES复杂抽样设计的完整描述,请参见官方NHANES教程。
NHANES网站提供了使用survey软件包分析NHANES数据的示例R代码,以及在分析NHANES数据时的一些特殊考虑。
8.3.4 亚组(分层)分析的定义和概念
亚组分析是指在总体研究样本中,根据某些特征将样本划分为若干亚组,并在每个亚组内进行独立的分析。其目的是探讨不同亚组在某些特定特征下的差异,揭示出整体分析中可能被忽视的细节。亚组分析通常应用于回归分析之后,以进一步细化研究结果,使其更具针对性和实用性。
8.3.5 为什么回归分析之后要做亚组分析?
虽然回归分析可以揭示总体样本的趋势和关系,但不同特征(如年龄、性别、疾病分期等)可能对结果有不同的影响。通过亚组分析,我们可以:
识别异质性:揭示不同亚组之间的差异,识别是否存在某些亚组对治疗或干预有不同的反应。
提高结果的外推性:通过细分亚组,研究结果更能代表不同特征人群,提高其外推性。
制定个性化治疗策略:在医学研究中,不同亚组的患者可能需要不同的治疗方法,亚组分析可以帮助制定更为精准的治疗策略。
8.3.6 医学研究的例子
8.3.6.1 自变量为二分类变量的例子
例如,在一项研究中,探讨两种药物(药物A和药物B)对某种疾病的治疗效果。研究者首先进行总体样本的回归分析,得出药物A和药物B在总体人群中的效果。然而,考虑到疾病的分期和等级可能影响药物效果,研究者进一步进行亚组分析,将样本根据疾病的分期(如T1、T2、T3、T4)和等级(如I、II、III)分为不同亚组,分别分析各亚组内两种药物的效果。
通过亚组分析,研究者发现:
在疾病分期为T1的亚组中,药物A的效果优于药物B。
在等级为I的亚组中,药物B的效果显著优于药物A。 这种细化的分析结果可以帮助医生根据患者的具体情况选择更合适的药物。
8.3.6.2 自变量为连续变量的例子
例如,在一项研究中,探讨患者的血糖水平(一个连续变量)对心脏病风险的影响。研究者首先进行总体样本的回归分析,得出血糖水平与心脏病风险之间的关系。然而,考虑到不同性别和年龄段可能影响血糖水平与心脏病风险之间的关系,研究者进一步进行亚组分析。
研究者将样本按性别(男性和女性)和年龄段(如年轻组、中年组和老年组)分为不同亚组,然后分别分析在不同亚组中,血糖水平对心脏病风险的影响。
通过这种分析,研究者可能会发现:
在男性老年组中,血糖水平较高与心脏病风险显著增加相关。
在女性年轻组中,血糖水平与心脏病风险之间没有显著相关性。
这种分析有助于了解在不同性别和年龄段中,血糖水平对心脏病风险的具体影响,从而帮助制定更加个性化的预防和治疗策略。
8.3.7 P值和P for interaction的意义
在亚组分析中,P值和P for interaction是两个重要的统计指标:
P值:在每个亚组内,P值用于检验在该亚组中自变量(如血糖水平)与结果变量(如心脏病风险)之间的关系是否显著。P值越小,说明关系越显著。通常,P值小于0.05被认为有统计学显著性。
P for interaction:P for interaction用于检验不同亚组之间的效果是否有显著差异。它衡量的是自变量(如血糖水平)与亚组变量之间的交互作用。如果P for interaction值小于0.05,说明不同亚组间的效果差异具有统计学显著性,这意味着血糖水平对心脏病风险的影响在不同亚组中有显著差异。
总之,亚组分析通过细化研究对象,揭示了不同特征人群的差异,帮助制定更为精准的治疗策略。P值和P for interaction则为这种差异提供了统计学依据,使研究结果更为可靠和科学。
8.3.8 准备数据
NHANES数据的下载地址在 https://wwwn.cdc.gov/nchs/nhanes/
这里我们可以点击下方下载一段样例数据片段来做测试:
在本说明书中,我们使用了2017周期的NHANES数据,因此以下信息来自该周期。数据集中包含以下变量以考虑抽样设计:
分层变量(SDMVSTRA):共有15个分层。
主要抽样单位(SDMVPSU)
访谈抽样权重(WTINT2YR)
检查抽样权重(WTMEC2YR)
空腹子样本抽样权重(WTSAF2YR):
在使用NHANES数据时,请务必查阅相关数据文档和代码手册,以确保使用适当的抽样权重。
8.3.9 进入模块
接下来我们进入模块,点击软件顶部菜单的“复杂抽样加权(NHANES等)”,然后点击“回归分析的亚组分析(复杂抽样加权,svy-Linear/svy-Logistic/svy-Cox/svy-Poisson回归)” 进入模块。
进入软件界面,首先进行如下设置:
8.3.10 设置复杂抽样参数
请按照以下步骤设置您的复杂抽样参数:
选择分层变量
在设置界面中,找到“请选择代表分层(strata)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的分层信息。例如,在NHANES数据库中,这个变量通常是SDMVSTRA。
背景知识:分层抽样(Stratified Sampling)是一种将总体分为若干个互不重叠的层,然后在每个层内进行随机抽样的方法。这种方法可以提高估计的精确性,特别是在总体内部具有较大异质性的情况下。例如,在NHANES中,不同地理区域(如不同的州或县)可能存在健康状况的差异,通过分层抽样可以确保每个区域的代表性。
如果您的数据不需要分层,请选择“无”。
选择主抽样单位(PSU)变量
选择完分层变量后,系统会自动弹出“请选择代表主抽样单位(id)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的主抽样单位(PSU)。例如,在NHANES数据库中,这个变量通常是SDMVPSU。
背景知识:主抽样单位(Primary Sampling Unit, PSU)是多阶段抽样中的第一层单位。在NHANES中,PSU通常是县或县级等价单位。在每个PSU内,再进一步抽取次级单位(如家庭或个人)。这种方法可以减少调查成本,提高抽样效率。
确保所选变量不同于分层变量。
选择权重变量
选择完PSU变量后,系统会自动弹出“请选择代表权重(weights)的变量”选项。
从下拉菜单中选择一个权重变量。权重变量有助于确保样本的代表性。在NHANES数据库中,常见的权重变量有WTINT2YR、WTMEC2YR等。
背景知识:权重(Weights)是用于调整样本统计量以反映总体参数的因子。在复杂抽样设计中,由于不同单位被抽中的概率不同,直接使用样本统计量可能会产生偏差。权重的作用是校正这种偏差,使估计值更接近于总体参数。例如,在NHANES中,不同个体的被抽中概率不同,通过使用合适的权重,可以确保结果具有全国代表性。
选择权重的指南(简化版,仅做示例):
访谈权重(WTINT2YR):如果您的分析仅使用在访谈中收集的数据,则选择此权重。每个参与者都接受了访谈,因此每个人的访谈抽样权重都大于0。
检查权重(WTMEC2YR):如果您的分析包含体检数据,则应选择此权重。大多数参与者在移动检查中心(MEC)接受了体检,收集了客观测量数据。
空腹子样本权重(WTSAF2YR):如果您的分析包含空腹血液测量数据,则应选择此权重。只有部分参与者在空腹状态下提供了血液样本,因此需要使用相应的权重进行调整。
注意:选择权重变量非常复杂,以上只是一个简要规则,实际规则比这个复杂,请务必登录和参考NHANES官网的说明书,对于选择哪个权重有详细的规则说明,以确保选择适当的权重。
处理权重缺失值
在权重变量选择下方,您需要选择如何处理权重变量中的缺失值。
选项包括:
将权重缺失值用0填充
将权重缺失的数据整行删除
将权重缺失以及权重≤0的数据整行删除(Cox回归请勾选此项)
背景知识:在调查数据中,权重缺失值可能会影响分析结果的准确性。不同处理方法可以应对不同的分析需求和数据质量问题。例如,将缺失值填充为0可以保留数据行,但可能导致偏差;而删除权重缺失的数据则可以提高结果的准确性,但会减少样本量。
设置嵌套集群标识(Nest)
选择是否应用嵌套集群标识。如果您的数据集的ID值在分层中是嵌套的(如NHANES数据库),推荐选择“是”。
选择“是”可以确保在每个分层内,集群ID是唯一的,避免分析时出现问题。
背景知识:嵌套集群(Nested Clusters)是指在复杂抽样设计中,主抽样单位ID在不同分层内可能重复。通过设置嵌套集群标识,可以确保每个分层内的集群ID是唯一的,从而避免在数据分析时出现混淆和错误。例如,在NHANES中,不同地理区域可能有相同的PSU ID,通过嵌套设置可以确保分析的准确性。
8.3.14 亚组分析操作步骤
8.3.14.1 选择结局变量的类型
进入软件后,选择“回归分析”模块。
在“选择结局变量的类型”部分,根据您的研究需求,选择适合的回归模型:
二分类变量(Logistic回归,例如是否转移,是否客观缓解等)
连续性变量(线性回归,例如生物标志物值等)
生存变量(Cox回归,例如总生存期(OS),无进展生存期(PFS),无病生存期(DFS)等)
8.3.14.2 选择结局变量/应变量
根据您在第一步选择的结局变量类型,进行相应的操作:
Logistic回归:
系统会自动筛选数据库中所有的二分类变量。
在“请选择结局变量/应变量”下拉菜单中,选择您的结局变量。
线性回归:
系统会自动筛选数据库中所有的连续性变量。
在“请选择结局变量/应变量”下拉菜单中,选择您的结局变量。
Cox回归:
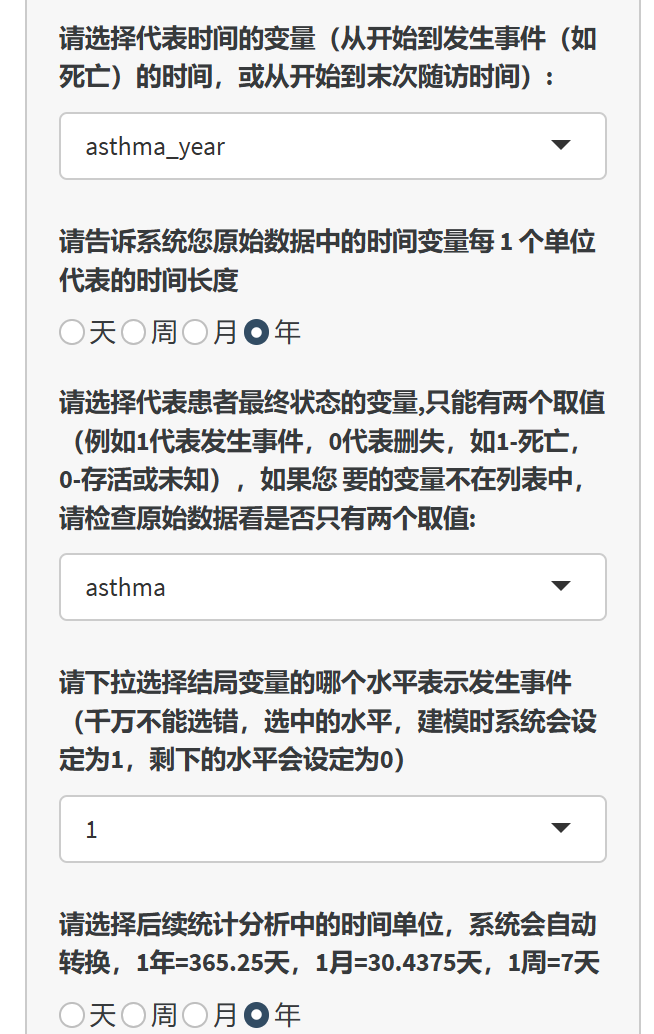
系统会自动筛选数据库中所有的连续性变量。
在“请选择代表时间的变量”下拉菜单中,选择表示时间的变量(如从开始到死亡的时间,或从开始到末次随访时间)。
系统会自动筛选数据库中所有的二分类变量。
在“请选择代表患者最终状态的变量”下拉菜单中,选择表示患者最终状态的变量(如1代表发生事件,0代表删失)。
8.3.14.3 选择结局变量的水平
Logistic回归和Cox回归:
系统会自动检测结局变量的所有水平。
在“请下拉选择结局变量的哪个水平表示发生事件”下拉菜单中,选择表示发生事件的水平(注意:选中的水平在建模时系统会设定为1,剩下的水平会设定为0)。
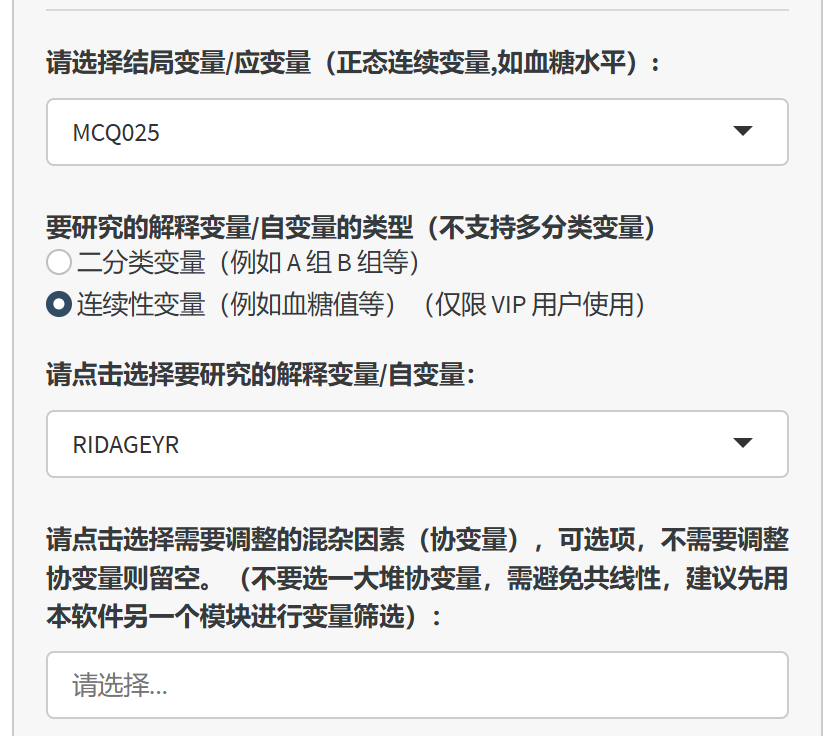
8.3.14.4 选择解释变量/自变量
在“要研究的解释变量/自变量的类型”部分,选择变量类型:
二分类变量
连续性变量
系统会根据您的选择筛选相应的变量。
在“请点击选择要研究的解释变量/自变量”下拉菜单中,选择您的解释变量/自变量。
8.3.14.5 选择参照组和观察/试验组(仅针对二分类解释变量)
系统会自动检测解释变量的所有水平。
在“请下拉选择参照组”下拉菜单中,选择参照组。
在“请下拉选择观察/试验组”下拉菜单中,选择观察/试验组。

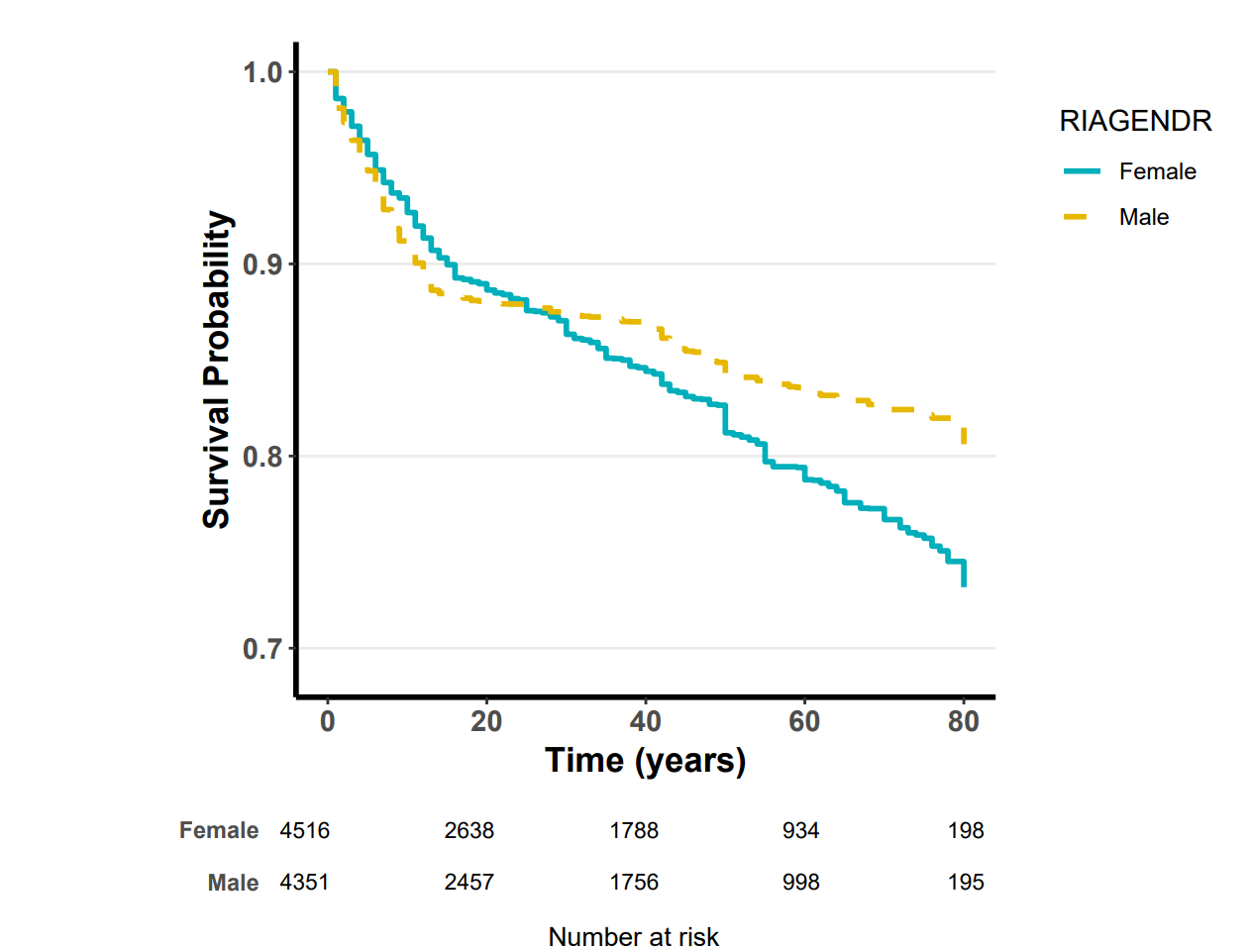
8.4 Kaplan-Meier 生存曲线(复杂抽样加权,R 软件 svykm 函数)
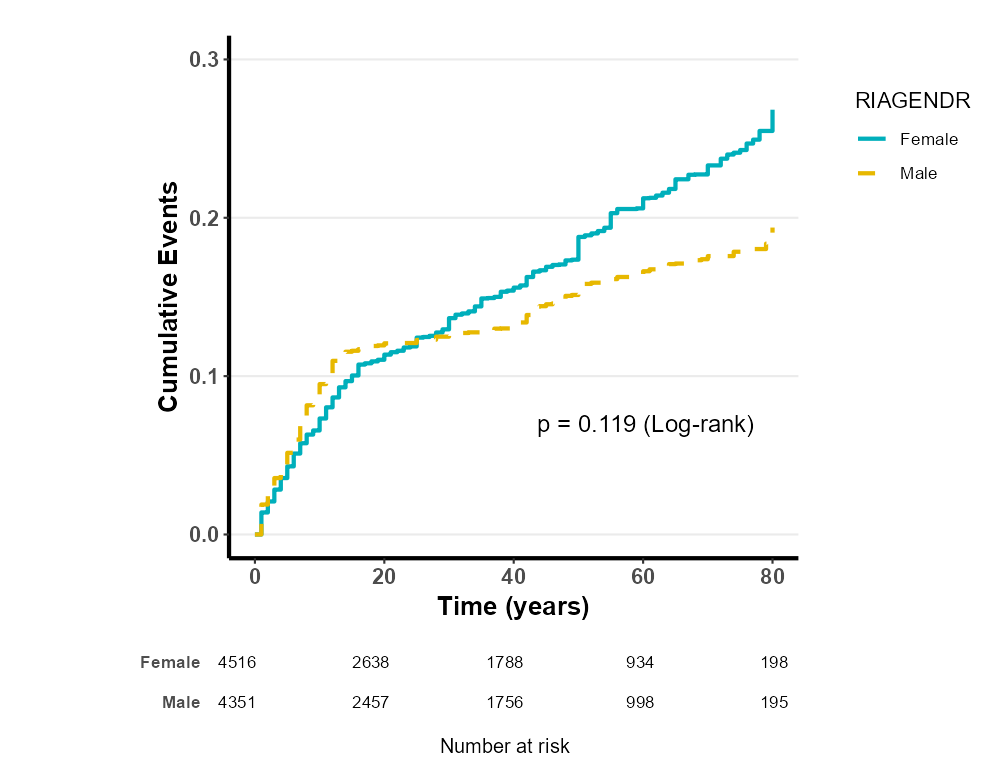
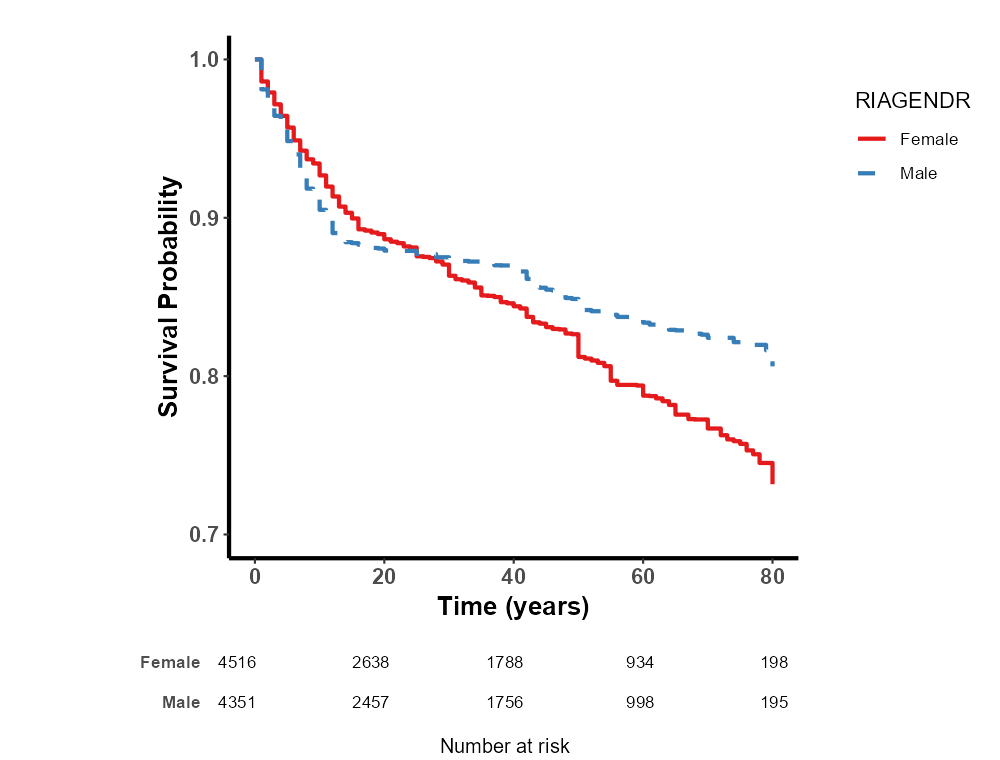
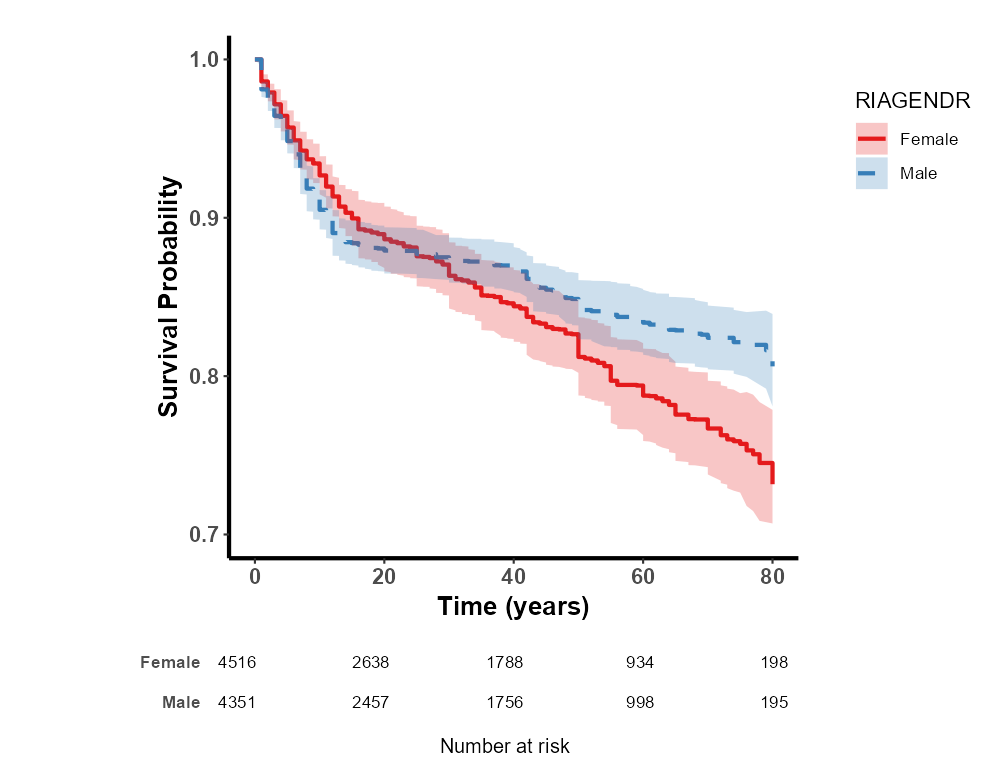
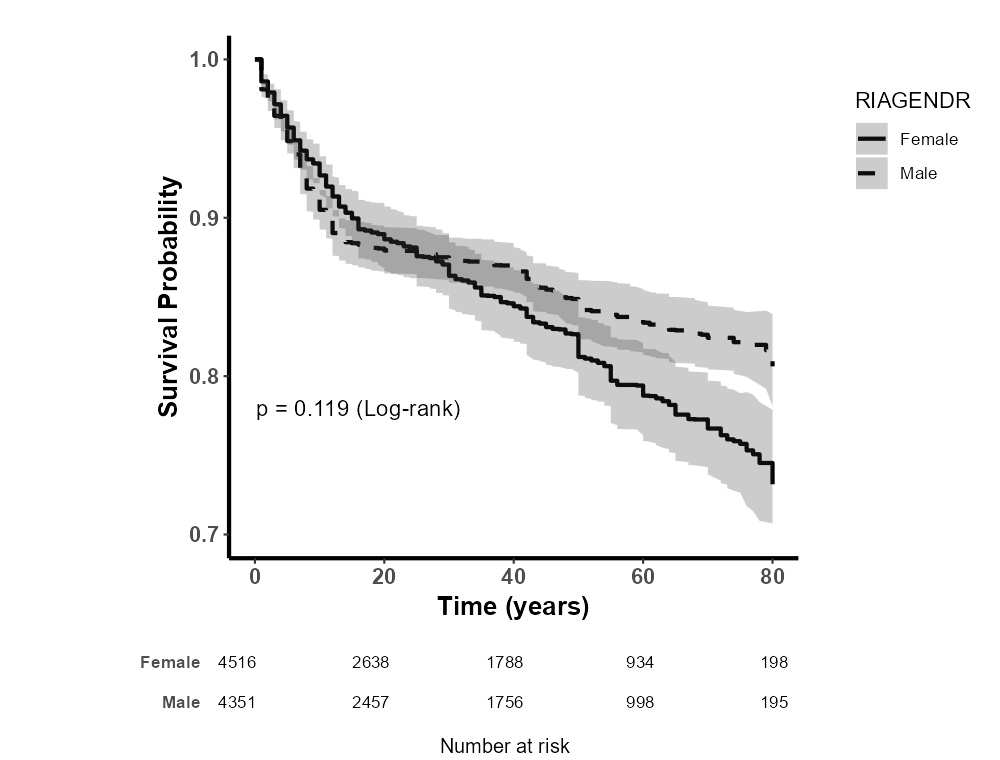
8.4.2 复杂抽样设计
许多调查使用复杂抽样设计而非简单随机抽样。这有多种原因。例如,如果构建列出总体中每个单位的抽样框架很困难或可能导致错误,可以使用多阶段抽样,先抽取较大且易于列出的单位群体,然后在每个群体内调查某些或全部单位,这样可以在现场构建准确的抽样框架。在多阶段抽样中,首先抽取主抽样单位(PSU)(例如,家庭),然后在每个PSU内抽取单位(例如,家庭中的个体)。当然,可以有超过两个阶段的抽样。早期阶段的单位形成簇。
另一个使用复杂抽样设计的原因是简单随机样本可能会导致某些感兴趣的子群体样本量过小。例如,如果关注种族/民族特定的平均血压,研究人员可能希望增加较小子群体的样本量。简单随机样本可能会导致多数种族/民族的样本量较大,而少数群体的样本量较小。与其增加总体样本量以确保较小群体的足够样本量,不如使用不等概率抽样对大群体进行欠抽样,对小群体进行过抽样,这样更具成本效益。
一种不等概率抽样的方法是在一些多阶段抽样设计中按比例概率抽样(PPS),其中较大的PSU有更大的被选中概率。另一种是分层随机抽样,即首先将总体非随机地分成若干层(例如,地理区域),然后在每层内进行简单随机抽样。将总体分层成不等大小的层,然后在每层内进行简单随机抽样,会导致不等概率抽样,因为较小层中的个体有更大的被选中概率。
8.4.3 NHANES
国家健康与营养检查调查(NHANES)是一个具有复杂设计的调查的例子。
NHANES样本不是简单随机样本,而是使用复杂的多阶段概率抽样设计来选择参与者,以代表美国民间非机构化人口。还对某些人口子群体进行过度抽样,以提高这些特定子群体健康状况指标估计的可靠性和精确性。研究人员需要在分析中适当指定抽样设计参数。
简而言之,NHANES采用了分层四阶段抽样设计。首先,根据人口普查区域和其他地理信息构建分层(非随机)。在每个分层内,随机选取美国县(PSU),较大的县有更大的被选中概率。在县内,按比例选取街区。在街区内,随机选取家庭,并对某些年龄、种族和收入群体进行过度抽样(较高的选中概率)。最后,在家庭内随机选取个体。有关NHANES复杂抽样设计的完整描述,请参见官方NHANES教程。
NHANES网站提供了使用survey软件包分析NHANES数据的示例R代码,以及在分析NHANES数据时的一些特殊考虑。
8.4.4 准备数据
NHANES数据的下载地址在 https://wwwn.cdc.gov/nchs/nhanes/
这里我们可以点击下方下载一段样例数据片段来做测试:
数据集中包含以下变量以考虑抽样设计:
分层变量(SDMVSTRA):
主要抽样单位(SDMVPSU)
访谈抽样权重(WTINT2YR)
检查抽样权重(WTMEC2YR)
空腹子样本抽样权重(WTSAF2YR):
本例中做生存曲线的相关变量:
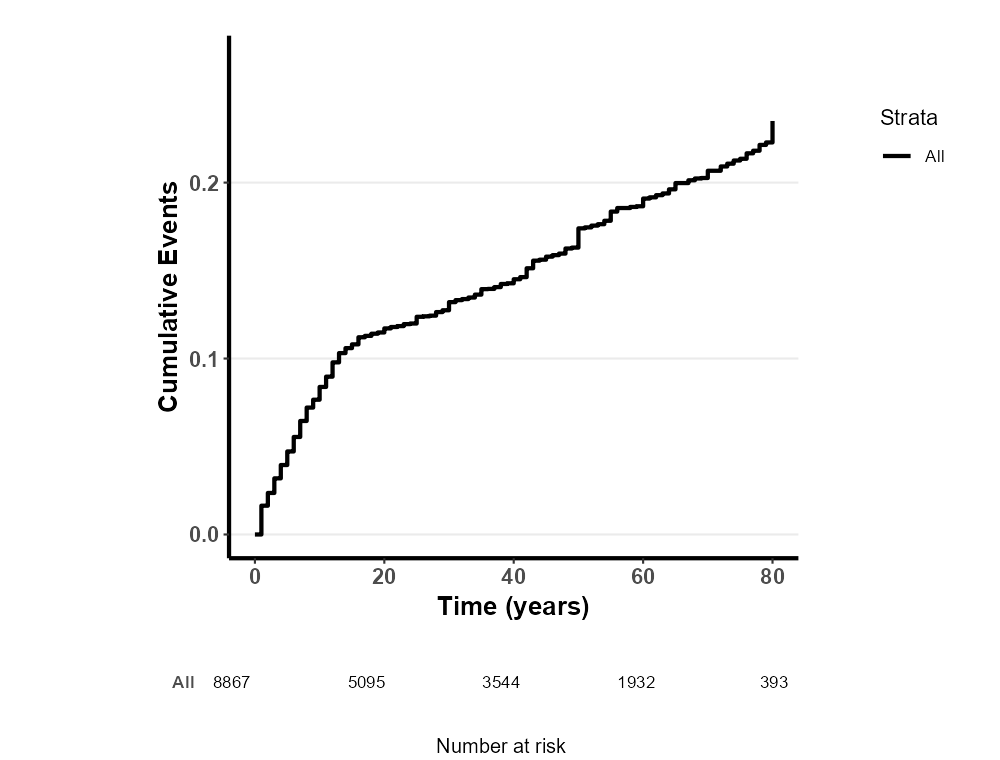
asthma:0和1,0 表示该随访对象随访结束时没有罹患哮喘;1 表示该调查对象随访结束时罹患哮喘
asthma_year:该随访对象从出生后经历多少年发展为哮喘(没有哮喘则填随访结束时的年龄)
在使用NHANES数据时,请务必查阅相关数据文档和代码手册,以确保使用适当的抽样权重。
8.4.5 进入模块
接下来我们进入模块,点击软件顶部菜单的“复杂抽样加权(NHANES等)”,然后点击“Kaplan-Meier 生存曲线(复杂抽样加权,R 软件 svykm 函数)” 进入模块。
进入软件界面,首先进行如下设置:
8.4.6 设置复杂抽样参数
请按照以下步骤设置您的复杂抽样参数:
选择分层变量
在设置界面中,找到“请选择代表分层(strata)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的分层信息。例如,在NHANES数据库中,这个变量通常是SDMVSTRA。
背景知识:分层抽样(Stratified Sampling)是一种将总体分为若干个互不重叠的层,然后在每个层内进行随机抽样的方法。这种方法可以提高估计的精确性,特别是在总体内部具有较大异质性的情况下。例如,在NHANES中,不同地理区域(如不同的州或县)可能存在健康状况的差异,通过分层抽样可以确保每个区域的代表性。
如果您的数据不需要分层,请选择“无”。
选择主抽样单位(PSU)变量
选择完分层变量后,系统会自动弹出“请选择代表主抽样单位(id)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的主抽样单位(PSU)。例如,在NHANES数据库中,这个变量通常是SDMVPSU。
背景知识:主抽样单位(Primary Sampling Unit, PSU)是多阶段抽样中的第一层单位。在NHANES中,PSU通常是县或县级等价单位。在每个PSU内,再进一步抽取次级单位(如家庭或个人)。这种方法可以减少调查成本,提高抽样效率。
确保所选变量不同于分层变量。
选择权重变量
选择完PSU变量后,系统会自动弹出“请选择代表权重(weights)的变量”选项。
从下拉菜单中选择一个权重变量。权重变量有助于确保样本的代表性。在NHANES数据库中,常见的权重变量有WTINT2YR、WTMEC2YR等。
背景知识:权重(Weights)是用于调整样本统计量以反映总体参数的因子。在复杂抽样设计中,由于不同单位被抽中的概率不同,直接使用样本统计量可能会产生偏差。权重的作用是校正这种偏差,使估计值更接近于总体参数。例如,在NHANES中,不同个体的被抽中概率不同,通过使用合适的权重,可以确保结果具有全国代表性。
选择权重的指南(简化版,仅做示例):
访谈权重(WTINT2YR):如果您的分析仅使用在访谈中收集的数据,则选择此权重。每个参与者都接受了访谈,因此每个人的访谈抽样权重都大于0。
检查权重(WTMEC2YR):如果您的分析包含体检数据,则应选择此权重。大多数参与者在移动检查中心(MEC)接受了体检,收集了客观测量数据。
空腹子样本权重(WTSAF2YR):如果您的分析包含空腹血液测量数据,则应选择此权重。只有部分参与者在空腹状态下提供了血液样本,因此需要使用相应的权重进行调整。
注意:选择权重变量非常复杂,以上只是一个简要规则,实际规则比这个复杂,请务必登录和参考NHANES官网的说明书,对于选择哪个权重有详细的规则说明,以确保选择适当的权重。
处理权重缺失值
在权重变量选择下方,您需要选择如何处理权重变量中的缺失值。
选项包括:
将权重缺失值用0填充
将权重缺失的数据整行删除
将权重缺失以及权重≤0的数据整行删除(Cox回归请勾选此项)
背景知识:在调查数据中,权重缺失值可能会影响分析结果的准确性。不同处理方法可以应对不同的分析需求和数据质量问题。例如,将缺失值填充为0可以保留数据行,但可能导致偏差;而删除权重缺失的数据则可以提高结果的准确性,但会减少样本量。
设置嵌套集群标识(Nest)
选择是否应用嵌套集群标识。如果您的数据集的ID值在分层中是嵌套的(如NHANES数据库),推荐选择“是”。
选择“是”可以确保在每个分层内,集群ID是唯一的,避免分析时出现问题。
背景知识:嵌套集群(Nested Clusters)是指在复杂抽样设计中,主抽样单位ID在不同分层内可能重复。通过设置嵌套集群标识,可以确保每个分层内的集群ID是唯一的,从而避免在数据分析时出现混淆和错误。例如,在NHANES中,不同地理区域可能有相同的PSU ID,通过嵌套设置可以确保分析的准确性。
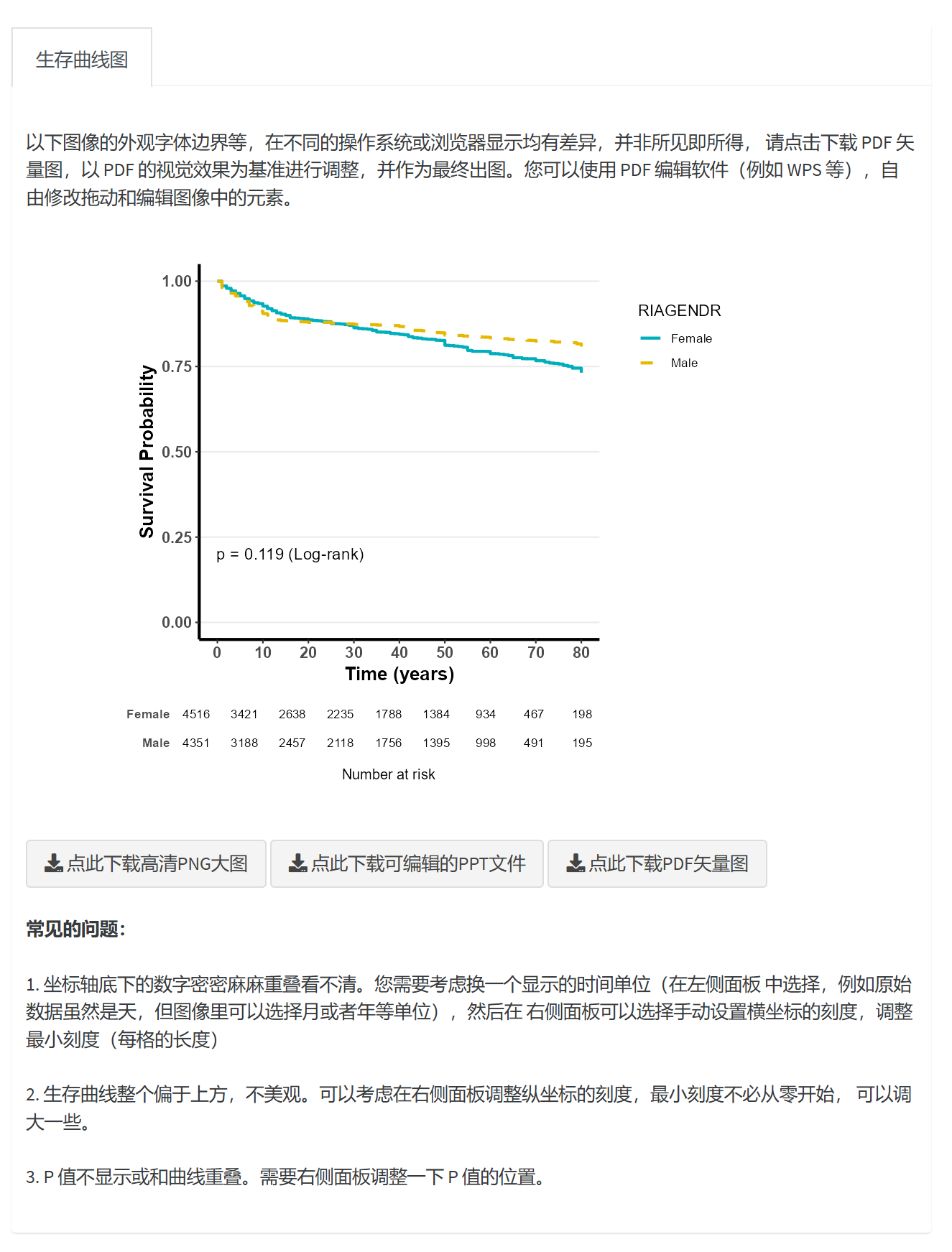
8.4.8 生存曲线图像调整
在生成生存曲线图后,您可以使用右侧的面板进一步调整图像的外观和设置。以下是各个调整选项的操作说明。
8.4.8.1 选择生存曲线类型
通过选择“生存曲线的类型”,您可以决定生存曲线的纵坐标样式:
传统下降 KM 曲线(常见于总体生存率或无进展生存率等):显示的是生存概率,曲线随时间下降。
累计事件发生率(常见于疾病发病率等):显示的是事件累计发生率,曲线随时间上升。
8.4.8.6 调整图像尺寸和边距
通过滑块调整图像的宽度和高度,以及左右空白边距:
图像宽度:设置曲线图的宽度,范围从 100 到 2000。
图像高度:根据不同分组数自动调整图像高度,您也可以手动设置。
左侧空白宽度:调整左侧空白,防止左侧文字被遮挡。
右侧空白宽度:调整右侧空白,防止右侧文字被遮挡。
8.4.8.7 设置横纵坐标刻度
选择如何设置横纵坐标的刻度:
系统自动设定:软件自动根据数据计算刻度。
手动设定:您可以手动设置横纵坐标的刻度,包括:
横坐标轴的最小值和最大值。
横坐标轴每个刻度的长度。
纵坐标轴的下限和上限(一般在 0 到 1 之间)。


8.5 Landmark 分段生存曲线(复杂抽样加权,R 软件 svykm 函数)
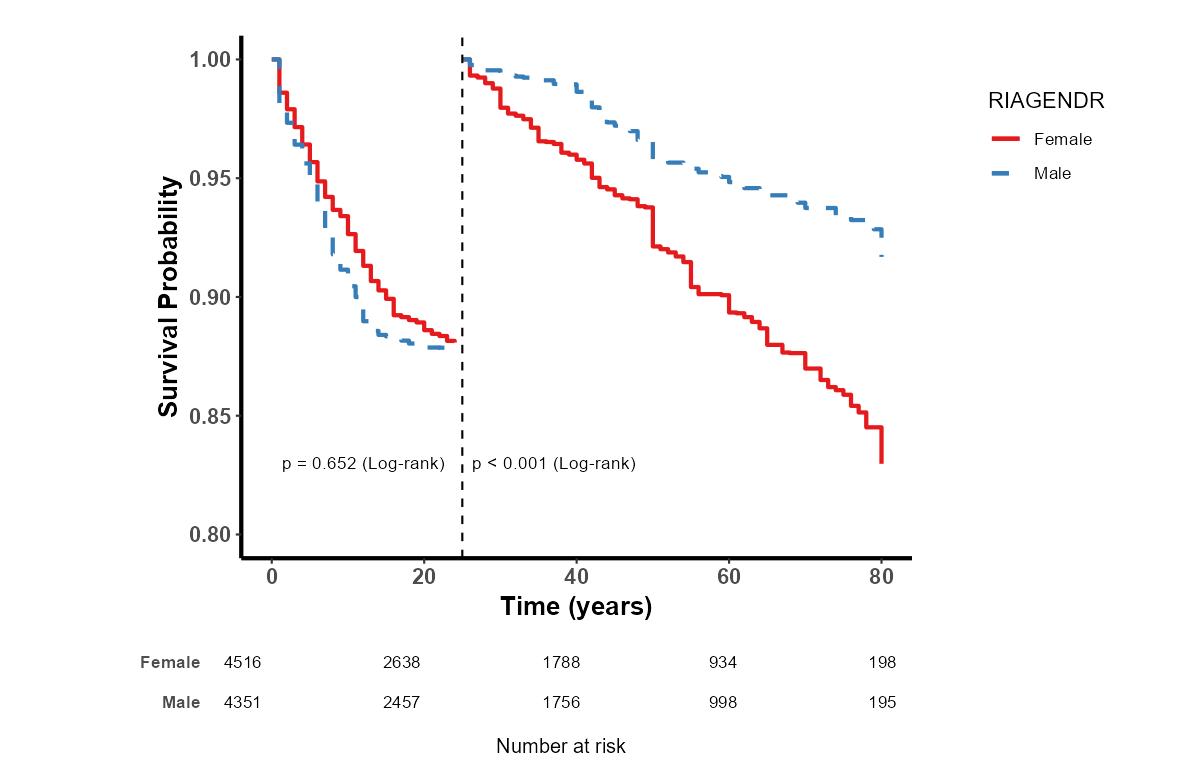
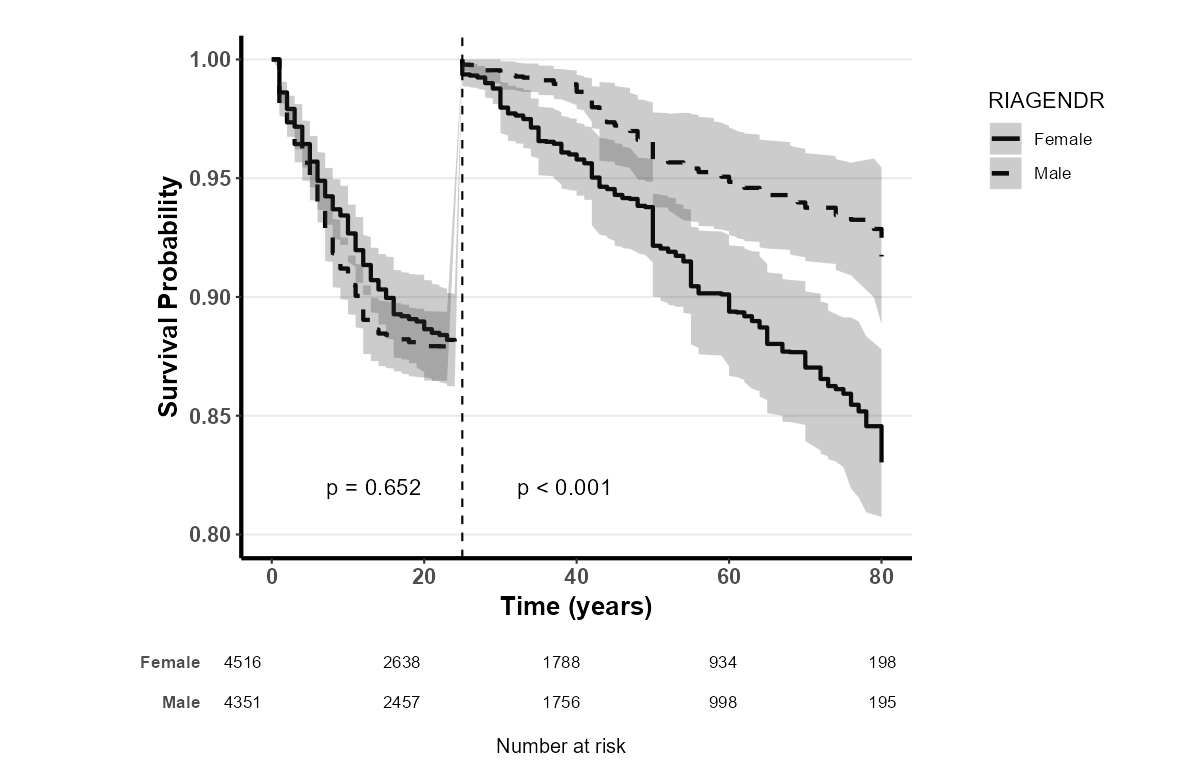
8.5.2 Landmark 生存曲线简介
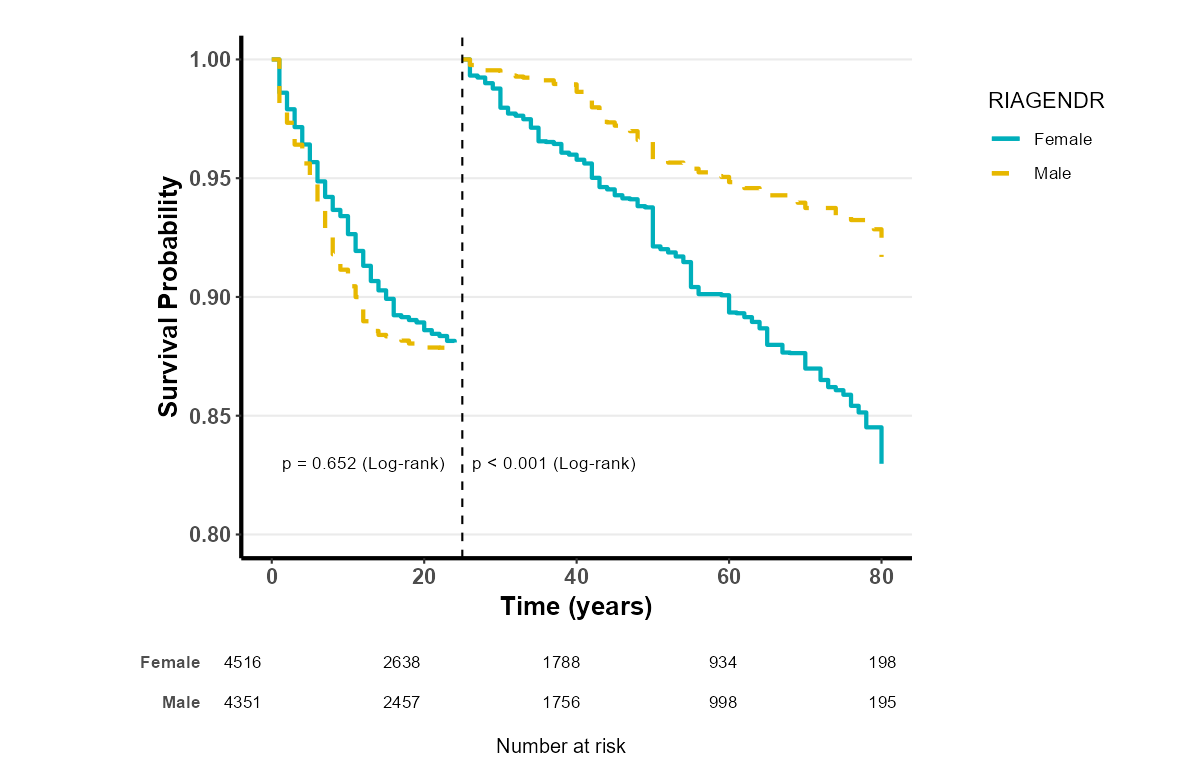
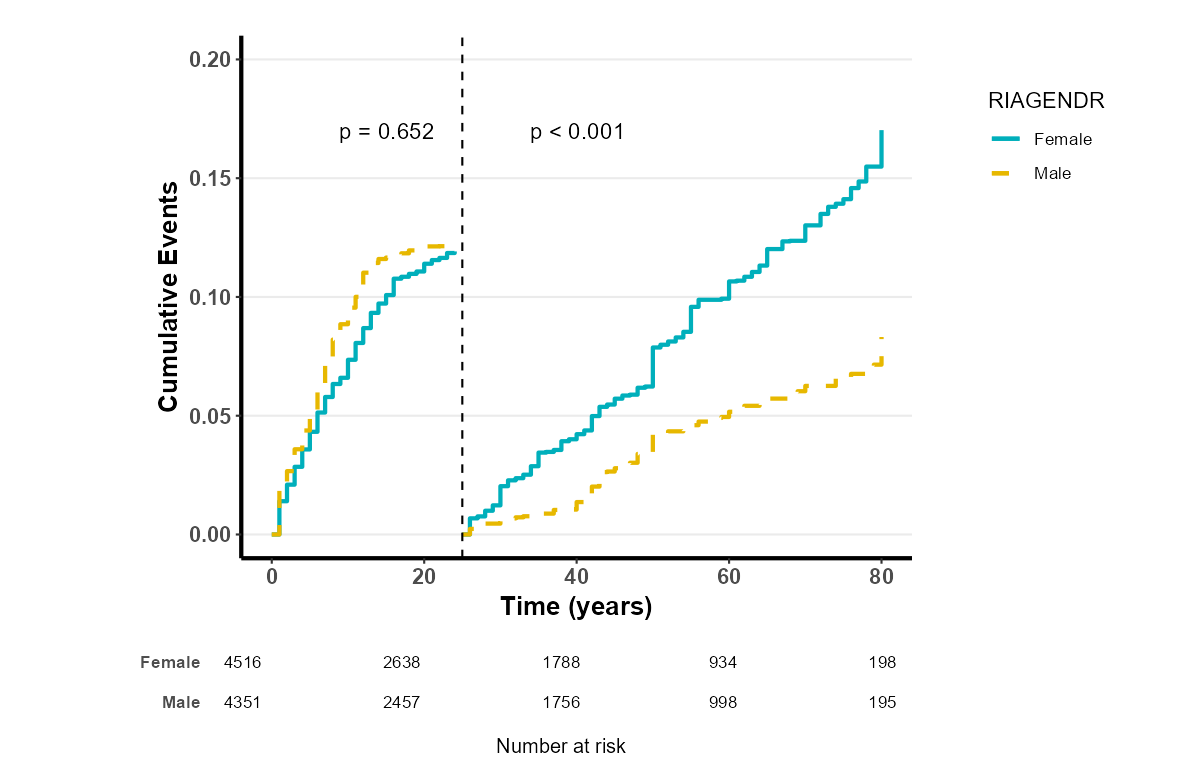
Landmark 生存曲线 是生存分析中的一种特殊方法,用于比较不同组别的生存曲线。它的关键特征是在指定的时间点(称为 Landmark 时间点)后,进行数据截断,只分析此时间点之后的生存数据。这样做的目的是避免在某个时间点之前由于治疗效果、患者特征等带来的潜在偏倚,从而更公平地比较不同组别的生存情况。
8.5.3 应用场景
Landmark 生存曲线常用于一些需要比较两组患者在治疗后期(或某个特定时间点之后)的生存情况。例如,当研究某种癌症疗法时,早期治疗阶段的生存率可能受患者的初始健康状况、治疗反应等因素影响,这可能会掩盖真正的长期疗效。此时,Landmark 生存曲线可以帮助研究者在一个预设的时间点之后,仅关注在此时间点仍然存活的患者,从而减少早期因素的干扰。
8.5.4 复杂抽样设计
许多调查使用复杂抽样设计而非简单随机抽样。这有多种原因。例如,如果构建列出总体中每个单位的抽样框架很困难或可能导致错误,可以使用多阶段抽样,先抽取较大且易于列出的单位群体,然后在每个群体内调查某些或全部单位,这样可以在现场构建准确的抽样框架。在多阶段抽样中,首先抽取主抽样单位(PSU)(例如,家庭),然后在每个PSU内抽取单位(例如,家庭中的个体)。当然,可以有超过两个阶段的抽样。早期阶段的单位形成簇。
另一个使用复杂抽样设计的原因是简单随机样本可能会导致某些感兴趣的子群体样本量过小。例如,如果关注种族/民族特定的平均血压,研究人员可能希望增加较小子群体的样本量。简单随机样本可能会导致多数种族/民族的样本量较大,而少数群体的样本量较小。与其增加总体样本量以确保较小群体的足够样本量,不如使用不等概率抽样对大群体进行欠抽样,对小群体进行过抽样,这样更具成本效益。
一种不等概率抽样的方法是在一些多阶段抽样设计中按比例概率抽样(PPS),其中较大的PSU有更大的被选中概率。另一种是分层随机抽样,即首先将总体非随机地分成若干层(例如,地理区域),然后在每层内进行简单随机抽样。将总体分层成不等大小的层,然后在每层内进行简单随机抽样,会导致不等概率抽样,因为较小层中的个体有更大的被选中概率。
8.5.5 NHANES
国家健康与营养检查调查(NHANES)是一个具有复杂设计的调查的例子。
NHANES样本不是简单随机样本,而是使用复杂的多阶段概率抽样设计来选择参与者,以代表美国民间非机构化人口。还对某些人口子群体进行过度抽样,以提高这些特定子群体健康状况指标估计的可靠性和精确性。研究人员需要在分析中适当指定抽样设计参数。
简而言之,NHANES采用了分层四阶段抽样设计。首先,根据人口普查区域和其他地理信息构建分层(非随机)。在每个分层内,随机选取美国县(PSU),较大的县有更大的被选中概率。在县内,按比例选取街区。在街区内,随机选取家庭,并对某些年龄、种族和收入群体进行过度抽样(较高的选中概率)。最后,在家庭内随机选取个体。有关NHANES复杂抽样设计的完整描述,请参见官方NHANES教程。
NHANES网站提供了使用survey软件包分析NHANES数据的示例R代码,以及在分析NHANES数据时的一些特殊考虑。
8.5.6 准备数据
NHANES数据的下载地址在 https://wwwn.cdc.gov/nchs/nhanes/
这里我们可以点击下方下载一段样例数据片段来做测试:
数据集中包含以下变量以考虑抽样设计:
分层变量(SDMVSTRA):
主要抽样单位(SDMVPSU)
访谈抽样权重(WTINT2YR)
检查抽样权重(WTMEC2YR)
空腹子样本抽样权重(WTSAF2YR):
本例中做生存曲线的相关变量:
asthma:0和1,0 表示该随访对象随访结束时没有罹患哮喘;1 表示该调查对象随访结束时罹患哮喘
asthma_year:该随访对象从出生后经历多少年发展为哮喘(没有哮喘则填随访结束时的年龄)
在使用NHANES数据时,请务必查阅相关数据文档和代码手册,以确保使用适当的抽样权重。
8.5.7 进入模块
接下来我们进入模块,点击软件顶部菜单的“复杂抽样加权(NHANES等)”,然后点击“Landmark 分段生存曲线(复杂抽样加权,R 软件 svykm 函数)” 进入模块。
进入软件界面,首先进行如下设置:
8.5.8 设置复杂抽样参数
请按照以下步骤设置您的复杂抽样参数:
选择分层变量
在设置界面中,找到“请选择代表分层(strata)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的分层信息。例如,在NHANES数据库中,这个变量通常是SDMVSTRA。
背景知识:分层抽样(Stratified Sampling)是一种将总体分为若干个互不重叠的层,然后在每个层内进行随机抽样的方法。这种方法可以提高估计的精确性,特别是在总体内部具有较大异质性的情况下。例如,在NHANES中,不同地理区域(如不同的州或县)可能存在健康状况的差异,通过分层抽样可以确保每个区域的代表性。
如果您的数据不需要分层,请选择“无”。
选择主抽样单位(PSU)变量
选择完分层变量后,系统会自动弹出“请选择代表主抽样单位(id)的变量”选项。
从下拉菜单中选择一个变量,该变量代表数据中的主抽样单位(PSU)。例如,在NHANES数据库中,这个变量通常是SDMVPSU。
背景知识:主抽样单位(Primary Sampling Unit, PSU)是多阶段抽样中的第一层单位。在NHANES中,PSU通常是县或县级等价单位。在每个PSU内,再进一步抽取次级单位(如家庭或个人)。这种方法可以减少调查成本,提高抽样效率。
确保所选变量不同于分层变量。
选择权重变量
选择完PSU变量后,系统会自动弹出“请选择代表权重(weights)的变量”选项。
从下拉菜单中选择一个权重变量。权重变量有助于确保样本的代表性。在NHANES数据库中,常见的权重变量有WTINT2YR、WTMEC2YR等。
背景知识:权重(Weights)是用于调整样本统计量以反映总体参数的因子。在复杂抽样设计中,由于不同单位被抽中的概率不同,直接使用样本统计量可能会产生偏差。权重的作用是校正这种偏差,使估计值更接近于总体参数。例如,在NHANES中,不同个体的被抽中概率不同,通过使用合适的权重,可以确保结果具有全国代表性。
选择权重的指南(简化版,仅做示例):
访谈权重(WTINT2YR):如果您的分析仅使用在访谈中收集的数据,则选择此权重。每个参与者都接受了访谈,因此每个人的访谈抽样权重都大于0。
检查权重(WTMEC2YR):如果您的分析包含体检数据,则应选择此权重。大多数参与者在移动检查中心(MEC)接受了体检,收集了客观测量数据。
空腹子样本权重(WTSAF2YR):如果您的分析包含空腹血液测量数据,则应选择此权重。只有部分参与者在空腹状态下提供了血液样本,因此需要使用相应的权重进行调整。
注意:选择权重变量非常复杂,以上只是一个简要规则,实际规则比这个复杂,请务必登录和参考NHANES官网的说明书,对于选择哪个权重有详细的规则说明,以确保选择适当的权重。
处理权重缺失值
在权重变量选择下方,您需要选择如何处理权重变量中的缺失值。
选项包括:
将权重缺失值用0填充
将权重缺失的数据整行删除
将权重缺失以及权重≤0的数据整行删除(Cox回归请勾选此项)
背景知识:在调查数据中,权重缺失值可能会影响分析结果的准确性。不同处理方法可以应对不同的分析需求和数据质量问题。例如,将缺失值填充为0可以保留数据行,但可能导致偏差;而删除权重缺失的数据则可以提高结果的准确性,但会减少样本量。
设置嵌套集群标识(Nest)
选择是否应用嵌套集群标识。如果您的数据集的ID值在分层中是嵌套的(如NHANES数据库),推荐选择“是”。
选择“是”可以确保在每个分层内,集群ID是唯一的,避免分析时出现问题。
背景知识:嵌套集群(Nested Clusters)是指在复杂抽样设计中,主抽样单位ID在不同分层内可能重复。通过设置嵌套集群标识,可以确保每个分层内的集群ID是唯一的,从而避免在数据分析时出现混淆和错误。例如,在NHANES中,不同地理区域可能有相同的PSU ID,通过嵌套设置可以确保分析的准确性。
8.5.9 绘制 landmark 生存曲线
用户可以选择生成:
总体生存曲线:不区分组别的生存曲线。
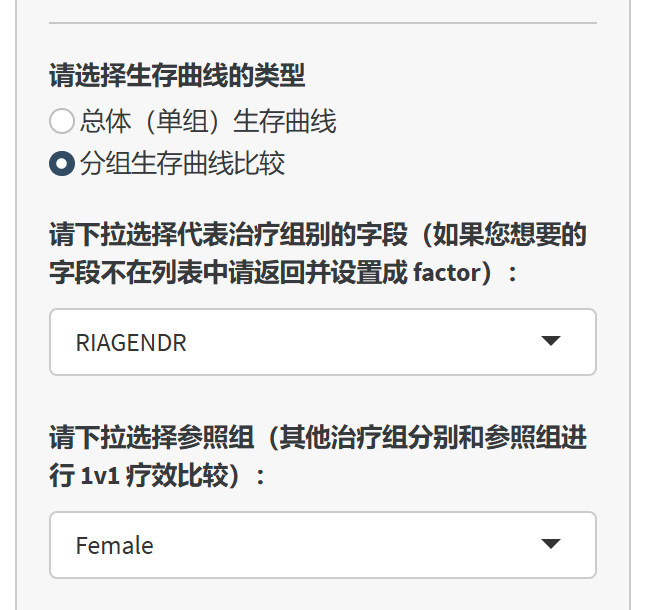
分组生存曲线:按不同组别比较生存曲线。
当选择“分组生存曲线”时,需进一步选择代表分组的变量(如治疗组)。
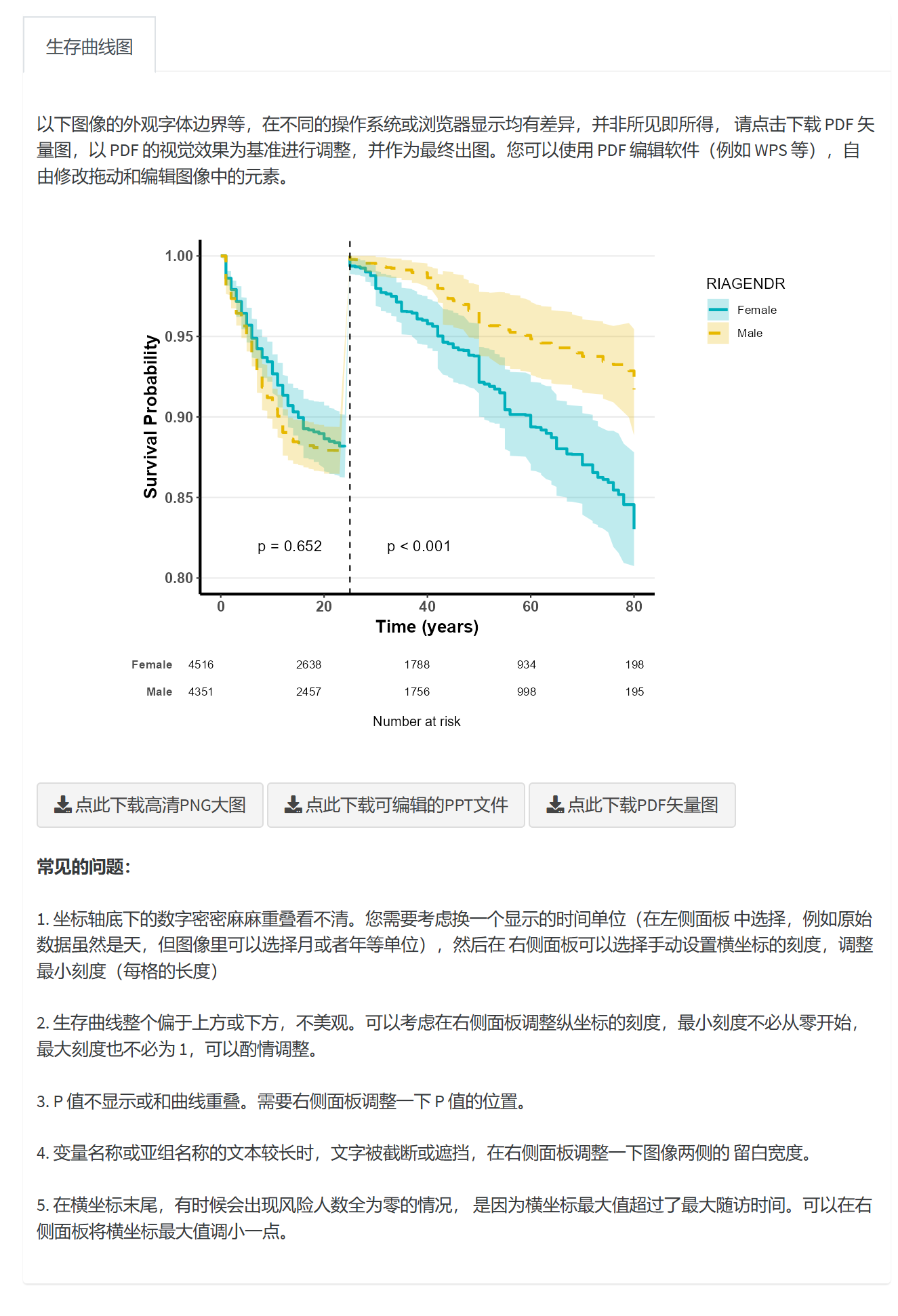
8.5.10 图像外观调整
在生成生存曲线图后,用户可以通过右侧的面板对图像进行详细的调整。面板中的选项被分为多个部分,每个部分都包含特定的图像调整功能。选项放置在可折叠的菜单选项框内,您可以通过点击右侧的 + 号来展开选项,点击 - 号收起选项。
以下是最新的调整选项及其说明。
8.5.10.1 生存曲线类型和 Landmark 截断设置
位置:生存曲线类型设置
选择生存曲线的类型:
传统下降 KM 曲线:纵坐标显示生存率,曲线下降(常用于总体生存率或无进展生存率等)。
上升曲线:纵坐标为累计事件发生率,曲线随时间上升(常用于事件发生率等)。
Landmark 截断值:在生成 Landmark 曲线时,您可以输入一个横坐标截断值,默认值为随访时间的 50%。此值用于 Landmark 分析,在特定时间点后对生存曲线进行截断,以便更清晰地比较不同组别的生存情况。

8.5.10.2 图像尺寸和边距调整
位置:图像长宽大小和两侧空白尺寸调整 菜单选项框
设置图像宽度:通过滑块调整图像的宽度,范围从 100 到 2000。
设置图像高度:根据分组数量默认设定高度,您可以根据需要手动调整。
设置左侧空白宽度:调整左侧的空白区域,避免文字或坐标轴标签被遮挡。
设置右侧空白宽度:调整右侧空白,防止图例或其他元素被遮挡。

8.5.10.3 曲线外观、线条和配色调整
位置:曲线外观、线条和配色调整 菜单选项框
生存曲线外观风格:
经典色不带背景网格:经典配色,不显示网格线。
黄绿 JAMA 风格:采用类似 JAMA 期刊的黄绿色配色,并带有网格线。
曲线配色风格:提供三种彩色搭配方案(Set1、Set2、Set3),以及黑白配色可选。
线条风格:
仅用实线颜色区分:所有线条为实线,通过颜色区分。
用不同线型区分:通过实线、虚线等样式区分不同的线条。
线条粗细:通过滑块调整曲线的线条粗细,范围为 0.1 到 5。
8.5.10.4 横纵坐标刻度和范围调整
位置:横纵坐标上下限、刻度值调整 菜单选项框
系统自动设定:让系统自动根据数据设置刻度和坐标范围。
手动设定:您可以手动设定横纵坐标的刻度和范围:
横坐标刻度下限和上限:手动输入时间轴的最小值和最大值,最大值不能超过随访时间。
横坐标刻度间隔:设定时间轴上每个刻度的长度值,调节刻度的密集程度。
纵坐标上下限:调整纵坐标轴的上下限,通常设为 0 到 1 之间。
8.5.10.5 坐标轴标题和字体调整
位置:修改坐标轴的标题文字和大小 菜单选项框
坐标轴刻度文字大小:调整横纵坐标轴刻度的文字大小,范围从 1 到 50。
坐标轴标题文字大小:调整坐标轴标题的字体大小。
横坐标标题:默认显示为
Time (单位),您可以手动修改。纵坐标标题:根据曲线类型,默认显示为
Survival Probability或Cumulative Events,可根据需要修改。纵坐标刻度单位:
用小数表示:如 0.5, 0.6。
用百分比表示:如 50%, 60%。
8.5.10.6 Log-rank P 值显示和调整
位置:log-rank P 值位置和字体调整 菜单选项框
是否显示 Log-rank P 值:选择是否在图中显示 Log-rank 检验的 P 值。
P 值位置和字体调整:
横向位置:通过滑块调整 P 值在图中的横向位置。
纵向位置:调整 P 值在图中的纵向位置。
P 值字体大小:设置 P 值的字体大小。
P 值后加上 Log-rank 标识:选择是否在 P 值后面添加 “(Log-rank)” 标识。