Chapter 3 描述统计
3.1 一键生成患者入排流程图
3.1.2 常见痛点
如果是注册临床试验,统计程序员会用复杂的编程语言,直接从原始入排数据集中生成CONSORT图。但我们广大的临床科研人员,可没这个本事,大多数用word,稍微有点能耐的,用Visio等流程图软件绘制,但是还得布局排版!还得鼠标拖来拖去!还要手工调框的大小!还要调箭头方向,粗细!非常麻烦,耗时耗力。
不妨换一种思路。
3.1.7 进入程序并创建方框
好的,接下来我们进入模块,点击软件顶部菜单的“描述统计”,然后点击“一键生成患者入排流程图” 进入模块:
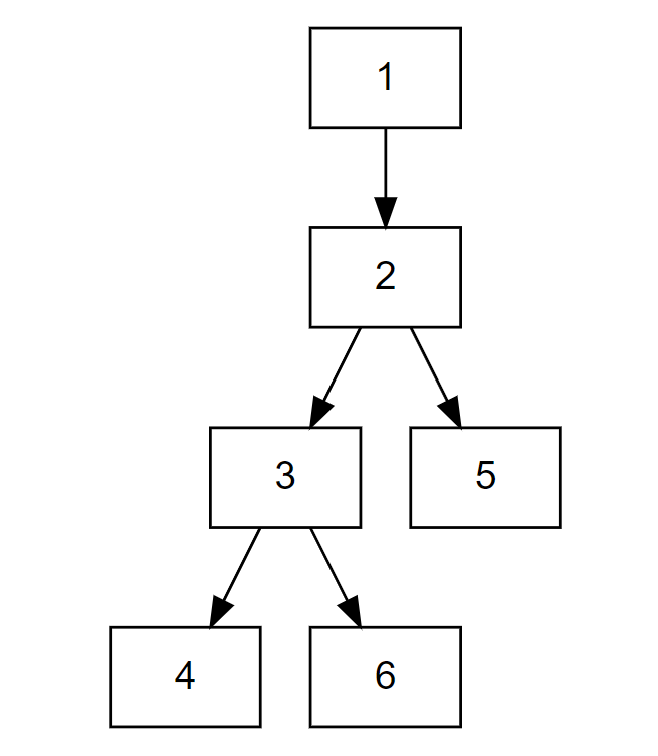
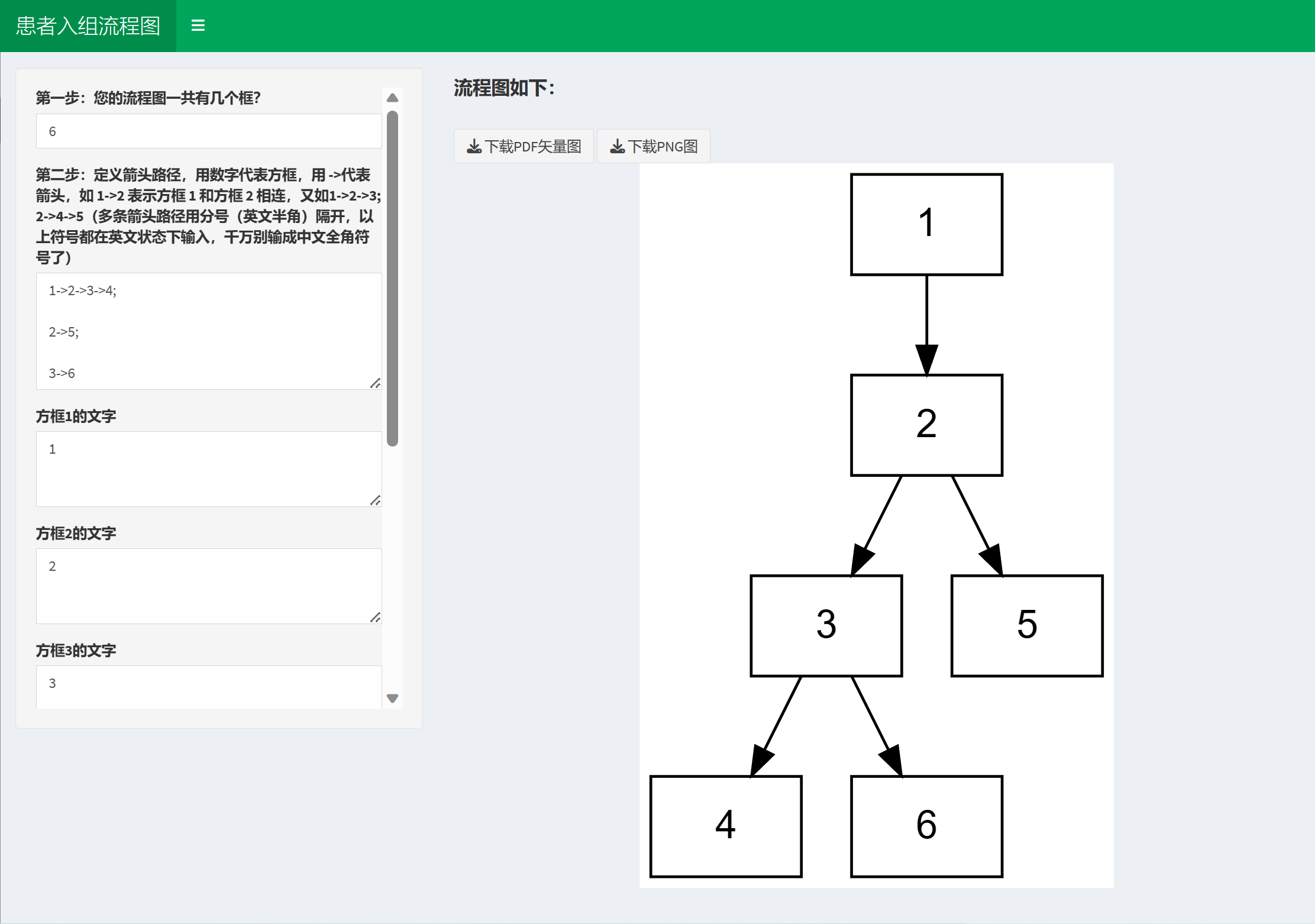
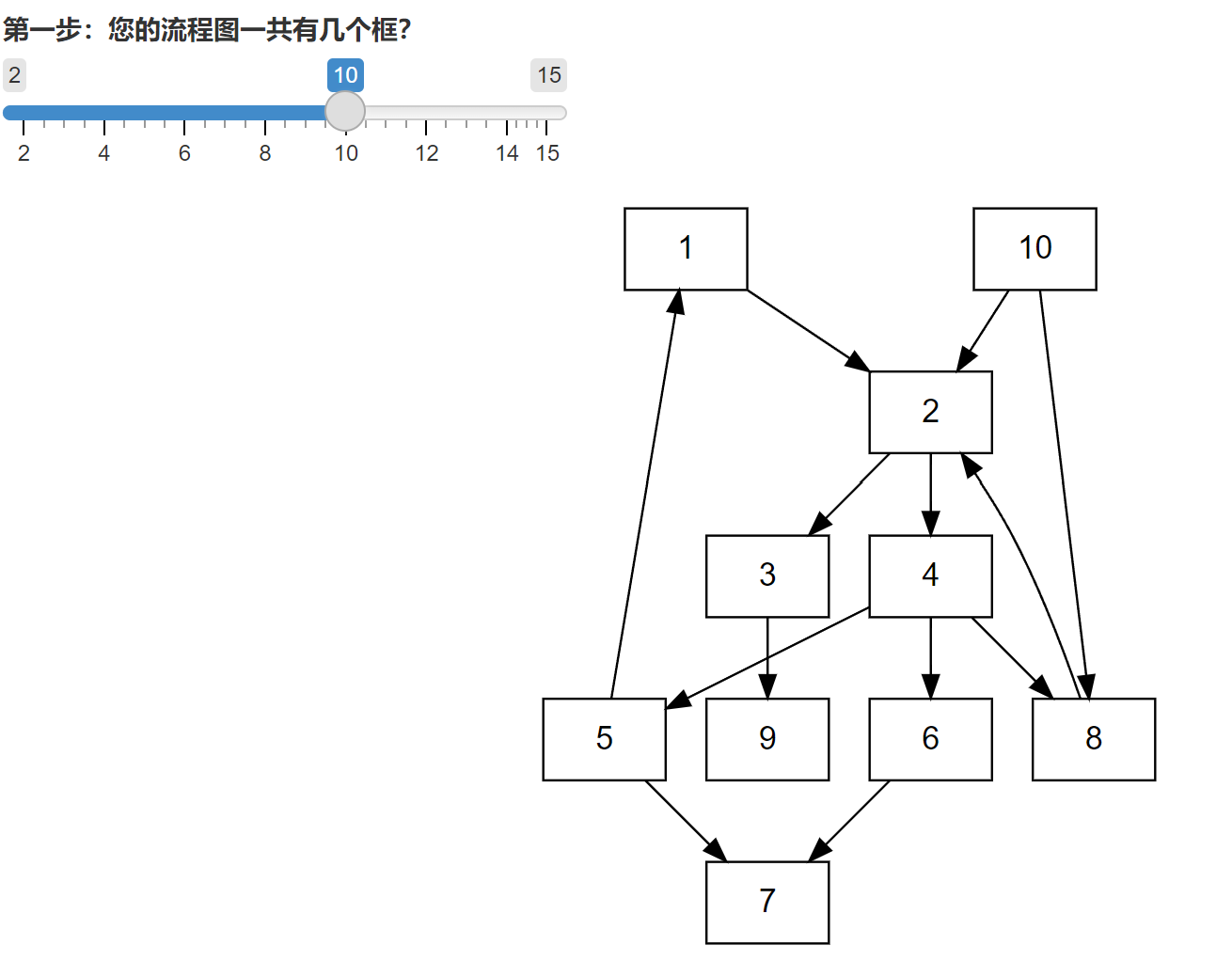
进去之后,程序会问我们,要画的图一共包含几个方框,这里选6即可。于是生成了6个方框。
3.1.8 指定方框连接:简洁的“箭头语言”
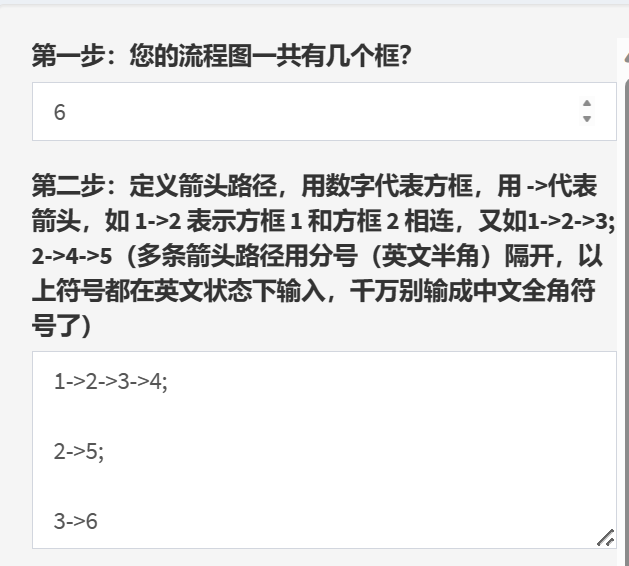
第二步,告诉程序方框之间箭头怎么连接。这里我们用一种简单的箭头语言。
我们用数字123代表方框,用符号 -> 来代表箭头,注意这里都是英文半角符号哈,别打错了。比如 1->2代表从方框1打箭头到方框2。2->6代表从方框2打箭头到方框6。
而我们要生成的图,我们看一下就知道了,从1到2到3到4,箭头连过去,从2到5有一个箭头,从3到6有一个箭头。所以我们用下面的语言表示:
1->2->3->4;
2->5;
3->6
中间用分号隔开哈。

3.2 一键生成基线人口学和临床特征表(全能版)
这是一款智能进行统计分析的工具,用来生成论文里患者基线人口学特征表(Table one)。
主要特点:
根据上传的科研数据,简单点击设置后,一键自动生成基线特征统计表
支持不分组(一维表)/分组(二维表)/分层+分组(三维表)描述统计
支持自动和手动指定组间比较的统计方法
支持人工智能自动进行正态性检验和自动选择合适的统计学方法计算 P 值
支持人工智能生成描述性文字
生成 SCI 投稿格式的 word 统计报告(黑白表格)
支持生成 PPT 文件(彩色表格)
一键生成 R 源代码,作为存档提供给投稿期刊
一维表:

二维表:
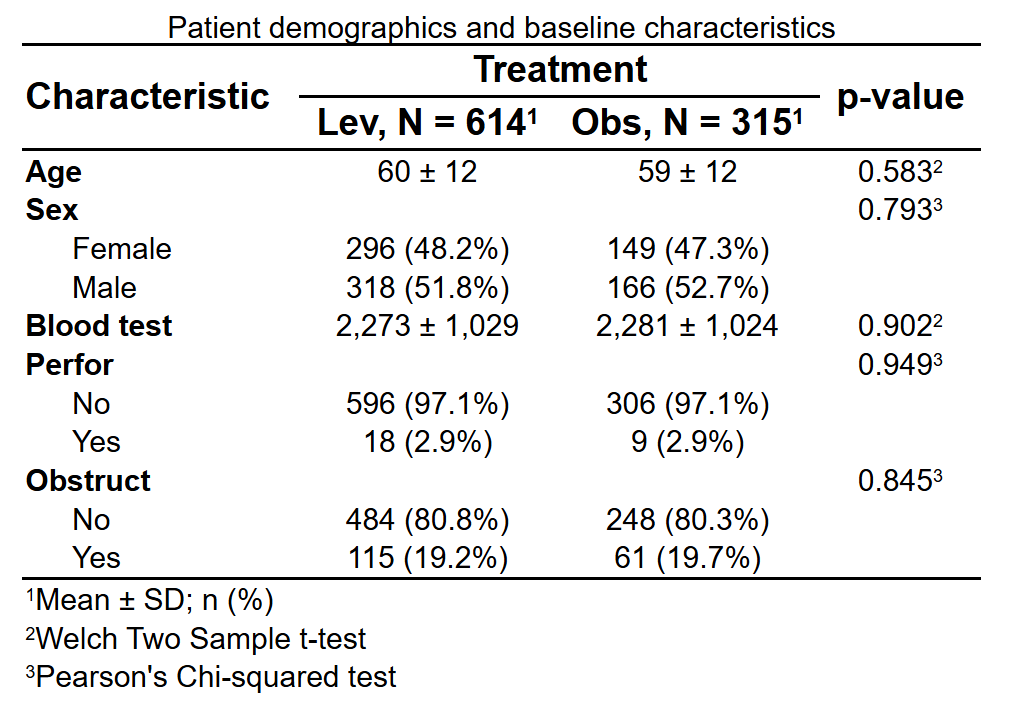
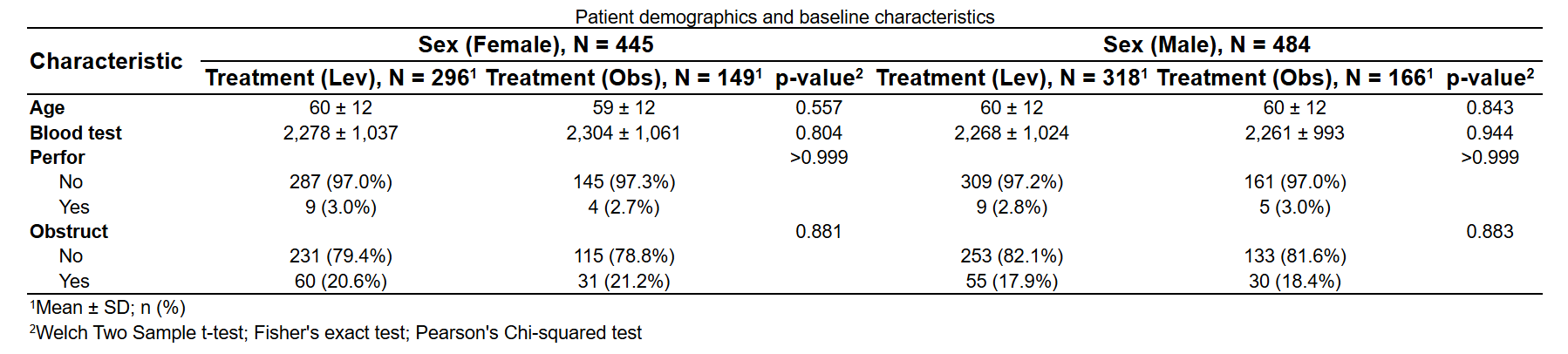
三维表:
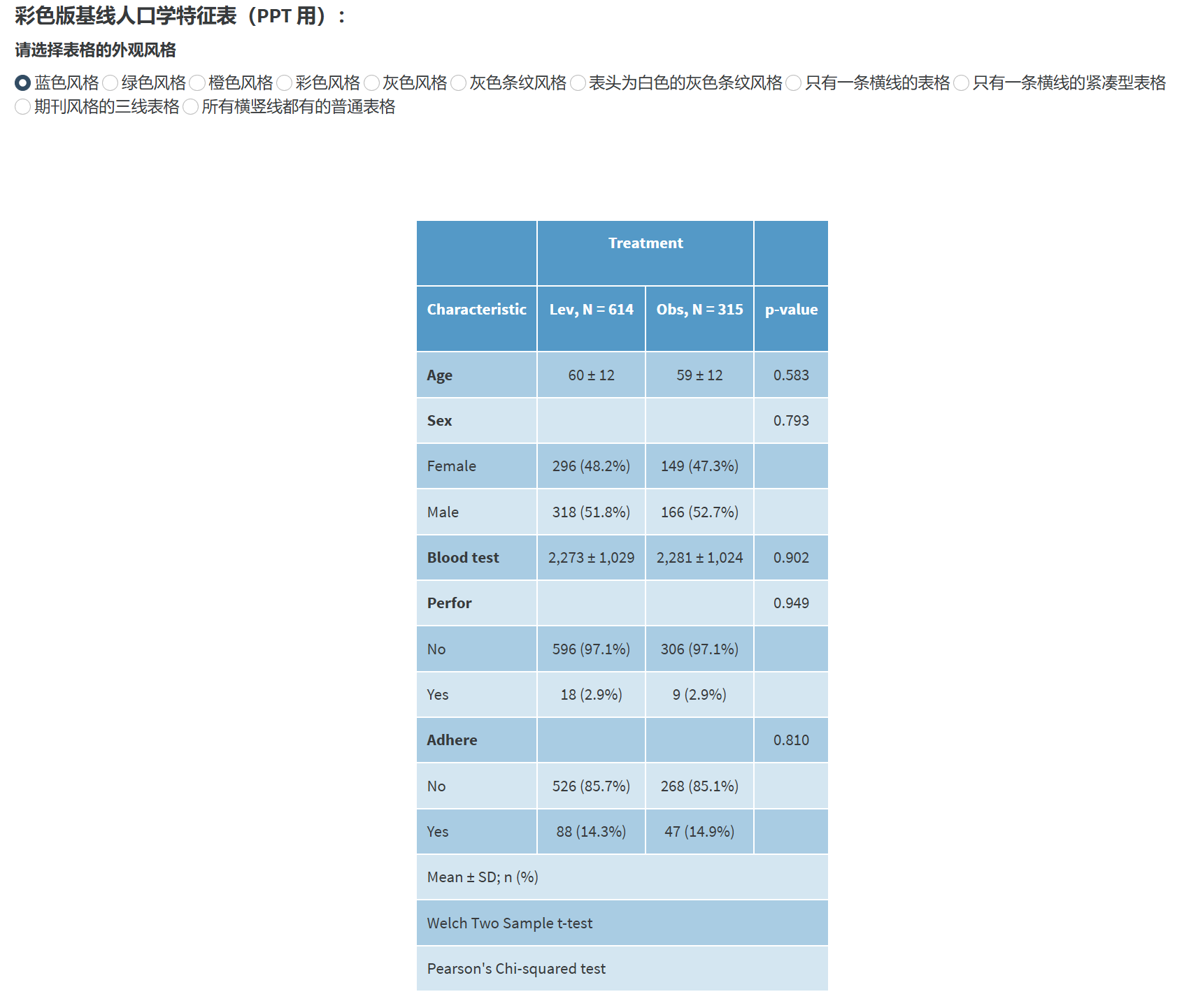
彩色 PPT:
软件自动给表格添加文字描述:

3.2.1 准备数据
首先务必按照下面的格式准备数据(网站上可下载,下载后在此基础上修改):
打开如下图:
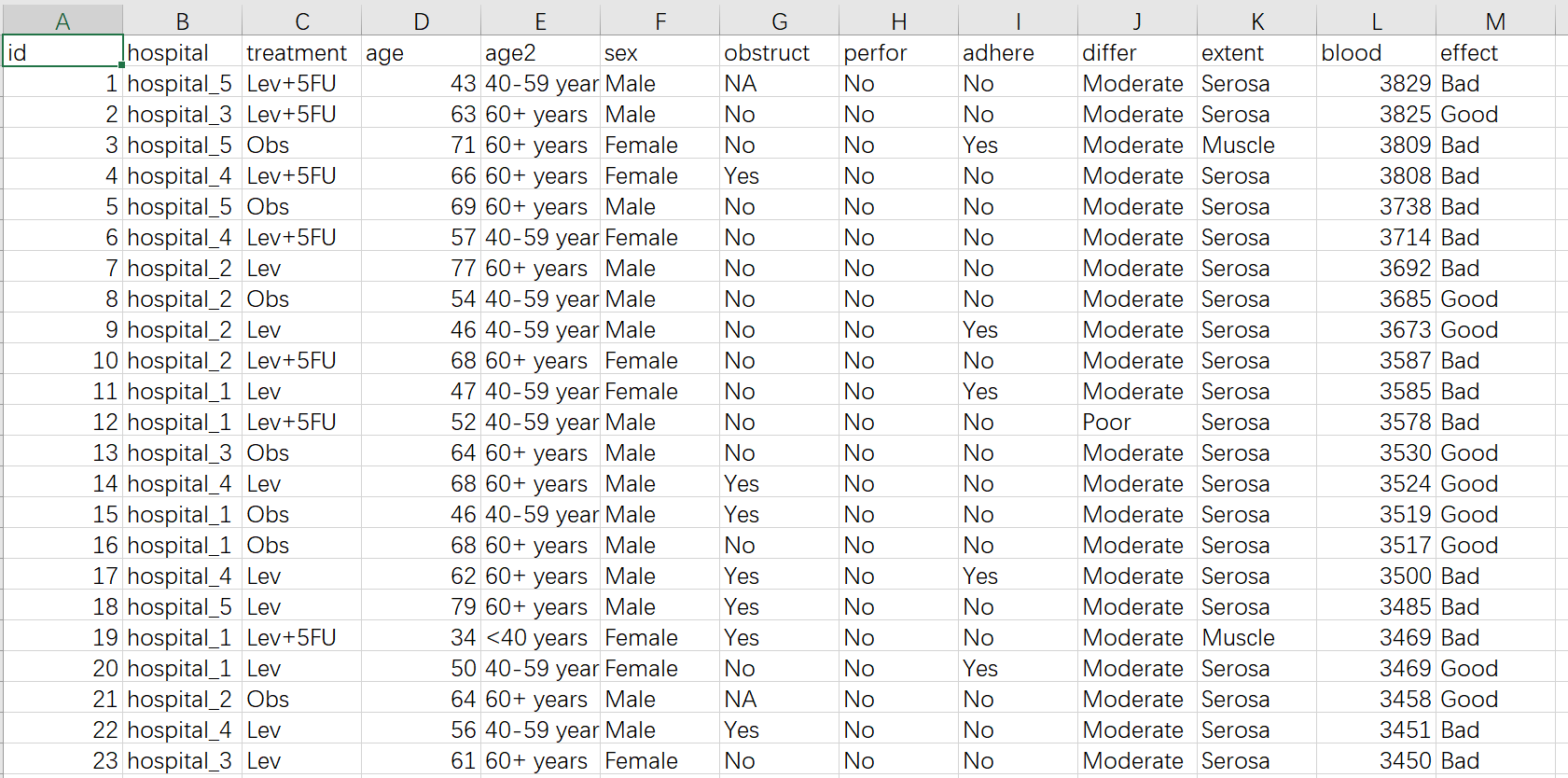
本样例数据的规则:
一个患者一行(这是准备数据最重要的前提)。
本例中 treatment 为分组变量,下面有三个治疗组。
所有变量分为连续性变量和分类变量两种,连续性变量(值是连续数据,它可以在变量值所属区间内任意进行取值,如年龄(岁)、血糖值、人的身高、智商等)以及分类变量(是说明事物类别的一个名称,其取值是分类数据。如”性别”就是一个分类变量,其变量值为”男”或”女”;“行业”也是一个分类变量,其变量值可以为”零售业”、“旅游业”、“汽车制造 业”等),在本例中 age 、blood 等是连续性变量(numeric), 其他的是分类变量(factor)。有些数据虽然是用1, 2, 3, 4 数字表示的,但代表的是职业”工人”,“农民”,“知识分子”,“干部”,其实也是个分类变量。
以上概念很重要,后面有一个页面专门设置连续变量和分类变量。
3.2.3 设置统计表的基本选项
在开始生成统计表之前,首先需要设置一些基本选项:
选择统计表语言:
您可以选择统计表的语言,选项包括:
英文:统计表将以英文显示,推荐首选。
中文:统计表将以中文显示。
统计表外观:
选择统计表的外观风格,选项包括:
舒展型:表格宽,字体较大,视觉上更舒适。
紧凑型:表格较窄,字体较小,能够在屏幕上显示更多内容。
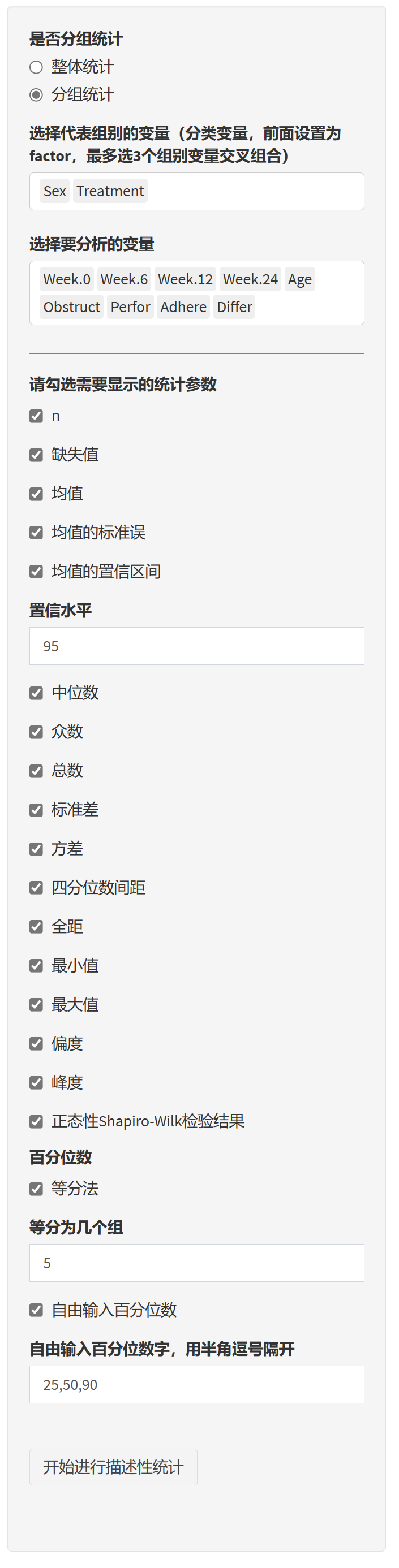
是否分组统计:
确定统计表的类型,选项包括:
否,整体人群单组描述(一维表):对整体人群进行描述,不进行分组。
分组分析描述(二维表):根据某个变量将人群分组,进行组间比较。
分层+分组分析描述(三维表):在分层的基础上,再进行分组分析。

3.2.4 选择分层和分组变量
根据您的统计表类型,可能需要选择分层和分组变量:
分层变量(仅当选择三维表时):
在下拉菜单中选择一个用于分层的变量。例如,性别、年龄组等。
分层分析可以帮助您在不同的亚组中进行比较,揭示潜在的差异。
分组变量(当选择二维表或三维表时):
在下拉菜单中选择一个用于分组的变量。例如,治疗组别、疾病状态等。
分组分析用于比较不同组别之间的特征差异。
注意:如果在下拉菜单中未找到您需要的变量,可能是因为该变量未被识别为分类变量。请返回数据准备部分,将该变量设置为因子(factor)类型。
3.2.5 选择需要统计的变量
选择统计变量:
在多选列表中选择您希望在统计表中展示的变量。
您可以选择多个变量,支持鼠标拖拽排序,调整变量的展示顺序。
提示:建议选择与研究相关的关键变量,包括人口学特征、临床指标等。
3.2.6 数值型变量的处理
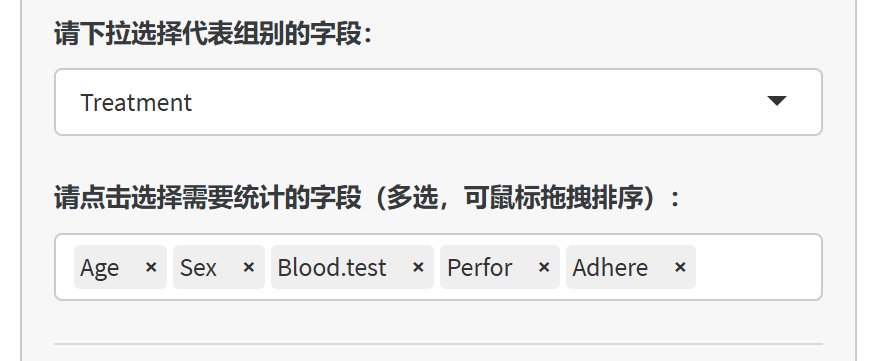
是否将数值型变量转换为分类变量:
不转换,当做普通连续性变量:数值型变量将以连续变量的形式进行统计(如计算均值、标准差)。
将取值范围较少的数值型变量自动转换为分类变量:对于取值种类较少的数值型变量(如只有0/1或1/2/3),可以自动转换为分类变量。
如果选择自动转换,您可以设置:
- 水平数小于多少视为分类变量:设置一个阈值,变量的取值种类数小于该值时,自动转换为分类变量。默认值为6。
3.2.7 连续性变量的分组
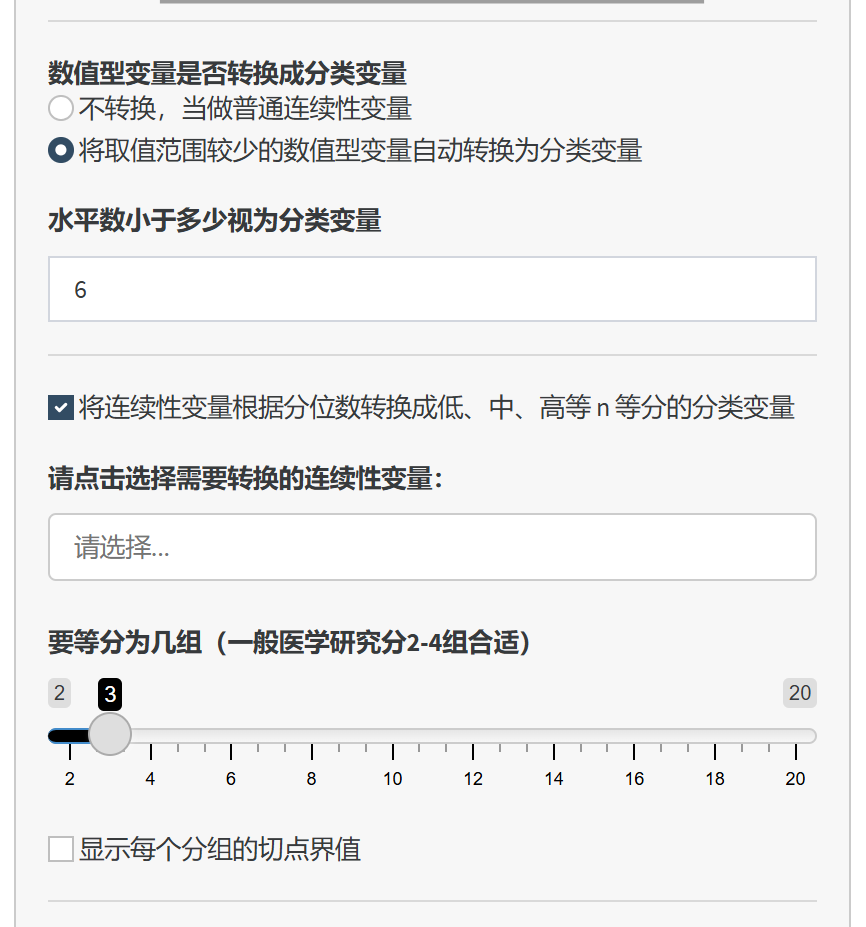
将连续性变量根据分位数转换成分类变量:
如果希望将连续性变量分组(如将年龄分为低、中、高三组),可以:
勾选 将连续性变量根据分位数转换成低、中、高等 n 等分的分类变量。
选择需要转换的变量。
设置分组数目(一般医学研究中,分2-4组较为合适)。
勾选 显示每个分组的切点界值,以便了解各组的划分标准。
3.2.8 选择统计方法
数值型变量的统计方法:
您需要选择连续性变量的描述方式和组间比较方法:
均值(标准差)统计,用参数法检验:适用于服从正态分布的变量,使用 t 检验或方差分析。
中位数(IQR)统计,用非参数法检验(推荐):适用于非正态分布的变量,使用 Mann-Whitney U 检验或 Kruskal-Wallis 检验。
同时显示均值、标准差、中位数、IQR、最小值、最大值:提供更全面的描述。
自动选择统计方法:计算机根据 Shapiro-Wilk 正态性检验结果,自动选择参数法或非参数法(样本量小于5000时适用)。
手动指定统计方法(推荐):您可以人为指定每个变量使用哪种统计方法,需先观察 Q-Q 图判定正态性。
提示:对于样本量较大的数据,Shapiro-Wilk 检验可能不可靠,建议通过 Q-Q 图或其他方法判断正态性。
查看 Q-Q 图:
- 点击 显示 Q-Q 图以观察变量的正态性 按钮,查看各连续性变量的 Q-Q 图,以判断其分布形态。
手动指定统计方法(当选择手动指定时):
- 对于每个连续性变量,选择使用 均值(标准差)统计,用参数法检验 或 中位数(IQR)统计,用非参数法检验。

3.2.9 统计表的详细设置
连续性变量统计方式的标注:
在表格下方统一底注:在表格底部统一说明连续性变量的统计方法。
对每个字段分别标注:在每个变量的名称后直接标注统计方法。
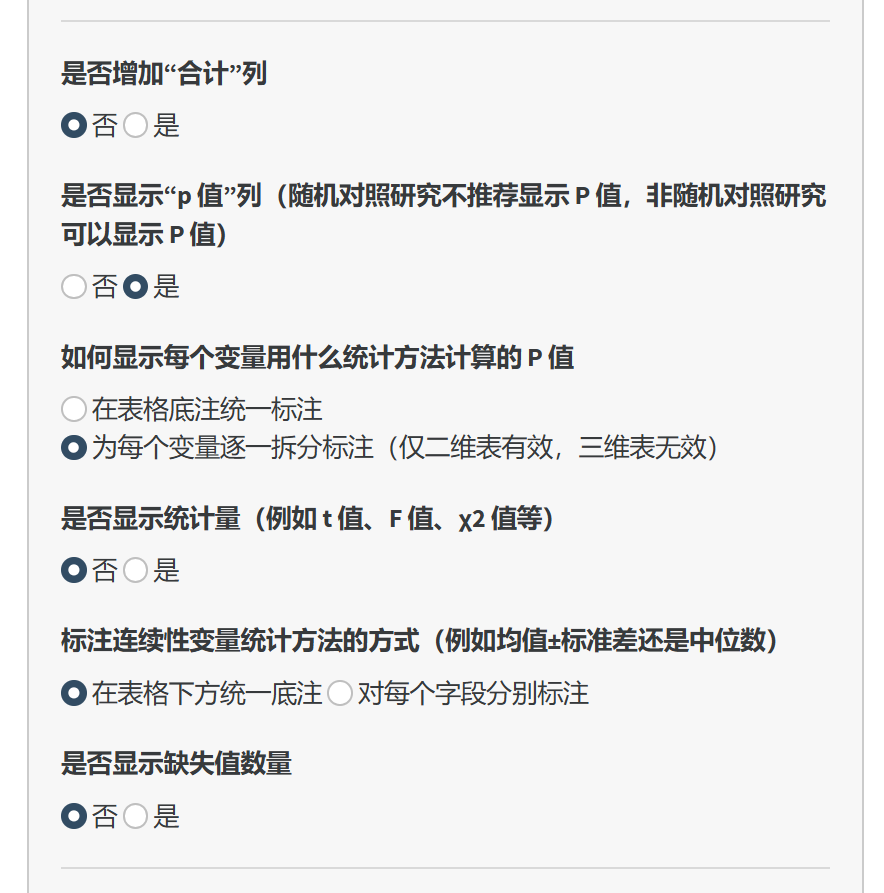
是否显示 P 值列(当进行组间比较时):
是:显示各变量的组间比较 P 值。
否:不显示 P 值(在随机对照研究中不推荐显示 P 值)。
P 值计算方法的标注:
在表格底注统一标注:在表格底部统一说明各变量的 P 值计算方法。
为每个变量逐一拆分标注:在每个变量的名称后标注所用的检验方法(仅适用于二维表)。
是否显示统计量:
是:在表格中显示统计检验的统计量(如 t 值、F 值、χ² 值)。
否:不显示统计量。
如果选择显示统计量,可以设置:
- 统计量的小数位数:调整统计量的精度,默认保留2位小数。
是否显示 95% 置信区间(当不进行组间比较时):
是:显示连续性变量的95%置信区间。
否:不显示。
是否增加“合计”列(当进行分组分析时):
是:在表格中增加一列显示所有组别的合计数据。
否:不增加合计列。
是否显示缺失值数量:
是:在表格中显示每个变量的缺失值数量。
否:不显示缺失值信息。
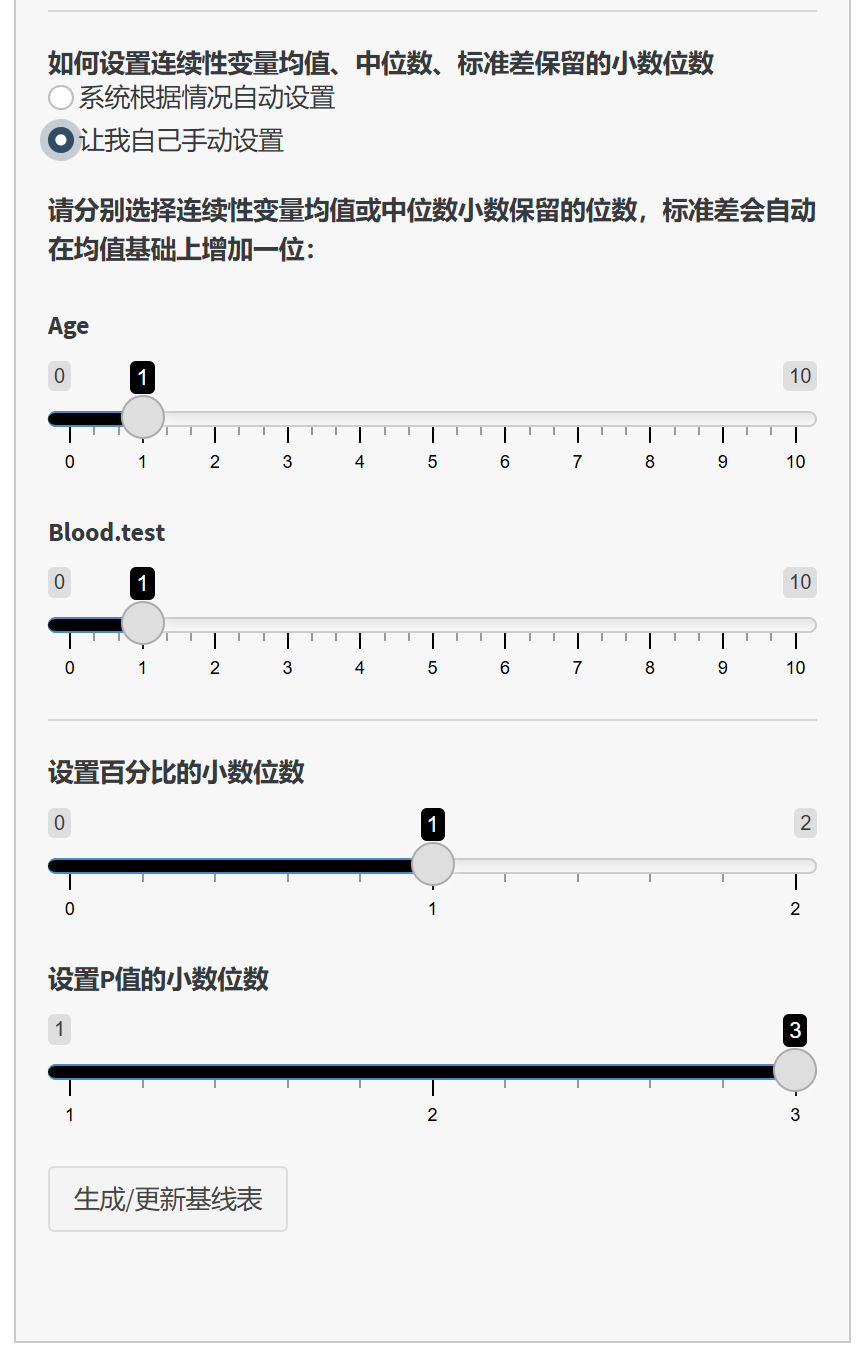
3.2.10 设置小数位数
连续性变量的小数位数:
系统自动设置:软件根据数据自动决定保留的小数位数。
手动设置:您可以为每个连续性变量单独设置均值或中位数保留的小数位数,标准差会在此基础上自动增加一位。
百分比的小数位数:
- 设置分类变量的百分比保留的小数位数,默认保留1位小数。
P 值的小数位数:
- 设置 P 值保留的小数位数,通常为3位。
3.2.12 重要统计学概念解释
参数法与非参数法:
参数法:假设数据服从某种分布(如正态分布),使用均值和标准差进行描述,适用于 t 检验、方差分析等。
非参数法:不依赖于数据的分布形式,使用中位数和四分位数间距(IQR)进行描述,适用于 Mann-Whitney U 检验、Kruskal-Wallis 检验等。
正态性检验:
Shapiro-Wilk 检验:用于检验数据是否服从正态分布,适用于样本量较小的数据集。
Q-Q 图:通过绘制理论分位数与实际数据分位数的散点图,直观判断数据的分布形态。
P 值:
- 表示统计检验中观察到的结果在零假设成立的条件下出现的概率。P 值越小,拒绝零假设的证据越强。
置信区间(Confidence Interval, CI):
- 用于估计总体参数的范围,通常使用95%置信区间,表示有95%的概率包含真实的总体参数。
缺失值处理:
- 在统计分析中,了解变量的缺失情况有助于评估数据的完整性和分析结果的可靠性。

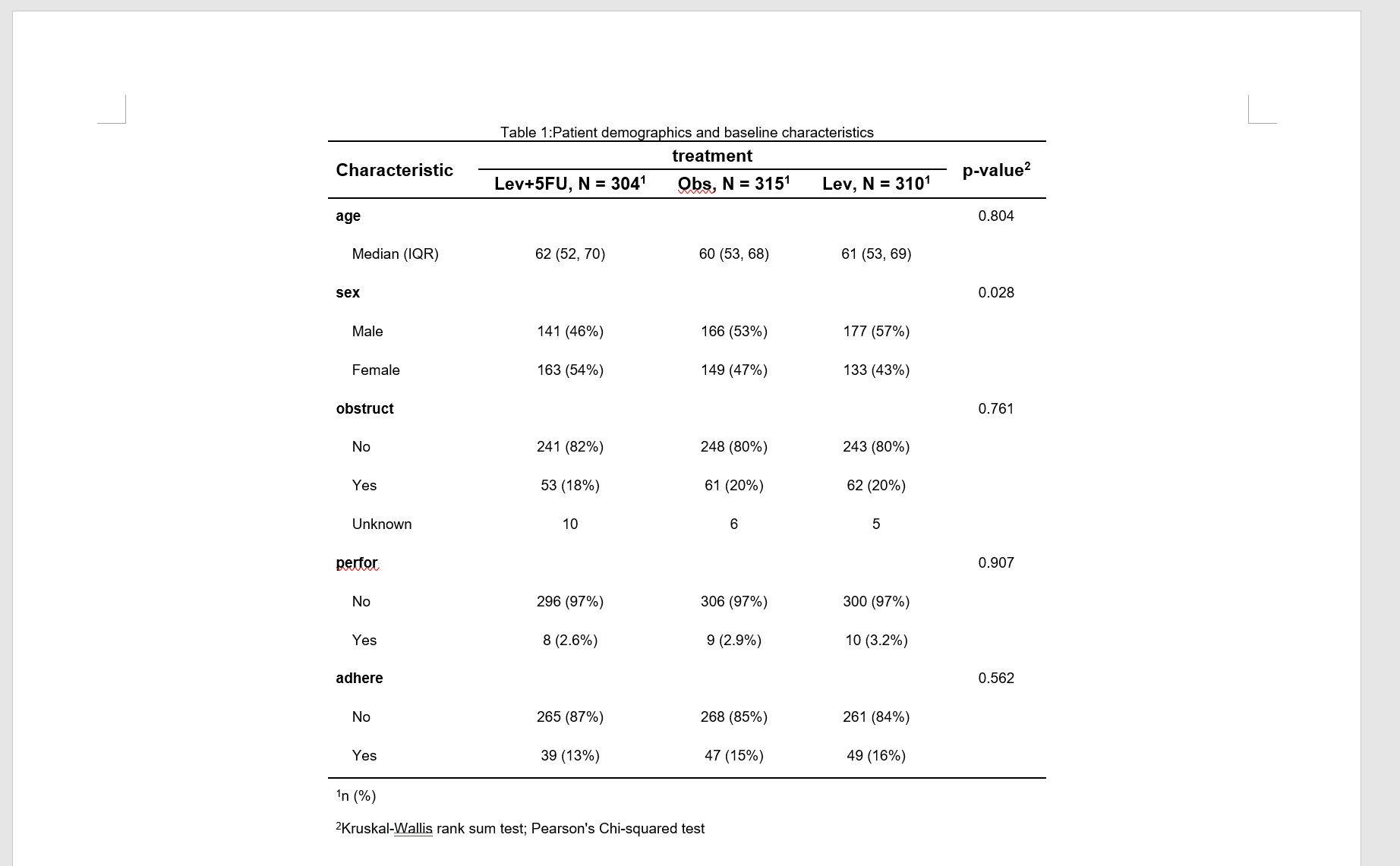

3.2.15 附录:关于基线表统计方法的说明(请复制以下说明方便日后修回时回复审稿人)
3.2.15.1 P 值和统计量的说明
投稿 SCI 期刊,在基线表中,一般对于随机对照研究,做统计描述即可,不做组间比较的 P 值(最好不要做,以避免被嘲讽, 见 Nature 杂志社网站指南:Harvey, L.A. Statistical testing for baseline differences between randomised groups is not meaningful. Spinal Cord 56, 919 (2018). https://doi.org/10.1038/s41393-018-0203-y);
对于非随机对照研究,可以不做,也可以做组间比较, 通常提供 P 值即可,不需要提供统计量如 t 值,F 值,卡方值等等。但是部分国内期刊,审稿人要求提供统计量(傻逼期刊),此时可以 在左侧面板勾选显示统计量的复选框。如果您选择显示统计量 staststic,则 t 检验显示的是 t 值,方差分析显示的是 F 值,卡方检验显示的是卡方值,Fisher’s test 不显示任何统计量(留空),Wilcoxon rank sum test 显示的是 W 值(这里不是 Z 值需注意一下),Exact Wilcoxon 或 Exact Mann–Whitney rank sum tests 不显示任何统计量(留空)
在非随机分组研究中,统计方法选择的说明如下
3.2.15.2 连续性变量:
连续性变量的组间比较用的统计方法,主要根据样本量大小,以及是否正态分布等,通过您在左侧面板自主选择的结果,采用参数法(t 检验,方差分析)或非参数法(秩和检验)。 首选通过 QQ 图来观察是否符合正态分布,再手动勾选每个变量的统计方法;在小样本时,如果嫌麻烦,也可以勾选让计算机 自动进行 SW 正态性检验后自动选择统计学方法。另外在大样本时,直接选择参数法检验也是可以的; 最后,目前在有些顶刊论文中,也发现所有的连续性变量都用非参法如 Wilcoxon rank sum test 进行分析, 不管是否正态分布(仅限于基线表而非结局分析),例如这篇 JAMA. 2020;323(16):1574-1581. doi:10.1001/jama.2020.5394; 主要原理是非参法不依赖于任何数据分布,使用非参法永不出错,只是在符合参数法分布要求的条件下,统计效能低于参数法 (也不低多少,能达到 95%),这一结论见 BMJ 2009; 338 doi: https://doi.org/10.1136/bmj.a3167, 基线表中,统计方法相对宽松,没有结局分析要求那么严格,请灵活选择统计方法,没有硬性规定。
本模块的 t 检验,用的是 Welch’s t-test,可用于方差不齐的情况,和 Student t-test (只能用于方差齐性)结果略有不同。 在论文 Graeme D. Ruxton, The unequal variance t-test is an underused alternative to Student’s t-test and the Mann–Whitney U test, Behavioral Ecology, Volume 17, Issue 4, July/August 2006, Pages 688–690, https://doi.org/10.1093/beheco/ark016 中,阐述了我们可以任何时候直接用 Welch’s t-test 代替 Student t-test 的原理,不再考虑方差齐性的问题。
3.2.15.3 分类变量:
分类变量的组间比较用的统计方法,此处是卡方检验或 Fisher’s 确切概率法,由计算机判定。判定的规则是: 当任意一个列联表格子的期望频率 <5 时,采用 Fisher’s test, 否则采用卡方检验。此处我们不采用连续性校正的卡方(不需要,直接用 Fisher)。 此规则常见于主流的 SCI 杂志、国外教科书、维基百科 Fisher’s test 词条、知名大学统计学家的讲座和文章等。和国内十多年前的教科书有所不同 (国内以前的卫生统计教材用 n=40 作为分水岭,列联表格子数 5 和 1 等情况做出判定), 主要区别是将之前教科书里达到 Yates 连续性校正的卡方检验的情况直接用 Fisher 检验做了替换;此处推荐使用本软件的判定规则(符合国际主流)。
因此,您在论文中可用以下语句描述本基线表组间比较的方法学:For comparison between groups of categorical data, we used the Fisher exact test for expected frequencies of <5, otherwise, we used the Chi-squared test.
以上描述可见于柳叶刀例文:https://www.thelancet.com/journals/eclinm/article/PIIS2589-5370(21)00423-5/fulltext 可能有傻逼审稿人(常见于国内)用以前教科书过时的标准质疑以上规则,直接甩给他这篇论文即可。 什么时候用卡方, 什么时候用 Fisher,我们采用的是国际上目前最通用的做法。
如果您想所有的分析全部用 Fisher 检验而从不考虑卡方检验,大样本的情况下由于计算机算力的问题可能偶尔导致失败,因此我们暂不提供此选项(SAS、Graphpad 等主流统计软件在Fisher失败时也会切换到卡方检验)
关于为什么近年来不再强制推荐 Yates 连续性校正的卡方,而是直接采用 Fisher’s test,主要是来自国际主流统计学家的反对,因为 Yates 连续性校正卡方 的初衷是让卡方检验更精确,但是在大样本的情况下,普通卡方检验和 Yates 连续性校正的卡方检验差别很小,而在小样本的情况下,不管做不做 Yates 连续性校正,卡方 检验都不够精确,在计算机算力发达的当下,直接做 Fisher’s test 即可,无需画蛇添足再做 Yates 连续性校正的卡方,这一业内共识在 Graphpad 的说明书中 有以下总结: The chi-square test is only an approximation. The Yates continuity correction is designed to make the chi-square approximation better, but it over corrects so gives a P value that is too large (too ‘conservative’). With large sample sizes, Yates’ correction makes little difference, and the chi-square test works very well. With small sample sizes, chi-square is not accurate, with or without Yates’ correction. Statisticians seem to disagree on whether or not to use Yates correction.
当偶尔遇到 P 值为空的情况,是因为符合 Fisher 检验的条件,但由于样本量大等原因导致计算失败(常见于分组过多例如七八个分组,且有些格子频数很低时, 而四格表一般不会遇到这种情况),此时可以考虑合并一些亚组,或到本软件“统计方法分类”的列联表模块,手动进行卡方检验或 Fisher 检验后填入)
3.2.15.4 关于中位数和分位数的说明
当样本量较小时,本软件计算中位数或四分位数的结果和 SPSS 不一样, 本软件用的为 R 软件的默认设置: quantile(numbers, probs = c(0.25, 0.5, 0.75))。这个 结果和 SPSS 有差异,百分位数的计算根据业界引用最多的论文 Hyndman, R. J. and Fan, Y. (1996) Sample quantiles in statistical packages, American Statistician 50, 361–365. 10.2307/2684934. 一共有 9 种不同的定义 type1 ~ type9,R 软件默认采用的是 type = 7,这个计算结果和 SPSS 不同,如有差异请以本软件为准。
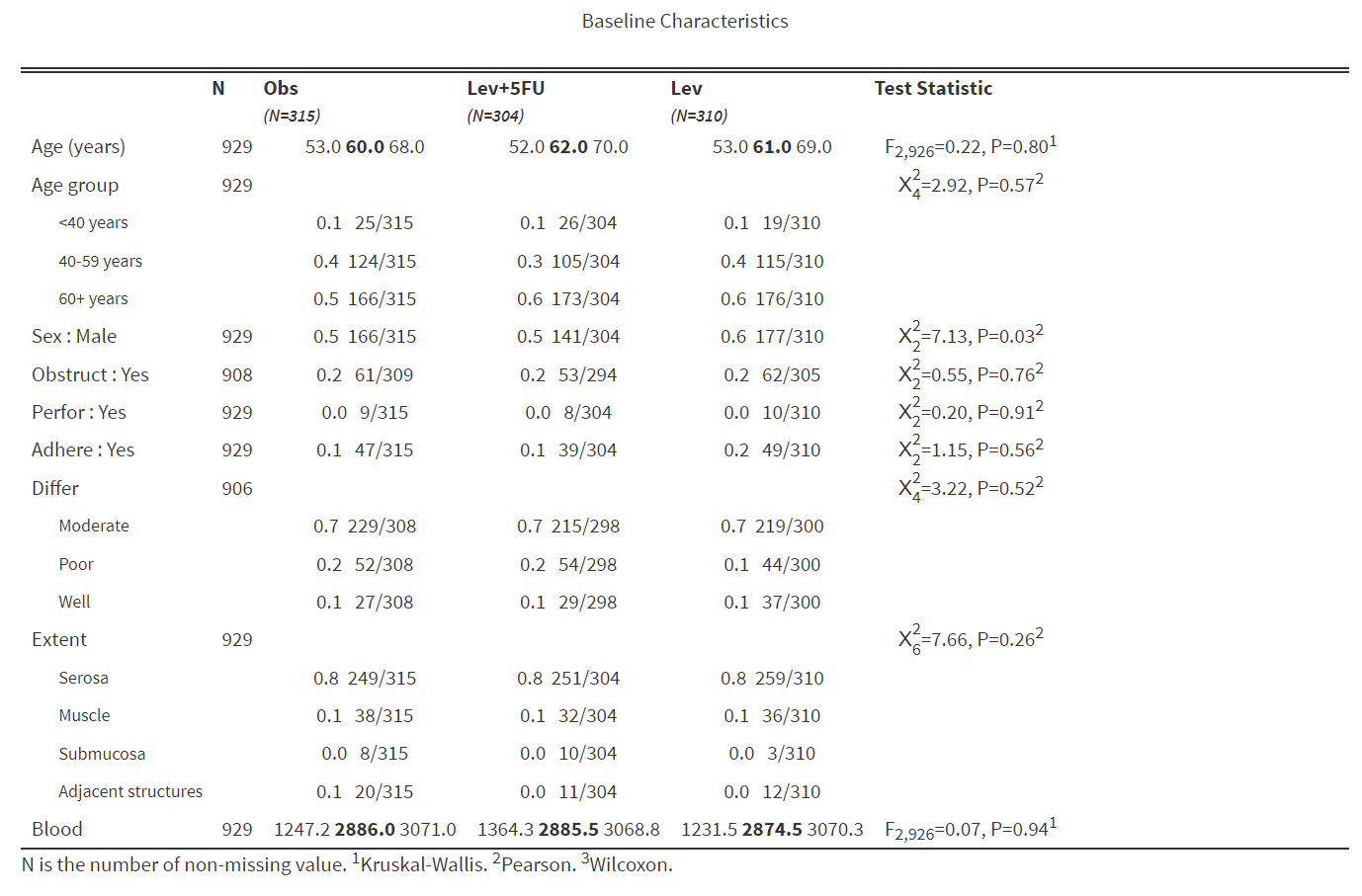
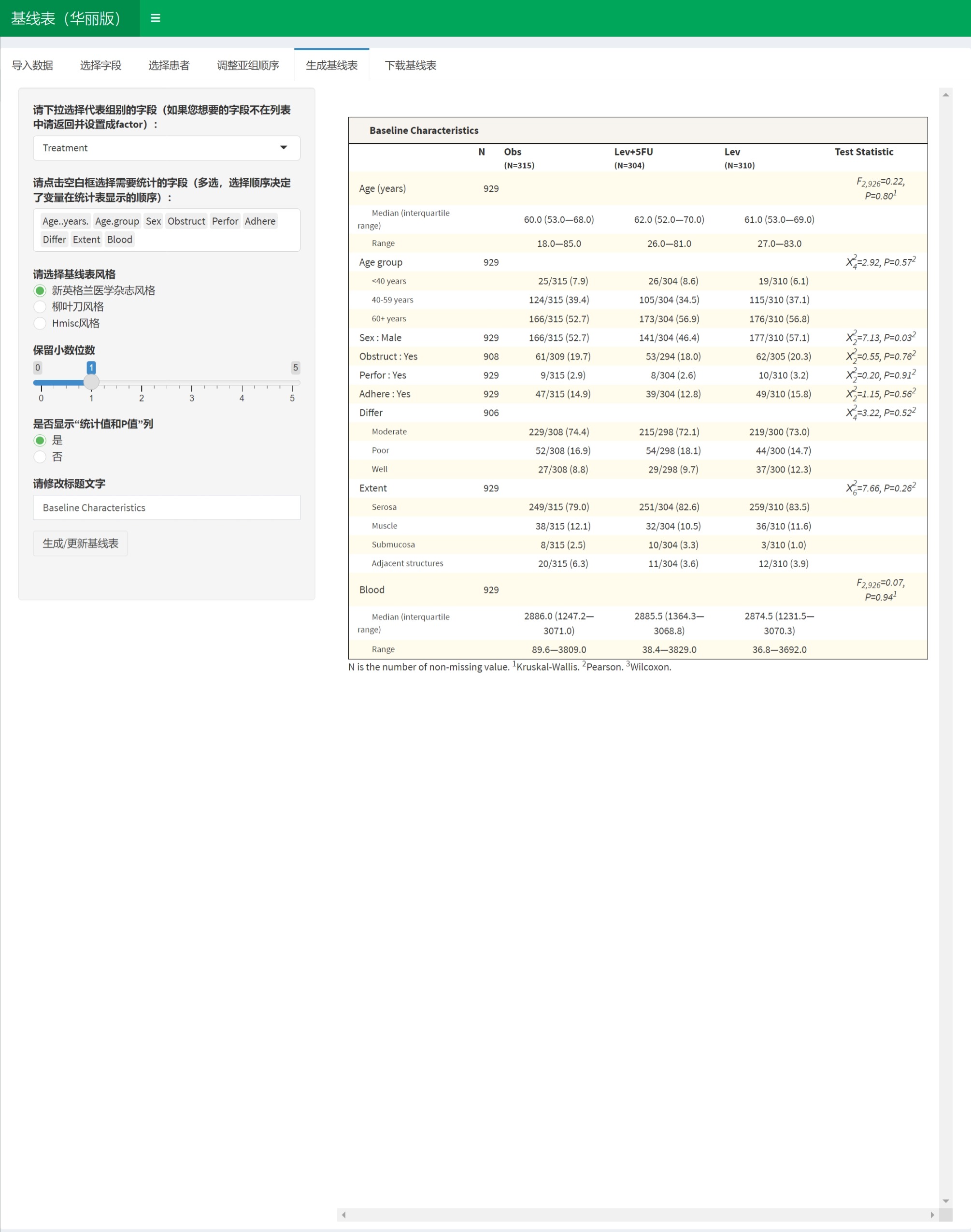
3.3 一键生成基线人口学和临床特征表(华丽版)
这是一款智能进行统计分析的工具,用来生成论文里患者基线水平的多组比较的表格(Table One)。可以生成新英格兰杂志、柳叶刀、Hmisc三种风格的表格。本工具功能较简单,可用于PPT演示等非正式场合。但如果需要用于论文,还请移步采用一键生成基线人口学和临床特征表(全能版)模块。
新英格兰杂志风格:
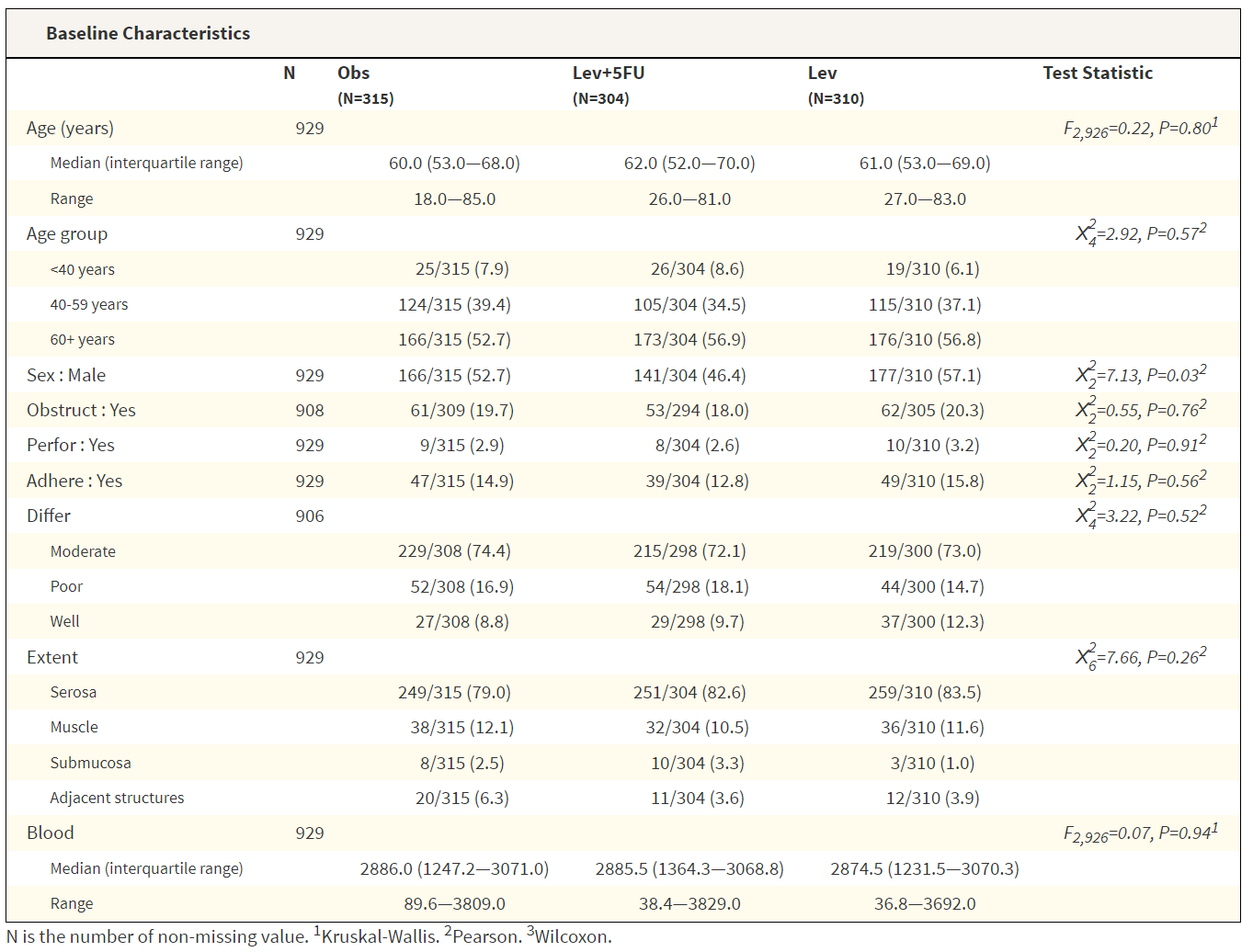
柳叶刀风格:
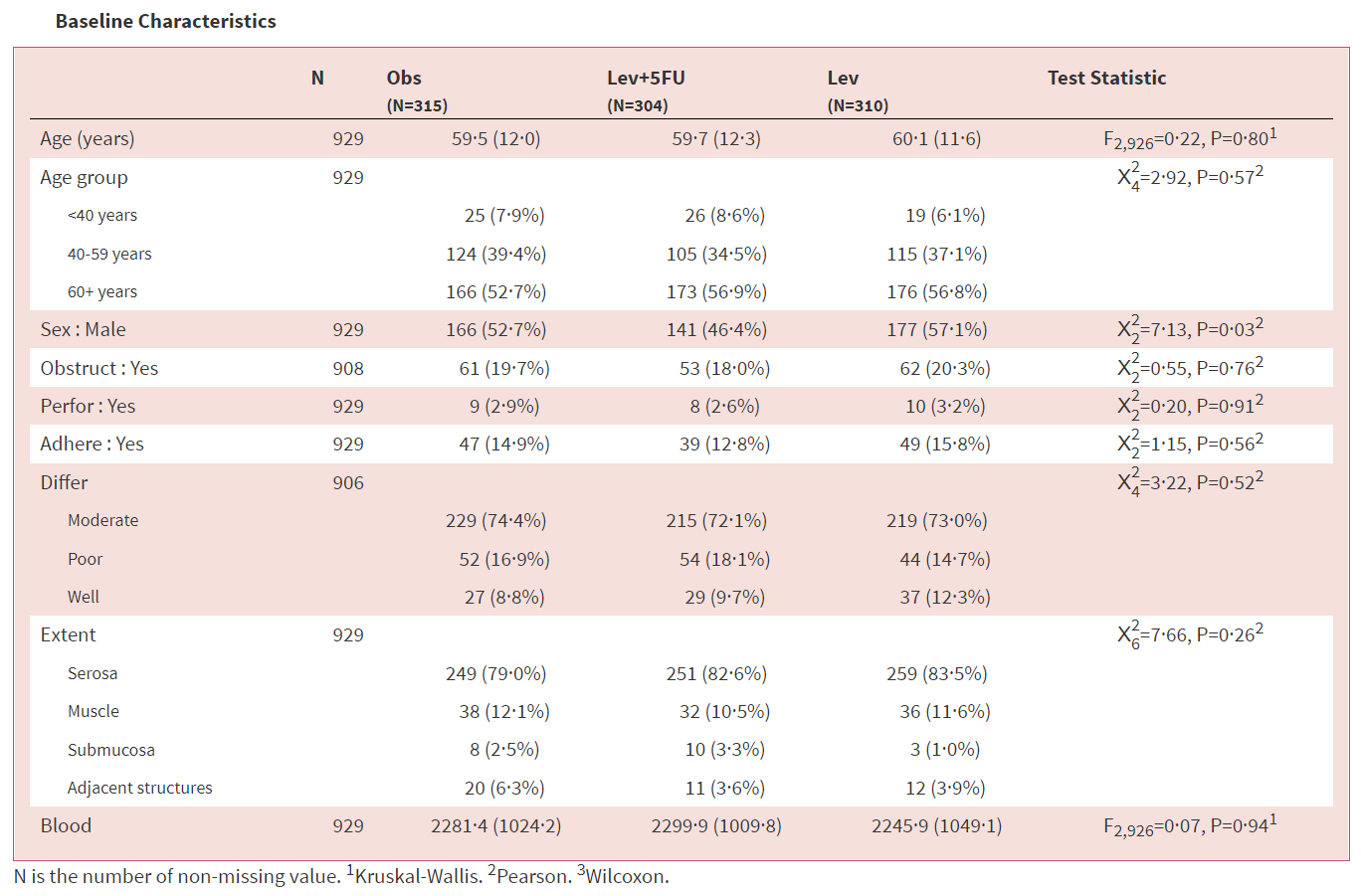
Hmisc风格:
3.3.1 准备数据
按照下图准备数据:
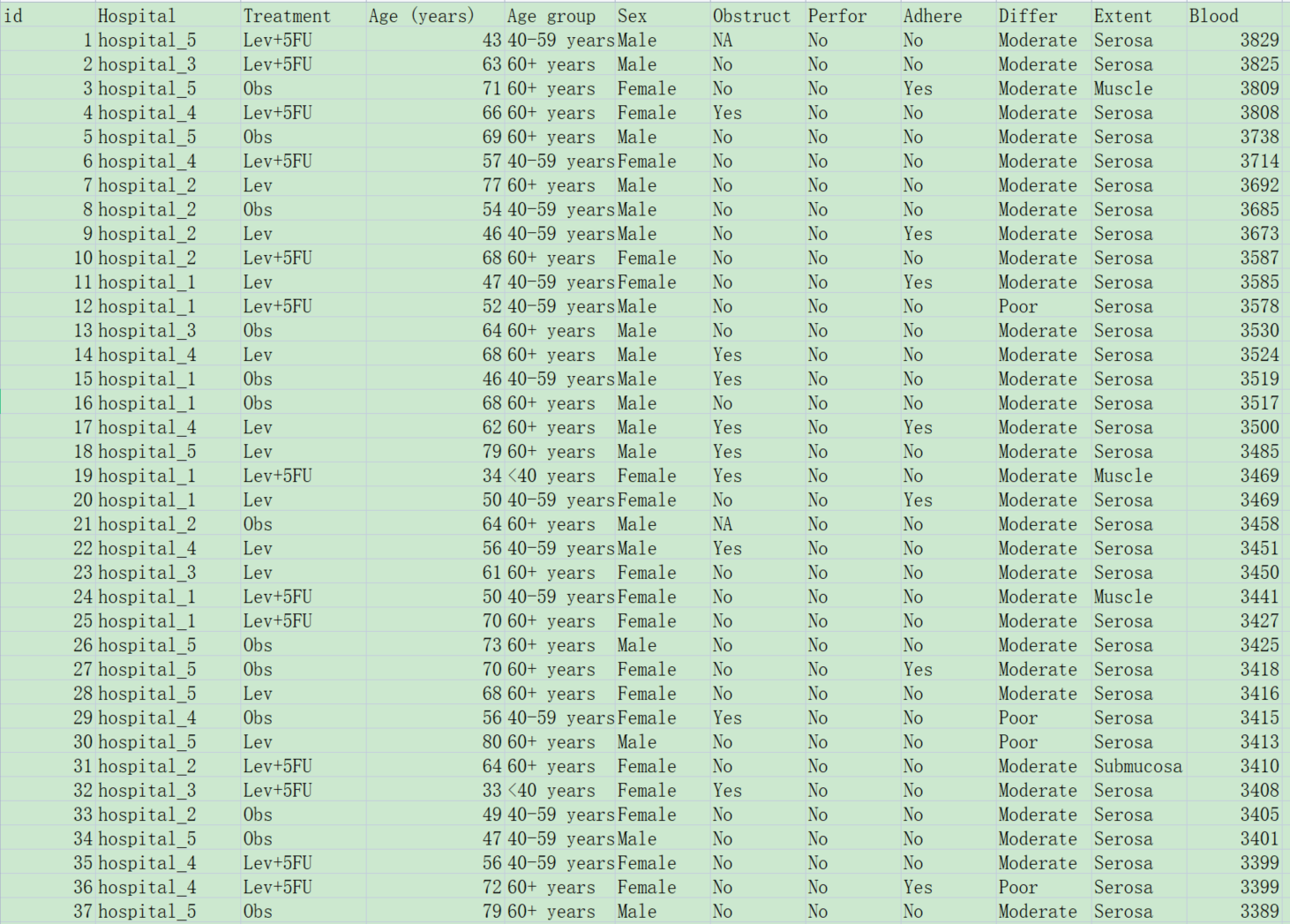
本样例数据的规则:
一个患者一行(这是准备数据最重要的前提)。
本例中Treatment为分组变量,下面有三个组别。
所有变量分为连续性变量和分类变量两种,连续性变量(值是连续数据,它可以在变量值所属区间内任意进行取值,如年龄(岁)、血糖值、人的身高、智商等)以及分类变量(是说明事物类别的一个名称,其取值是分类数据。如”性别”就是一个分类变量,其变量值为”男”或”女”;“行业”也是一个分类变量,其变量值可以为”零售业”、“旅游业”、“汽车制造 业”等),在本例中 Age和Blood是连续性变量(numeric), 其他的是分类变量(factor)。
以上概念很重要,后面有一个页面专门设置连续变量和分类变量。
3.4 一键完成描述性统计(批量统计所有字段,生成文字、表格、统计图)
描述性统计分析(Descriptive Statistical Analysis)是一种统计方法,用于收集、整理、概括和呈现数据的重要特征和信息。它能帮助我们更好地理解数据集的基本情况和概况,但并不涉及对数据进行推断或预测。描述性统计分析主要包括以下几个方面:
集中趋势测量:这些测量指标能反映数据的中心位置,如平均数(mean)、中位数(median)和众数(mode)。
离散程度测量:这些指标衡量数据的分散程度,即数据值相对于中心位置的变异大小。常见的离散程度指标有极差(range)、四分位差(interquartile range, IQR)、方差(variance)和标准差(standard deviation)。
分布形状:描述数据分布的偏态(skewness)和峰度(kurtosis)。偏态反映了数据分布的对称性,而峰度描述了数据分布的陡峭程度。Shapiro-Wilk正态性检验,Q-Q图等。
数据的可视化展示:通过图形和表格的方式,直观地呈现数据的分布和关系,如条形图(bar chart)、直方图(histogram)、散点图(scatter plot)、饼图(pie chart)等。
总之,描述性统计分析主要关注数据的概括和呈现,而不涉及对数据的解释、预测或因果关系的分析。它是数据分析的第一步,为进一步的推断统计分析和建模提供基础。
本软件提供了一站式的描述性分析步骤:
- 批量分析数据库中所有变量或分组描述 n(总数)、缺失值(missing values)、均值(mean)、均值的标准误(standard error of the mean)、均值的置信区间(confidence interval of the mean)、置信水平(confidence level)、中位数(median)、众数(mode)、标准差(standard deviation)、方差(variance)、四分位数间距(interquartile range, IQR)、全距(range)、最小值(minimum)、最大值(maximum)、偏度(skewness)、峰度(kurtosis)、正态性Shapiro-Wilk检验结果(normality Shapiro-Wilk test result)、百分位数(percentiles),并给出统计表;
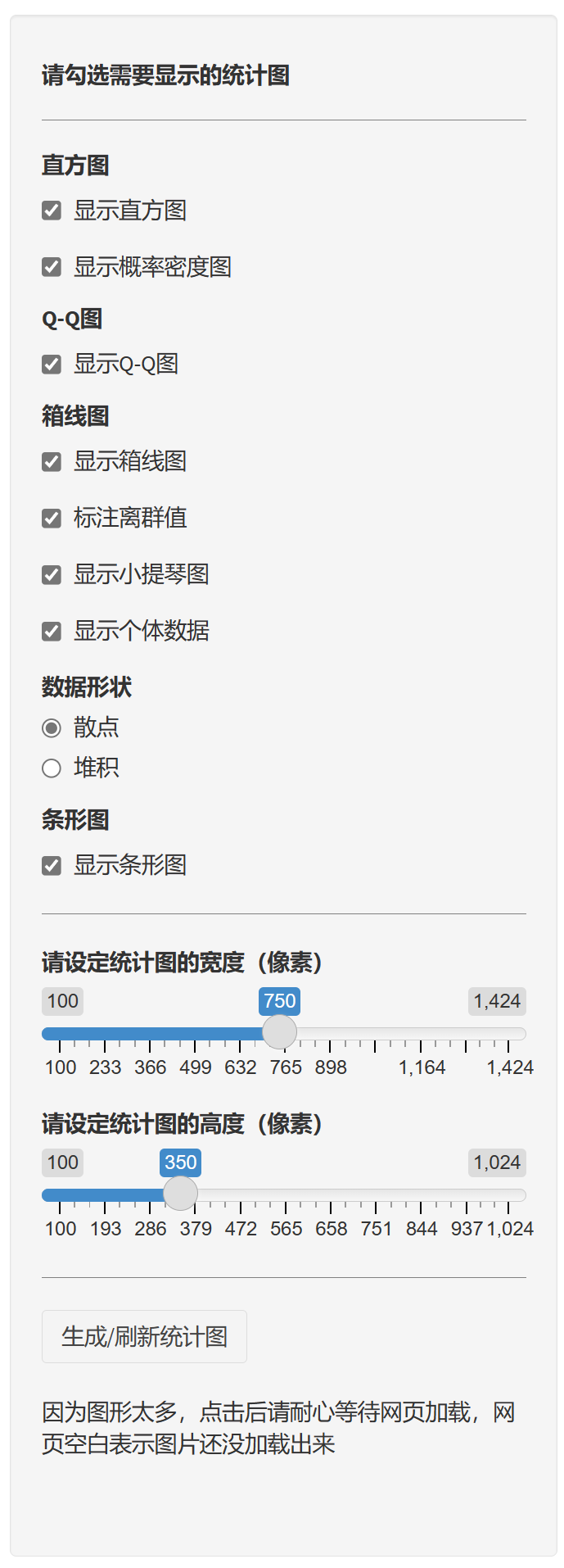
- 批量分析数据库中所有变量或分组展示直方图(histogram)、概率密度图(probability density plot)、Q-Q图(Q-Q plot)、箱线图(box plot)、小提琴图(violin plot)、散点图(scatter plot)、堆积图(stacked plot)、条形图(bar chart);
- 对数据库中所有变量进行文字描述,可分组描述。






3.5 全自动问卷量表描述分析(李克特量表等)
3.5.1 背景介绍
李克特量表(Likert Scale)得名于美国心理学家Rensis Likert,是当今社会科学、医学、教育等领域广泛应用的调查工具。李克特量表主要用于衡量受访者对某个观点、态度或体验的看法强度,特别适合测量“同意-不同意”、“满意-不满意”这类主观意见。
李克特量表的典型形式是将每个调查问题(item)设置为一个有序的等级反应,常见的有五点式或七点式。例如,五点式李克特量表的选项通常为:
非常同意
同意
既不同意也不完全同意(中立)
不同意
非常不同意
每个选项被视为一个有序的分类变量,通过数字进行编码以便于统计分析。
如果量表采用奇数个选项,中间的选项通常用于表达“中立”或“没有意见”,因此无需单独设置“不了解/不知道”等选项。而如果量表采用偶数个选项(如四点式或六点式),则中立选项被省略,受访者需要在偏正面或偏负面的选项中做出选择,这种设置被称为“强制选择”或“无中立选项”设计。
李克特量表的优点在于能够对主观意见进行量化,使研究人员能够通过统计方法分析群体或亚组之间的态度分布和差异,是问卷调查中最常用的量表类型之一。
3.5.2 原始数据格式要求
在进行李克特量表分析前,用户需要准备一个符合以下要求的数据文件(推荐CSV或Excel格式):
数据的结构:
每一行代表一个调查对象(如一名患者或一位学生)的全部回答。
每一列代表一个调查问题
可以增加代表组别的分类变量(如性别、年龄分组或科室等)。
数据类型要求:
每个调查问题的答案,尽量用原始的答案选项文本,例如(非常同意、 同意、 既不同意也不完全同意(中立)、 不同意、 非常不同意 ),尽量不要用 1,2,3,4 等数字。如果您的数据库里记录的就是数字编号(如1,2,3,4,5),在软件中的变量属性设置时,也要确保设置为“分类变量(factor)”类型。
分组变量(如班级、性别等)也必须设置为分类变量(factor),而非数值变量。
一致性原则:
每次分析时,仅能同时分析答案选项数量一致的量表问题(例如所有问题都是五点式量表)。
不同选项数量的问题需分批次单独分析,避免混合分析造成误差。
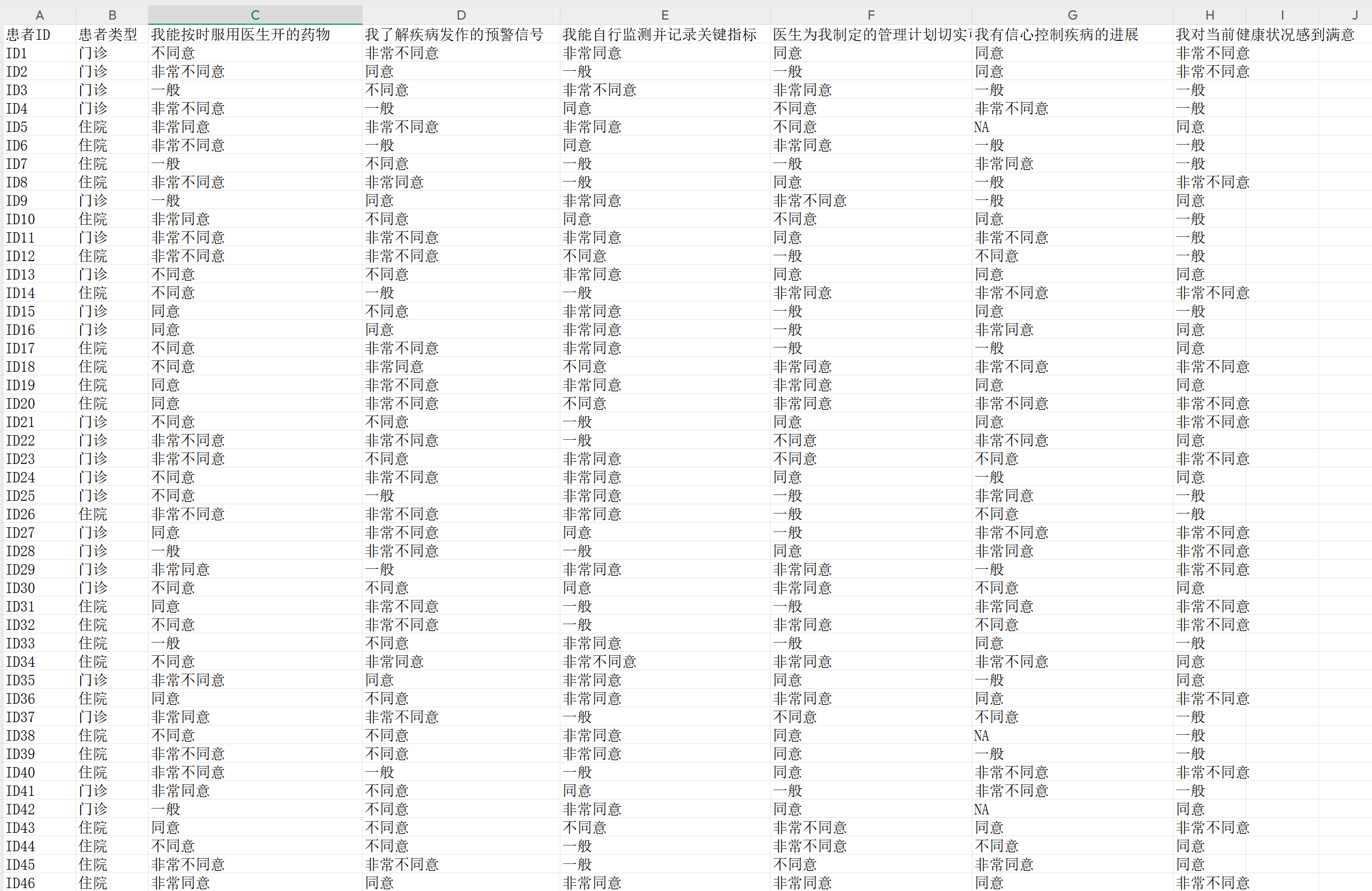
3.5.4 基本设置(必选)
上传数据
- 进入统计机器人软件平台后,点击“数据准备”功能,将您准备好的CSV或Excel文件导入。
变量选择
在界面上选择需要分析的量表问题,务必确保这些问题的答案选项数量一致。
软件会自动识别变量类型,只有设置为分类变量的量表问题才会显示供您选择。
选项排序
软件会自动列出您选择的问题所有的答案选项。
请手动拖拽这些选项,确保从最负向到最正向(或从低到高)进行排序,这一步至关重要,排序错误会影响分析结果。

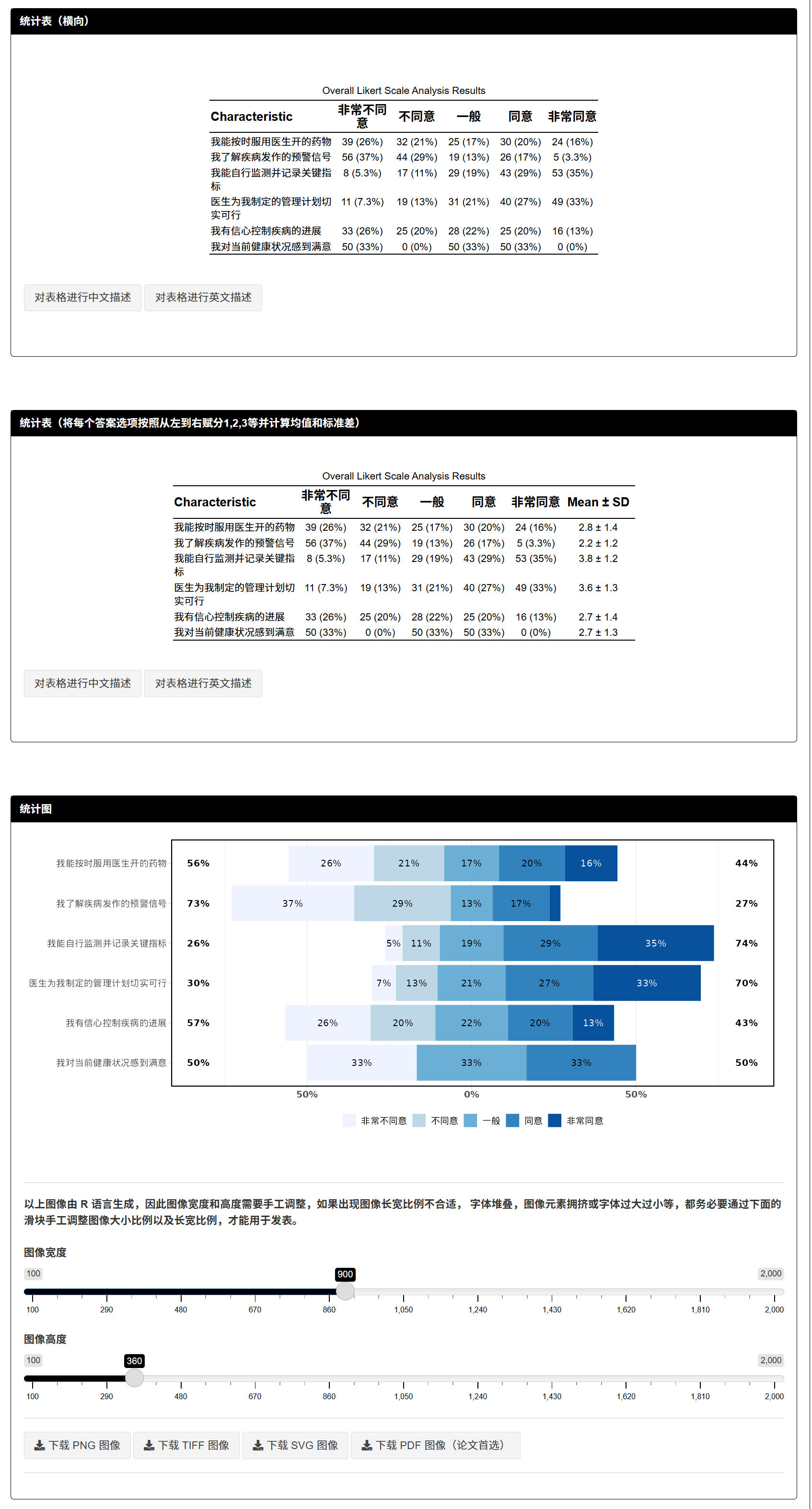
3.5.5 总体调查人群分析
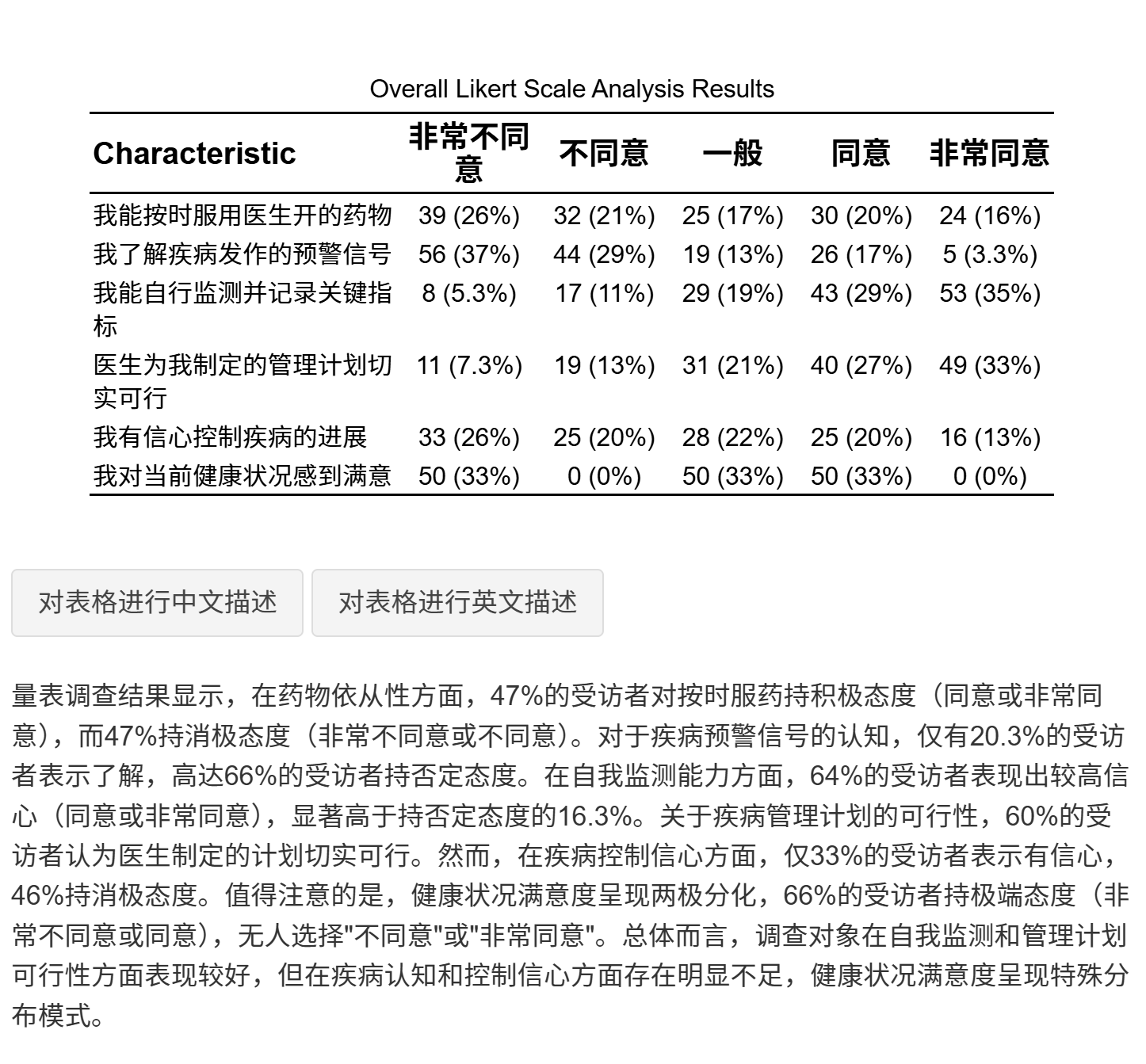
统计表设置
选择量表答案的展示方式:
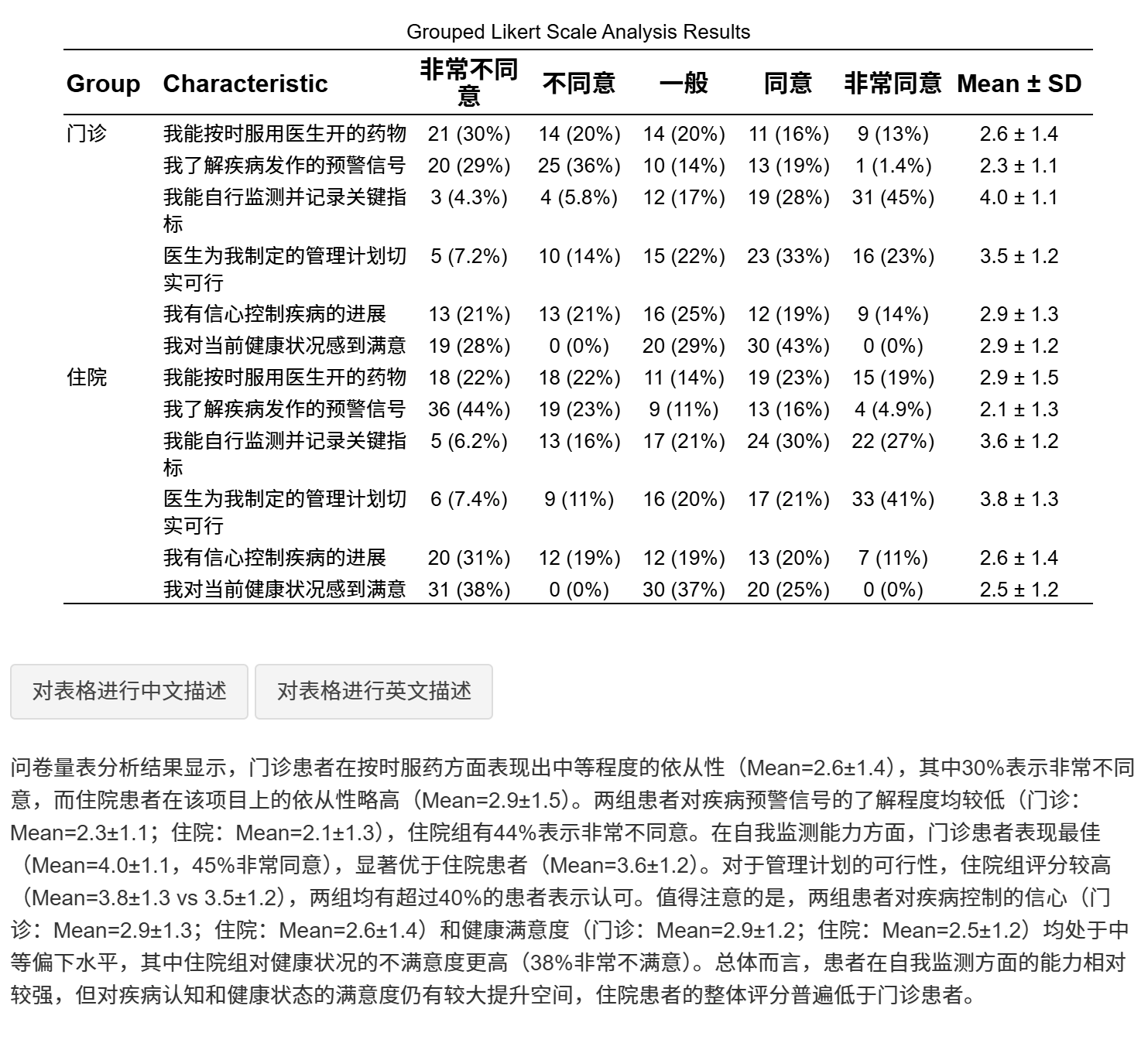
每个选项以样本量 n (%) 的形式显示。
增加总样本数N,选项显示为百分比(推荐用于存在缺失数据的情况)。
设置统计指标:可选择统计均值±标准差或中位数与四分位数间距(IQR)。
设置统计指标的小数位数。
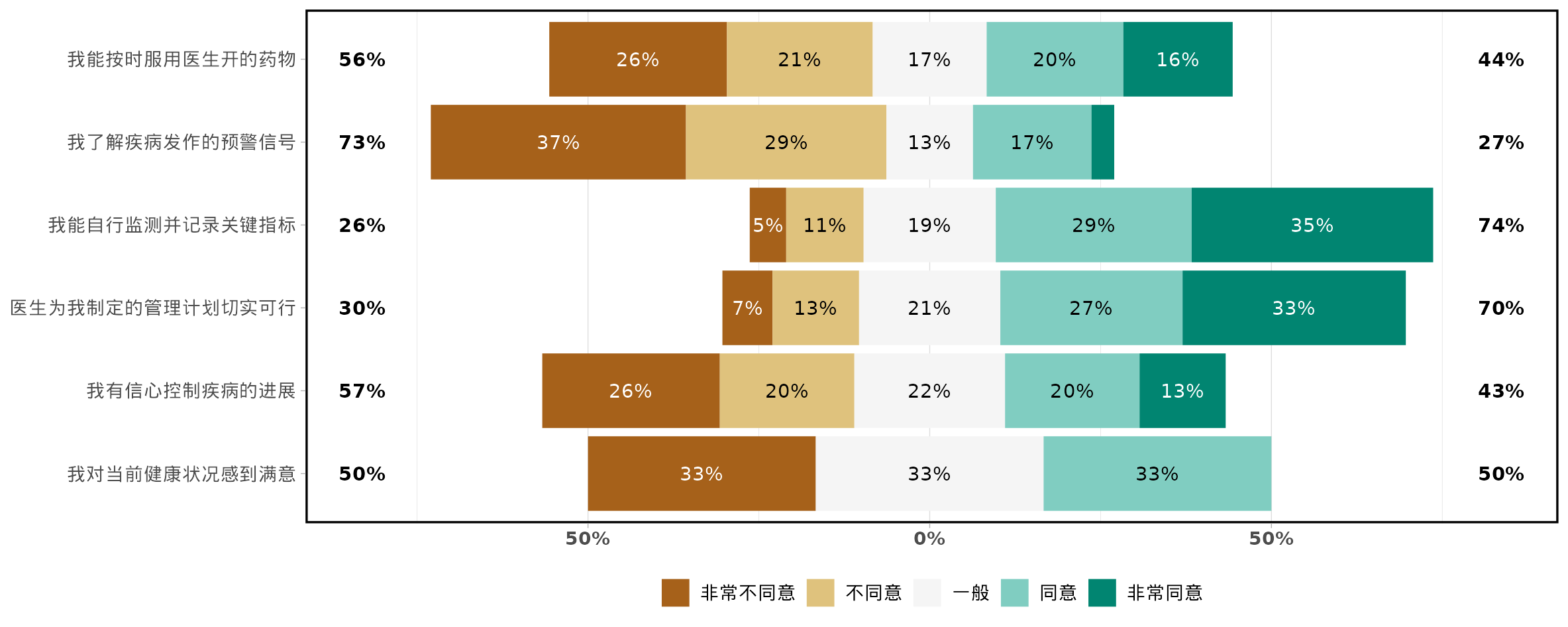
统计图设置
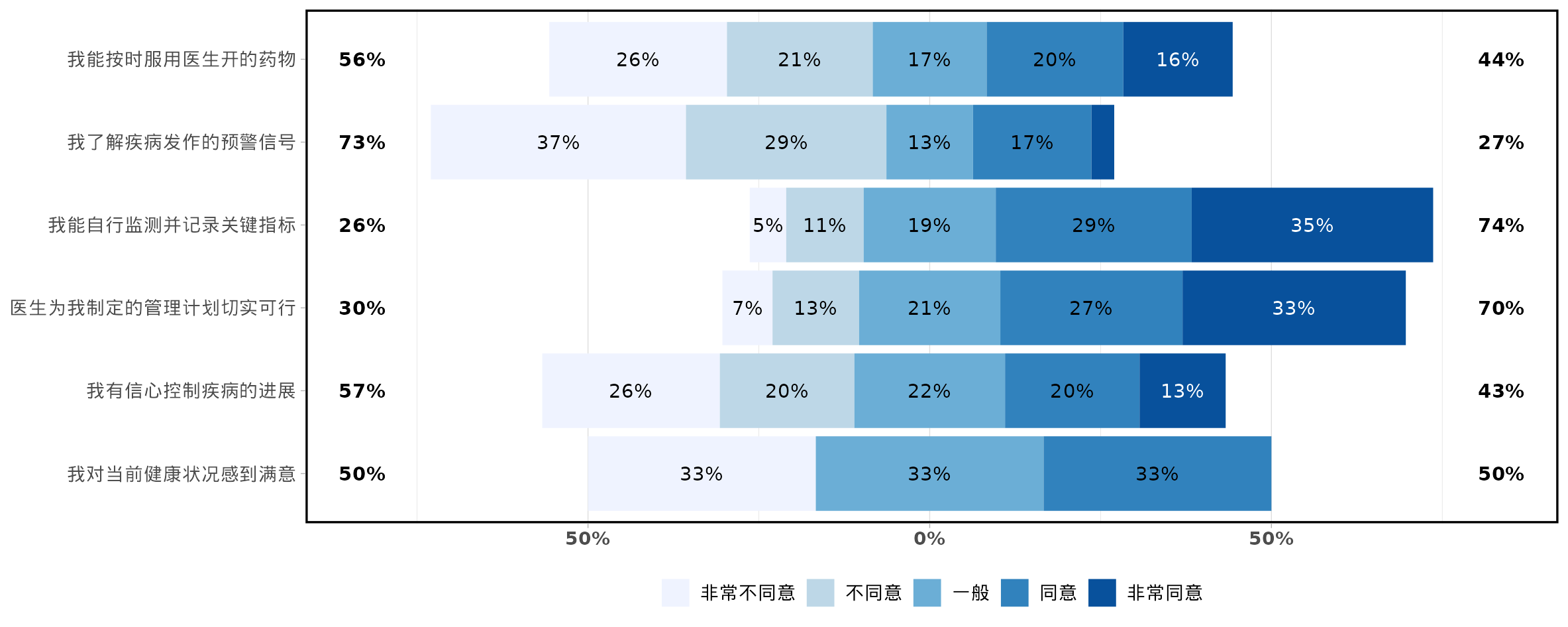
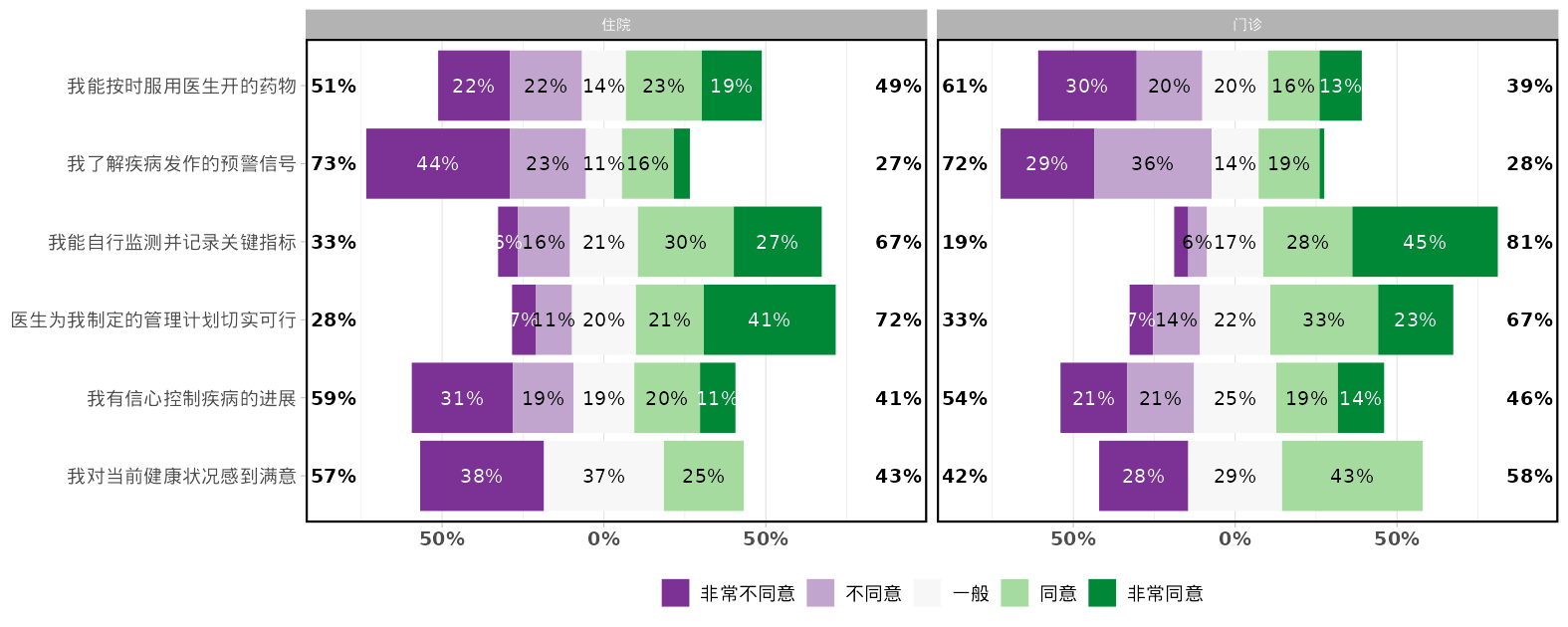
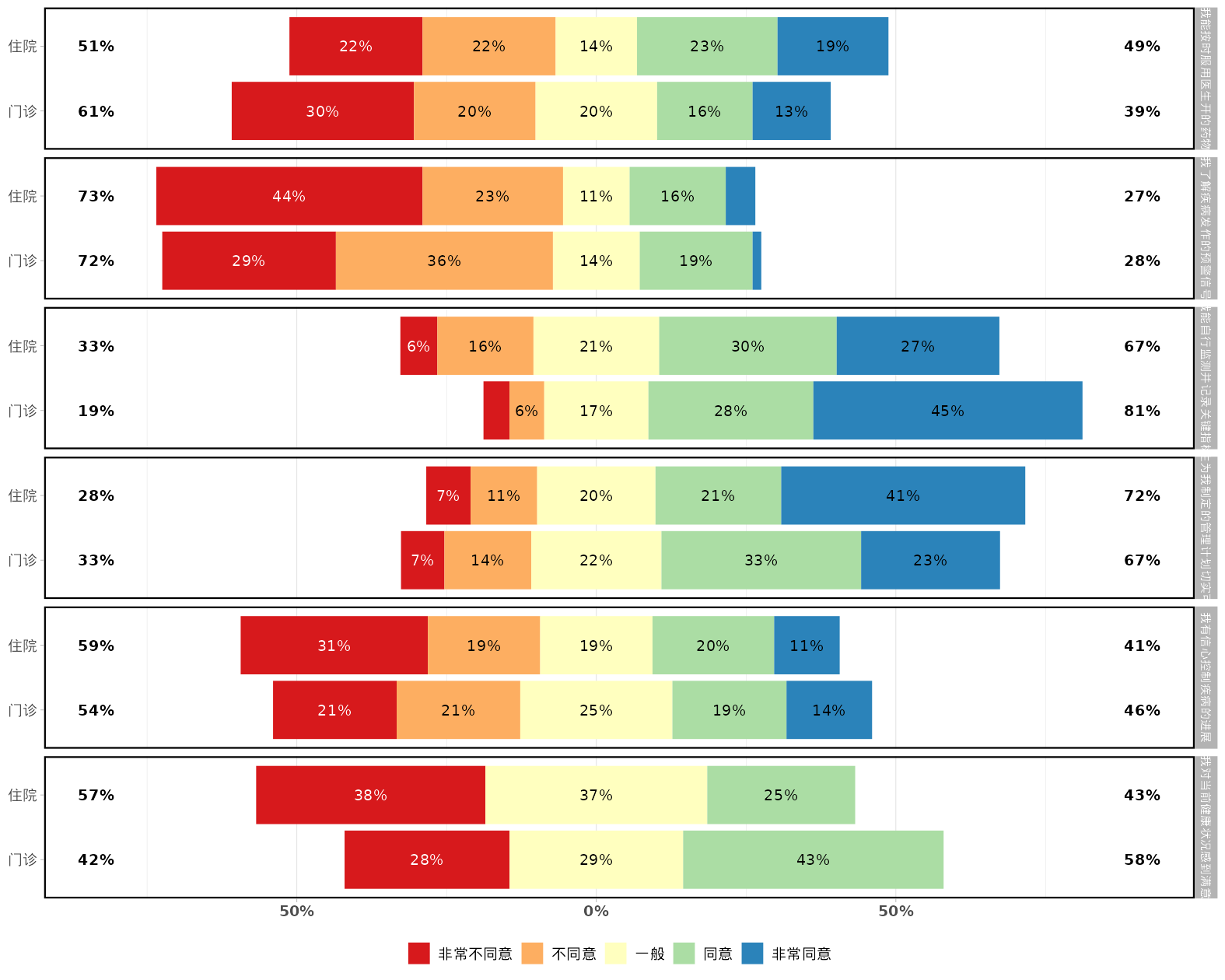
选择是否使用经典李克特量表图(显示累计百分比)或普通堆积条图。
决定最中心选项是否计入累计百分比计算(适用于奇数选项量表)。
设置量表问题排序方式(如按量表得分高低排序)。
选择图表的配色方案。
可自定义坐标轴、图例和条图百分比字体大小。

生成分析结果
点击界面上的“生成/更新分析”按钮。
软件会自动生成统计表格和统计图,呈现调查人群整体的量表分析结果。