Chapter 7 预测研究
7.1 nomogram - Logistic - 二分类结局(拆分训练集和验证集,列线图/ROC/校准曲线/DCA曲线,一键生成 SCI 论文)
本工具能够一键完成Logistic - nomogram(列线图)的临床预测研究分析,并自动生成一篇 30 多页的 SCI论文初稿。
分析的流程为:上传数据 -> 处理数据 -> 拆分训练集和验证集 -> 基线特征表 -> Lasso 回归筛选变量 -> 评价每个入选因子的 ROC 曲线 -> Logistic 建模 -> 绘制普通 nomogram -> 在训练集和验证集整体评价ROC -> 绘制 calibration 校准曲线 -> 绘制 DCA 曲线 -> 制作一个互动 nomogram 并部署到个人网站 -> AI 撰写论文
整个过程视网络速度情况,从上传数据到论文生成,约5-8分钟完成,点击鼠标20次左右。

7.1.1 前言
Nomogram,也叫作诺模图,是一种图形计算器,用于将数学公式或者复杂的统计模型转化为直观易用的图表。诺模图是一种强大的工具,可以用于可视化复杂模型的预测,通过滑动各变量标尺,就可以直观地得到预测结果,从而可以有效地为决策提供依据。在医学研究中,尤其是临床决策中,使用 nomogram 可以便捷地预测疾病的风险,评估治疗方案的效果等。
例如,在研究糖尿病发生的风险时,我们可以将年龄、性别、体重指数等危险因素作为预测变量,结合 Logistic 回归模型,制作出一个 nomogram。通过该 nomogram,我们可以快速直观地了解不同年龄、性别和体重指数下,糖尿病发生的风险大小。
本软件软件提供了丰富的功能支持,包括:
一键拆分训练集和验证集
一键生成基线特征表
一键完成 Logistic 建模
绘制经典 nomogram:本软件 不仅可以实现 Logistic 回归模型的构建和评估,还可以直接生成 nomogram,将复杂的模型转化为易于理解的图形,帮助用户直观地理解和解释模型结果。
绘制网页动态 nomogram:这是一个相对更加现代化的方式,用户可以在网页上交互式地操作 nomogram,调整预测变量的值,并直接看到预测结果的变化。这种方式可以使nomogram 更加动态,有助于更深入地理解模型。
一键部署到用户的个人网站:本软件 还提供了一键部署的功能,用户可以将自己制作的动态 nomogram 部署到自己的个人网站上,提供给其他人使用。而且,用户可以将自己部署nomogram 的网址附在论文里,使得读者能够更方便地使用 nomogram,增强论文的可读性和实用性。
一键完成 ROC 曲线
一键完成 Calibration 校准曲线
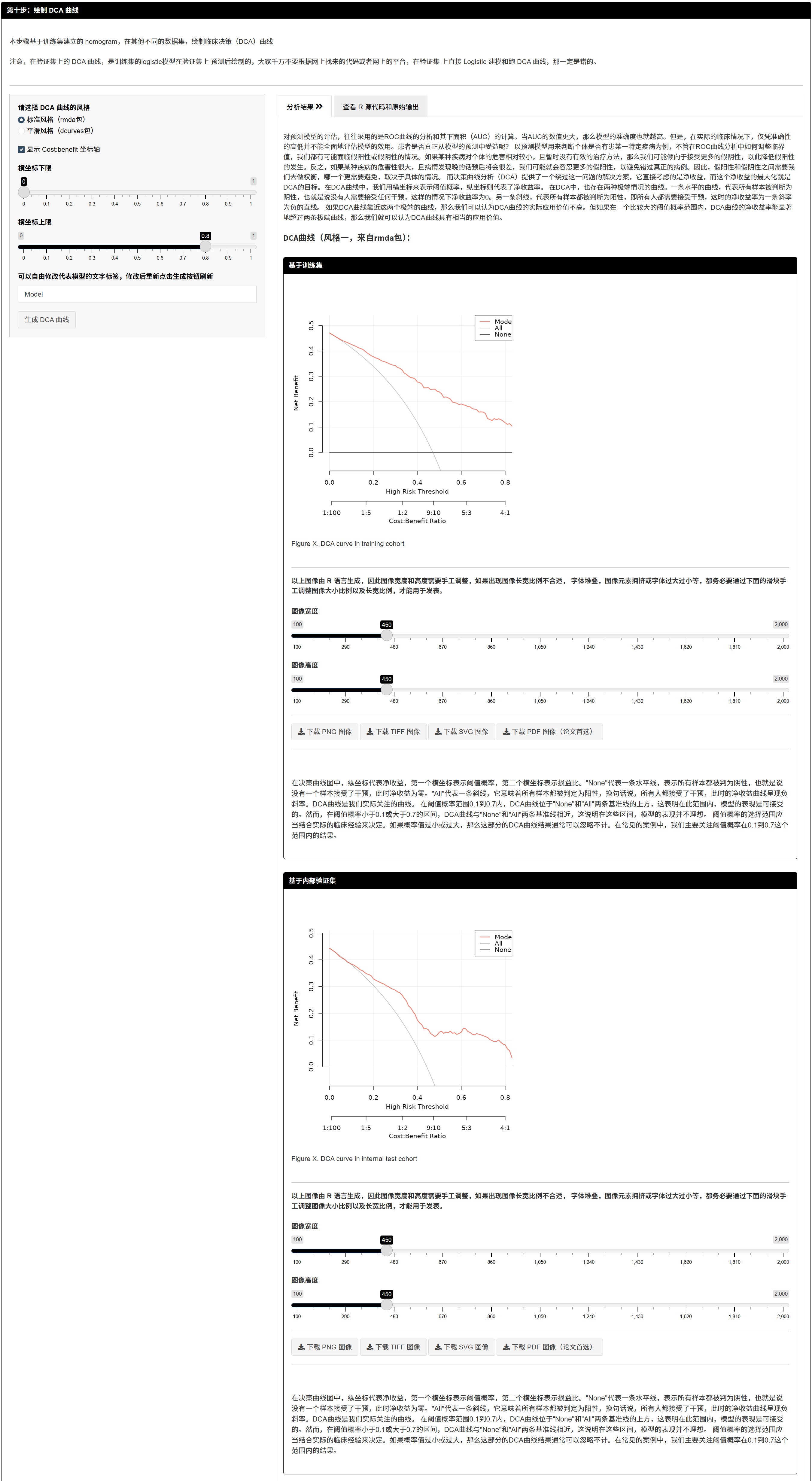
一键完成 DCA 曲线
一键完成 SCI 论文的撰写
综上所述,无论是经典的 nomogram 还是动态的 web 版 nomogram,都可以在 本软件 中轻松实现。这无疑使得 本软件 成为了一款强大的统计分析和可视化工具。
7.1.2 数据准备
导入数据后,如果有缺失数据,缺失值在 20% 以下的变量,可以酌情考虑做缺失值填补,这里首选随机森林法进行填补。缺失值 20%-40% 的变量,需要慎重考虑;缺失值 40% 以上的变量,建议不放入模型。
有两种数据模式,有外部验证集和没有外部验证集。
没有外部验证集,只有内部集时,请按照以下方式准备数据:
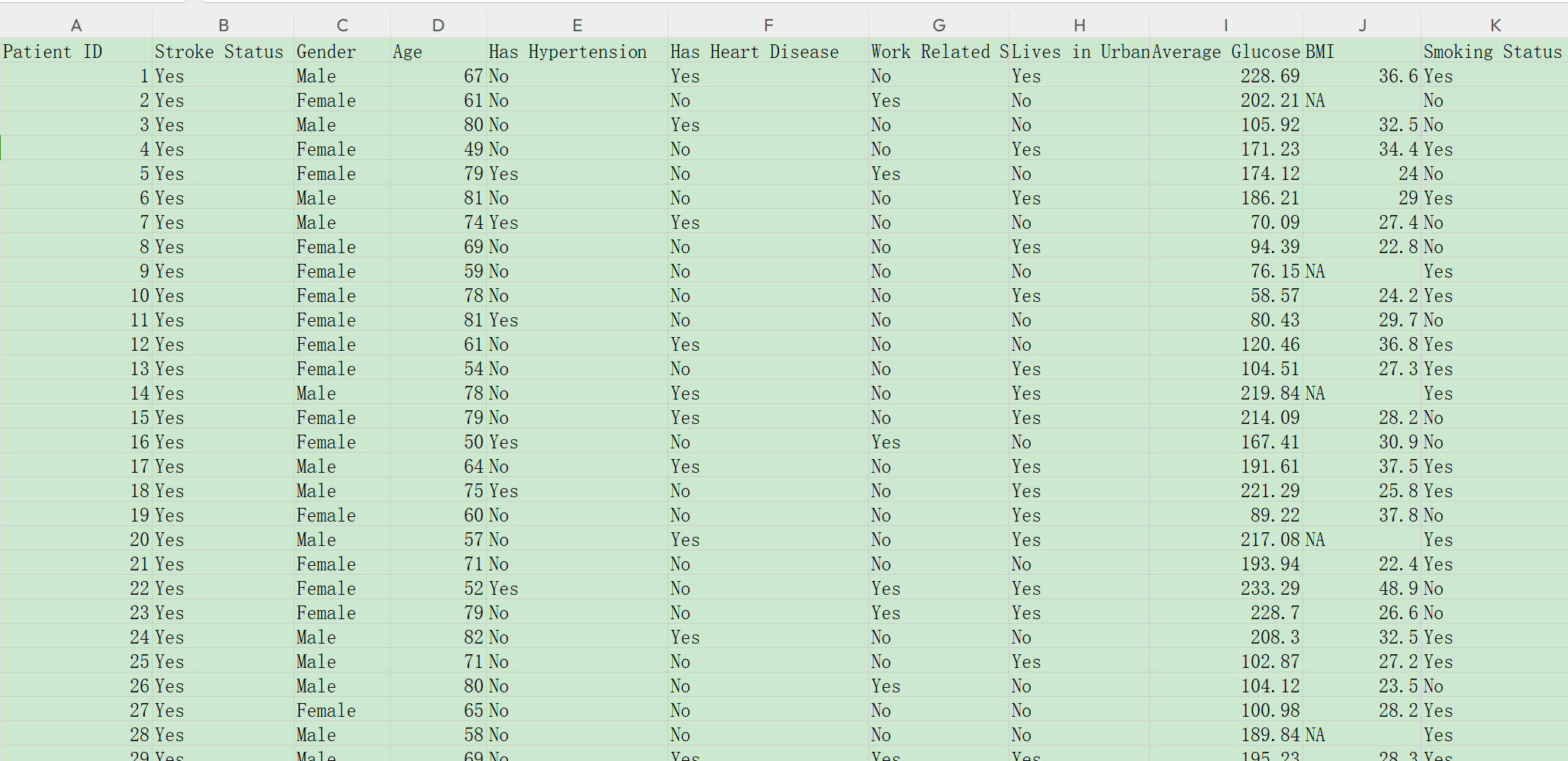
这里包括二分类的结局 Stroke Status (“Yes”, “No”), 以及多个预测因子。
如果既有内部集,又有外部验证集,请把两个集合在一起准备数据:
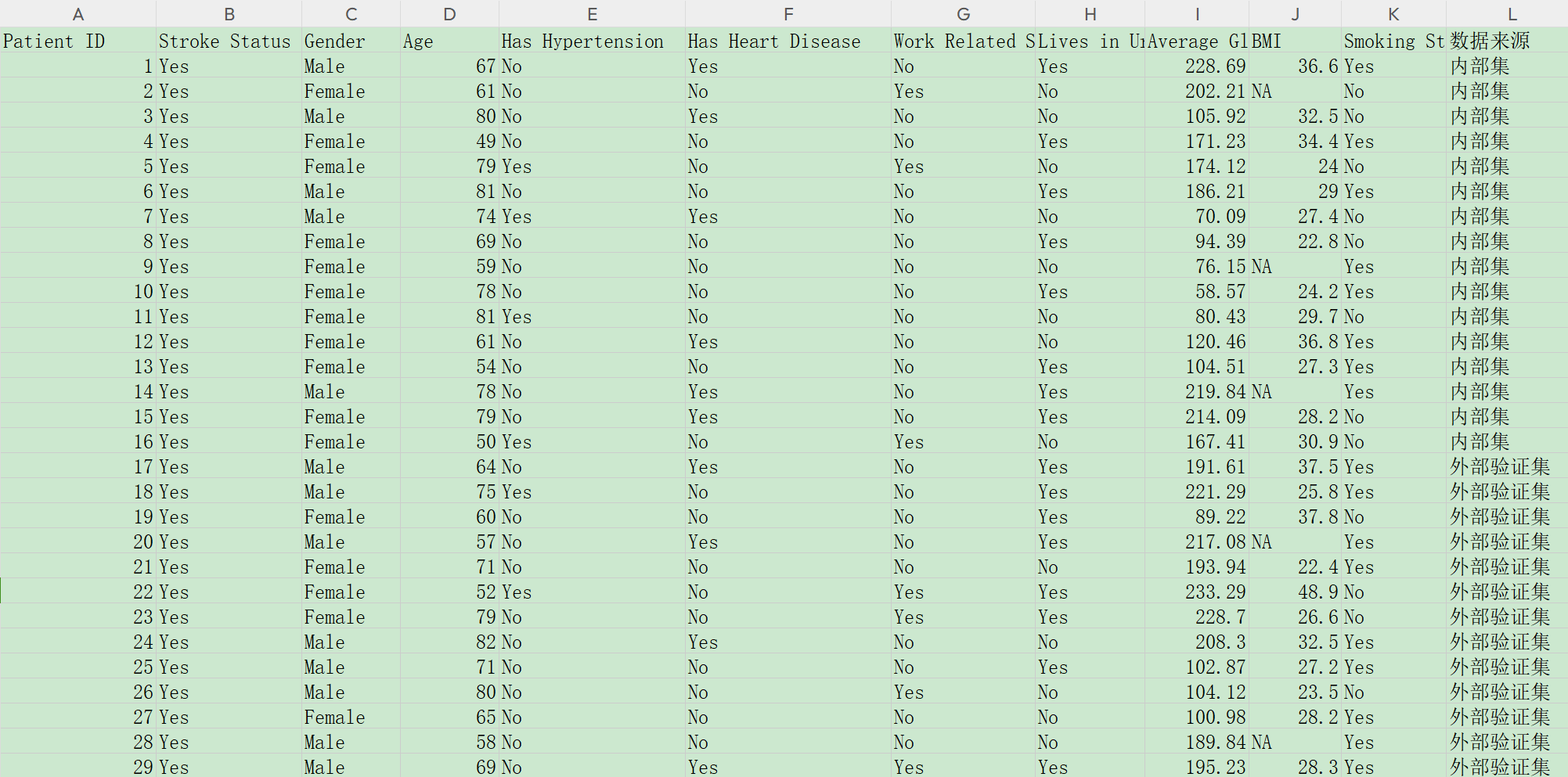
这里把内部集和外部集纵向合并起来,并增加一列在末尾,标示出那个是内部集,哪个是外部验证集。
后面分析的时候,系统会按要求将内部集拆分成训练集和内部验证集。然后以训练集、内部验证集、外部验证集三个队列来分别做基线人口学特征表。
7.1.3 进入模块
接下来我们进入模块,点击软件顶部菜单的“预测研究”,然后点击“Logistic - 二分类结局 nomogram (拆分训练集和验证集,列线图/ROC/校准曲线/DCA曲线,一键生成 SCI 论文)” 进入模块。
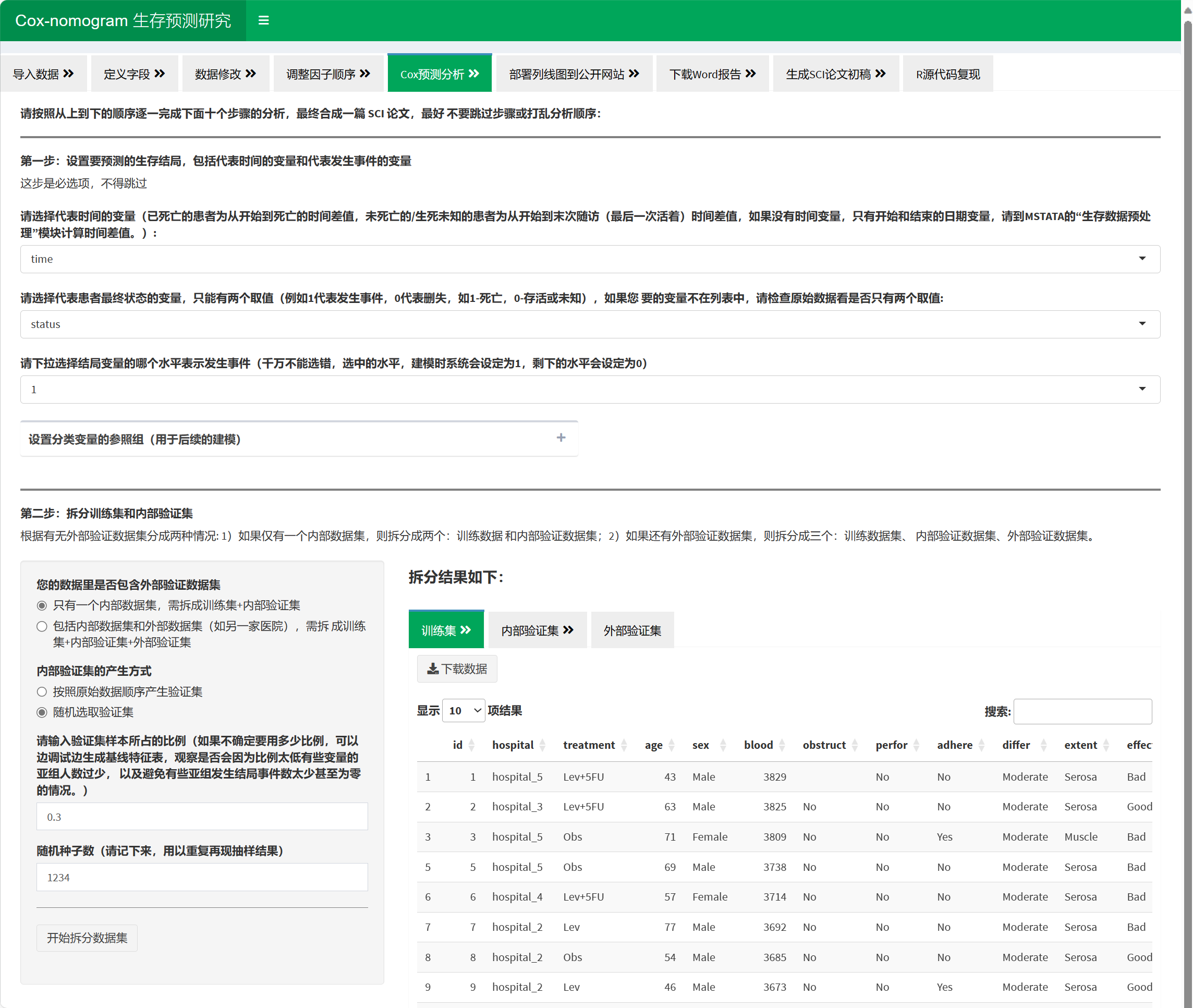
7.1.4 研究基础设置与数据拆分
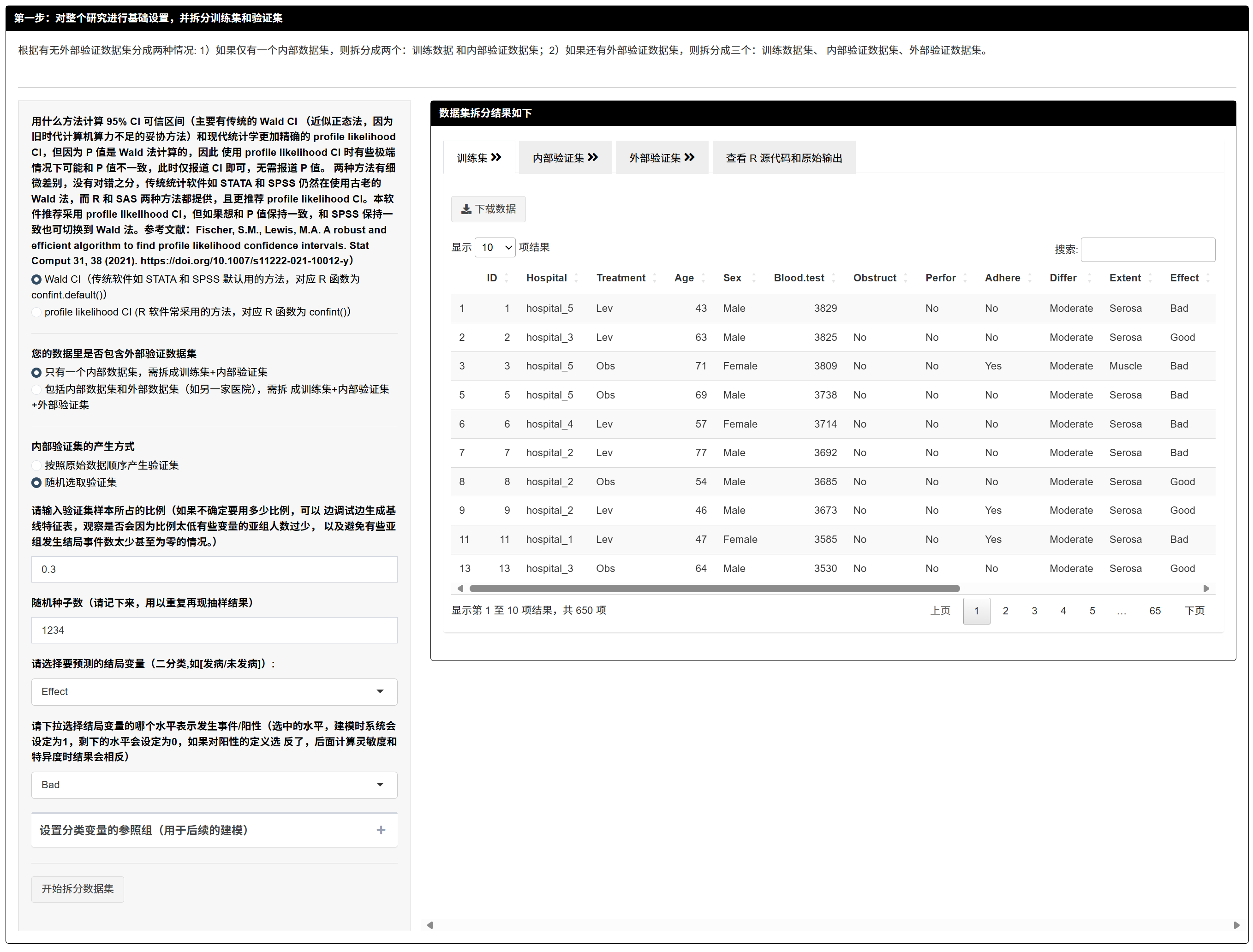
你需要做的: 1. 选择CI 口径(Wald 或 Profile likelihood)。 2. 指定是否含外部数据;若有,选择来源变量与外部标识。 3. 设定内部验证集产生方式(顺序/随机)、比例与随机种子。 4. 选择结局变量及事件水平(系统将其编码为 1)。 5. 为每个分类自变量设置参考组。
系统输出:训练集 / 内部验证集 / 外部验证集(如有)预览与下载;并可查阅拆分 R 代码。
提醒:随机拆分务必记录种子以复现;拆分后请注意是否出现极少或 0 事件的亚组。
7.1.4.1 置信区间口径(CI):Wald vs. Profile likelihood
Wald CI(大样本近似)
原理:基于估计量的渐近正态性,用“估计值 ± z*标准误”构造区间(例如 log(OR) 的标准误来自模型的协方差矩阵)。
优点:计算极快;大样本、参数远离边界时覆盖率好。
局限:样本量偏小、事件稀少、参数接近边界(如 OR→∞、分离/separation)时,Wald CI 往往过窄或偏乐观。
Profile likelihood CI(轮廓似然)
原理:对目标参数逐点“定值”,把其他参数极大化,比较似然比(基于 Wilks 定理)反求出使似然比检验不过度显著的参数区间。
优点:对小样本、稀有事件、非正态/偏态问题更稳健,覆盖率通常优于 Wald。
局限:计算更慢;个别模型可能出现轮廓不稳定或不收敛,需要良好的初值与收敛控制。
7.1.4.2 内部验证集的产生方式、比例与随机种子
方式选择
随机拆分(默认):模拟重复抽样,常分层按结局保持事件率稳定(e.g., stratify by outcome)。
顺序拆分:按时间/入组顺序前段作训练、后段作验证,贴近前瞻性应用场景,用于有明显时间演化/实践漂移的任务。若用“顺序”但数据表无时间列,应先按时间字段排序。
比例为何默认 0.3(验证集 30%)
经验上 70/30 在多数中等样本任务里兼顾了:
训练:保留足够观测以稳定估计(尤其是事件数)。
验证:留出有代表性的样本评估泛化误差(例如 AUC、Brier score 的方差不会过大)。
当样本量或事件数偏少时,固定留出法(hold-out)不稳,优先 k 折交叉验证或 bootstrap 内部验证(移步到本软件另一个不拆分验证集的模块);若坚持留出,提高训练占比(如 80/20)以保证训练集事件数达标。
事件数(以二分类回归为例)
建模训练集建议满足传统 EPV≥10(每个待估参数至少 10 个事件),现代研究常建议 10–20 更稳健。若训练集达不到,调整变量数/正则化/改用重抽样验证。
随机种子
为可重复性,固定 set.seed()
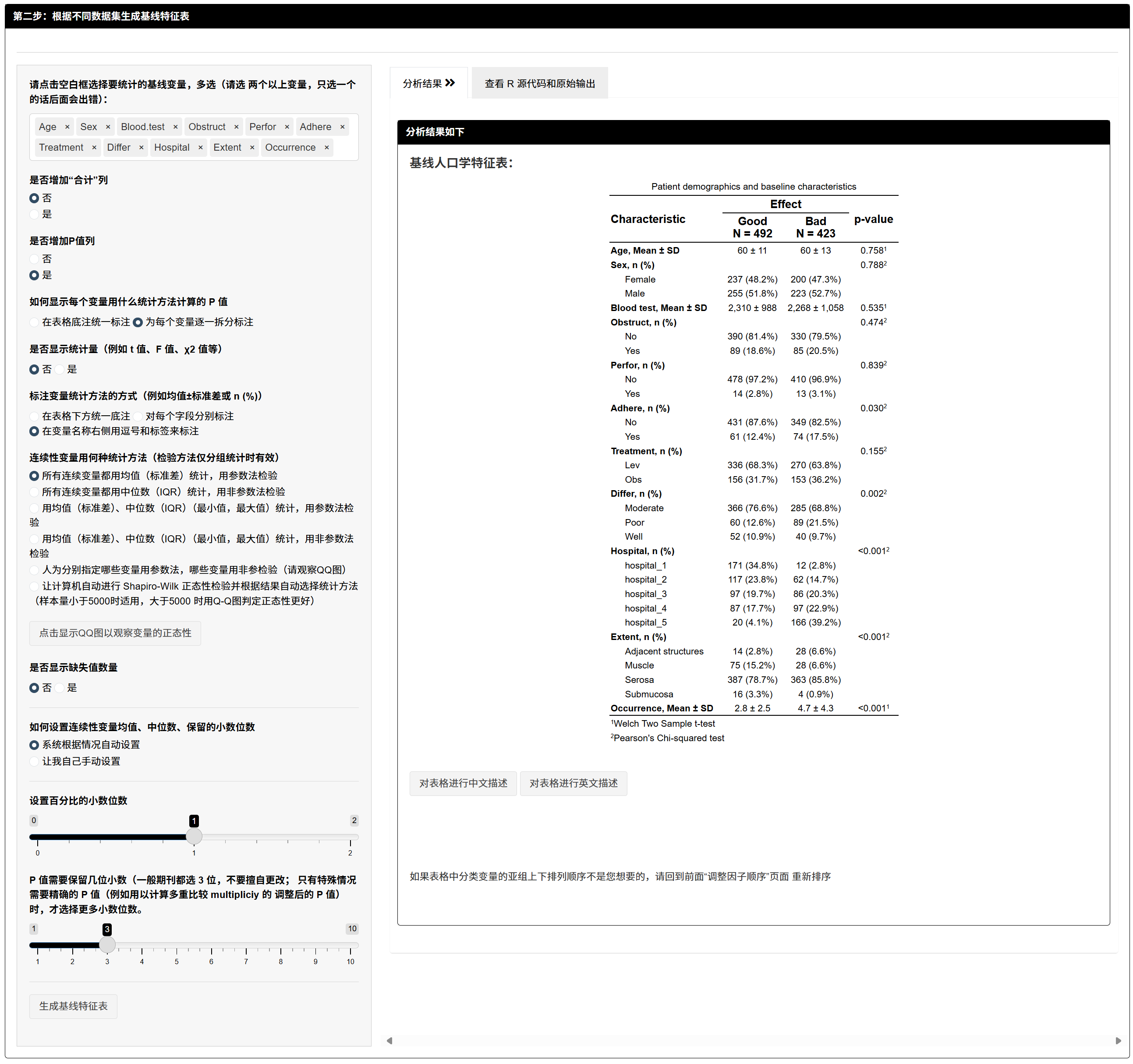
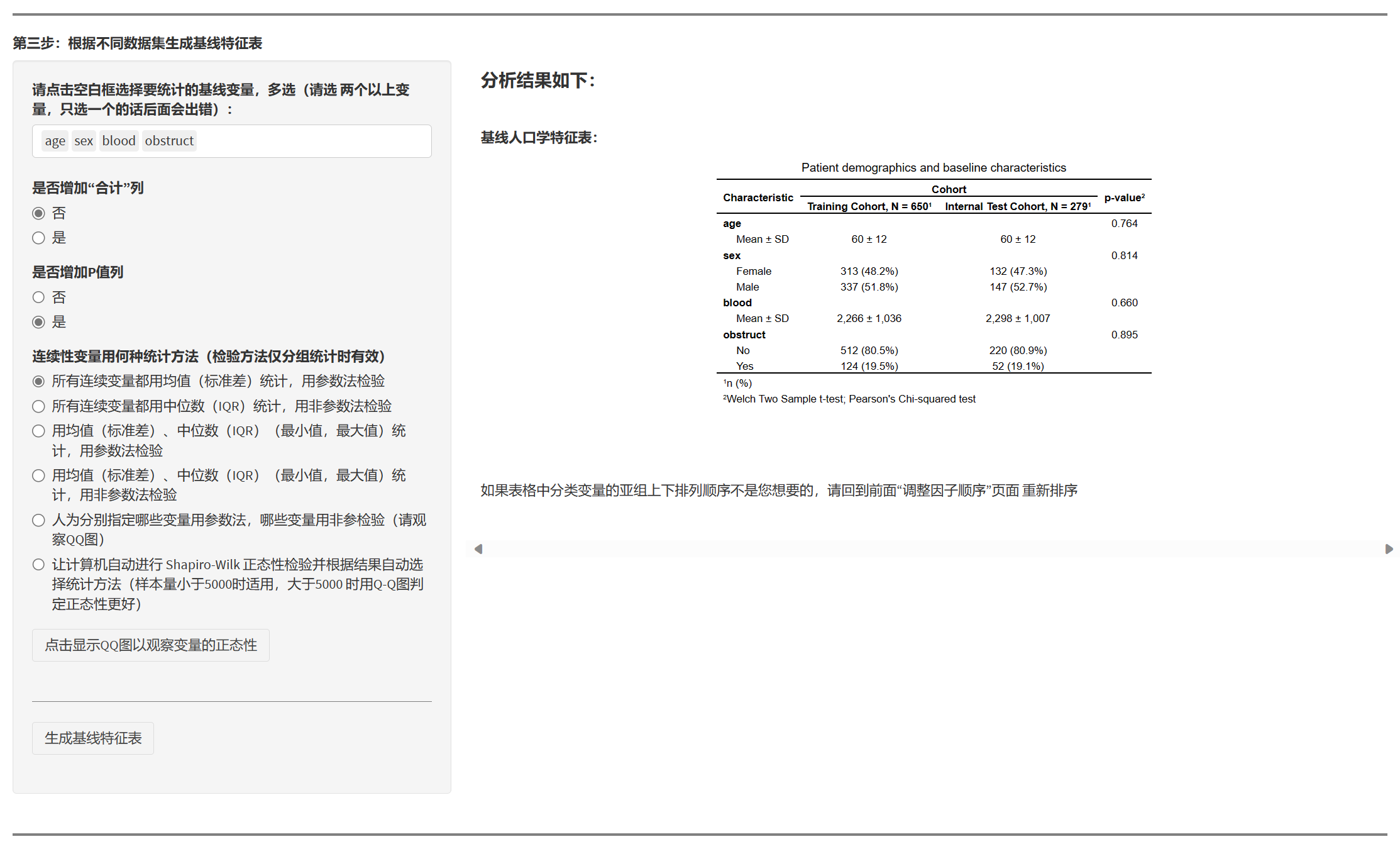
7.1.5 按数据集生成基线特征表(Table 1)
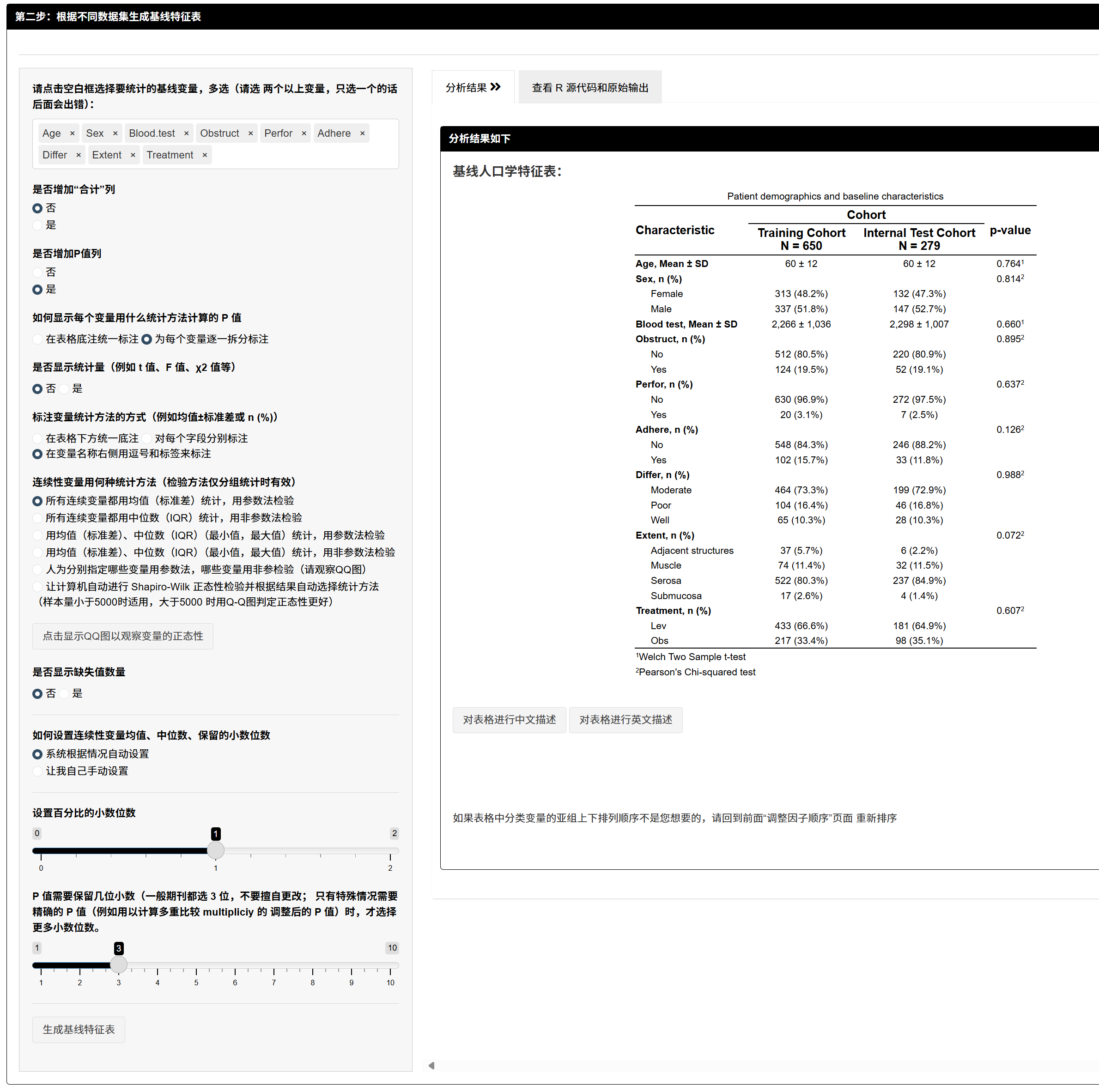
- 选择纳入变量、统计方式(均值±SD/中位数(IQR)等)、是否显示总体列与 P 值、位数设置、缺失显示方式等。
- 输出:按 Cohort(训练/内部验证/外部验证)的基线表,可直接用于论文(Results)。
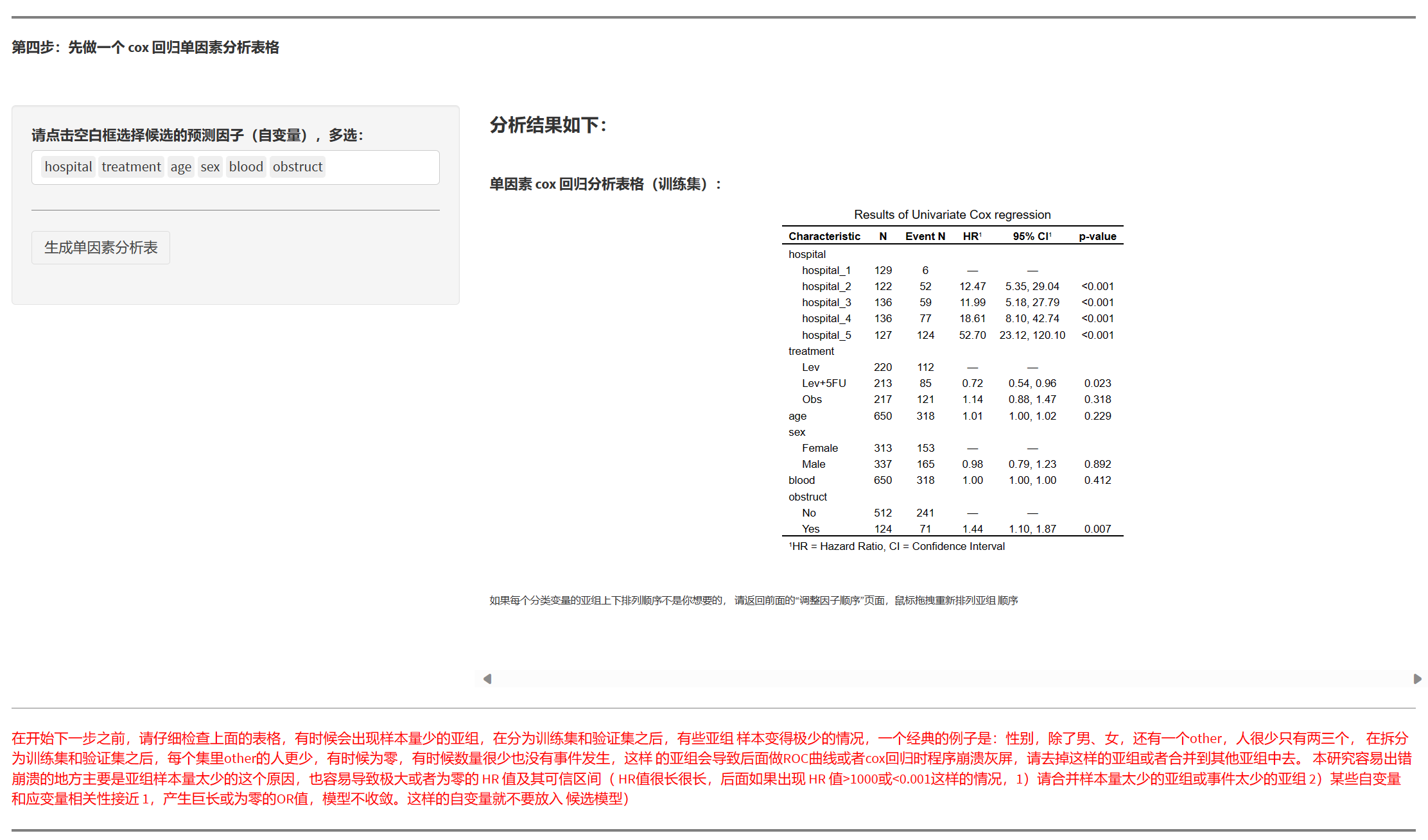
7.1.6 用结局分组做单因素对照表(必做,不一定写入论文)
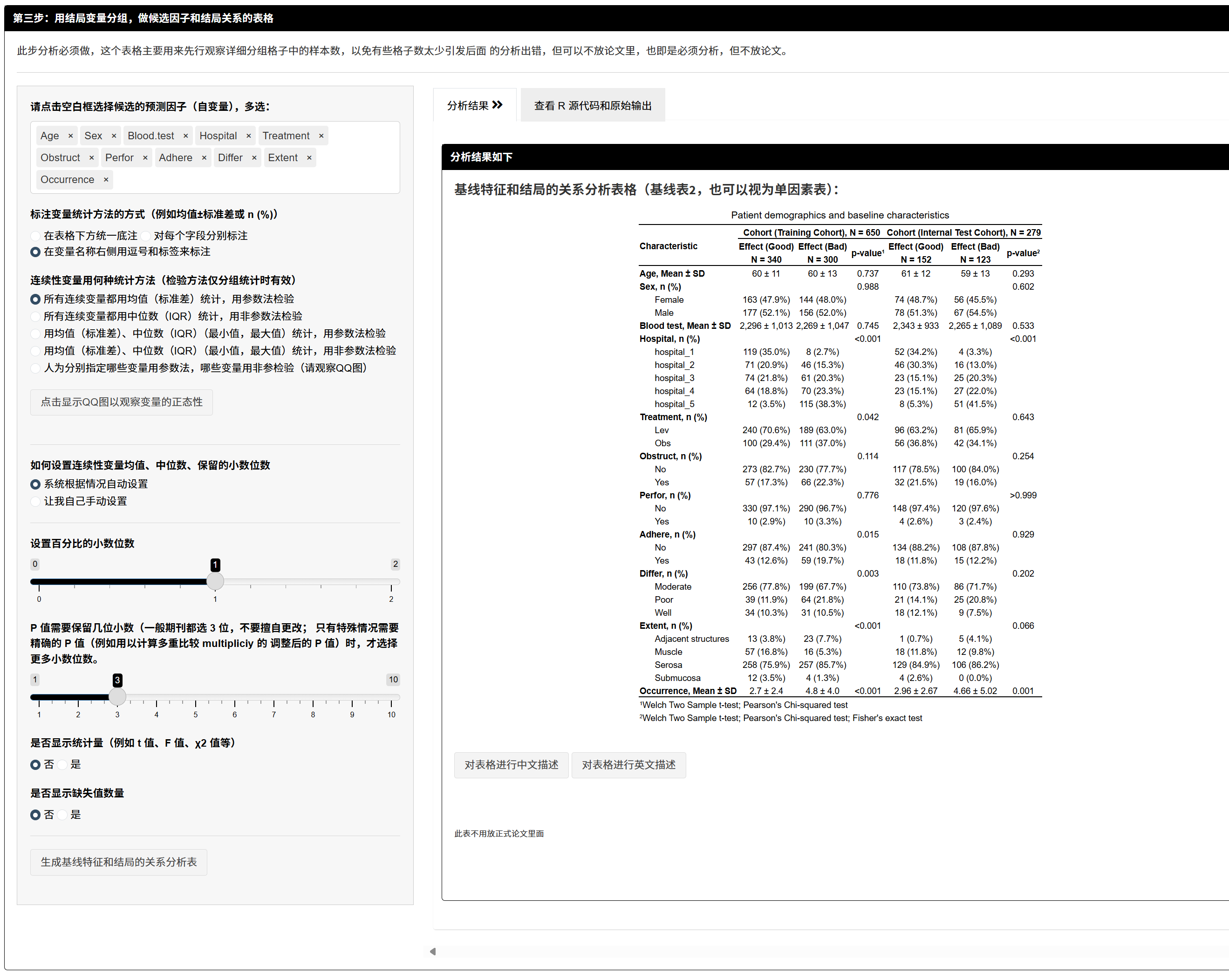
- 目的:先检查分组单元格内样本数是否偏少,避免后续 ROC 或 Logistic 报错;亦可初步感知变量与结局的关联。
- 输出:按结局分组的对照表;一般不放论文,但对质控极重要。
看到某些亚组样本/事件极少时,请回到“重编码”合并水平,或调整拆分比例。
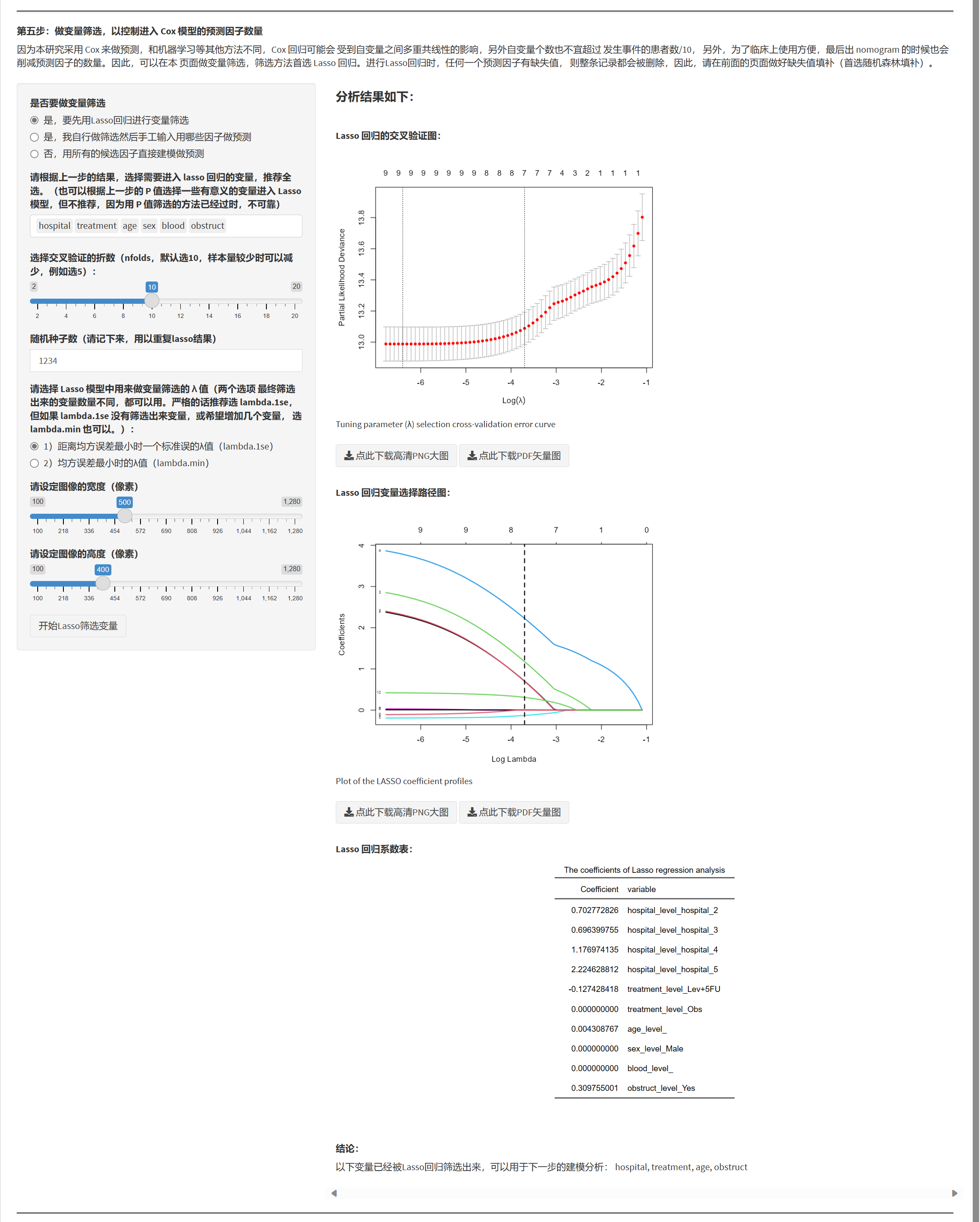
7.1.7 变量筛选(控制进入 Logistic 的预测因子数)
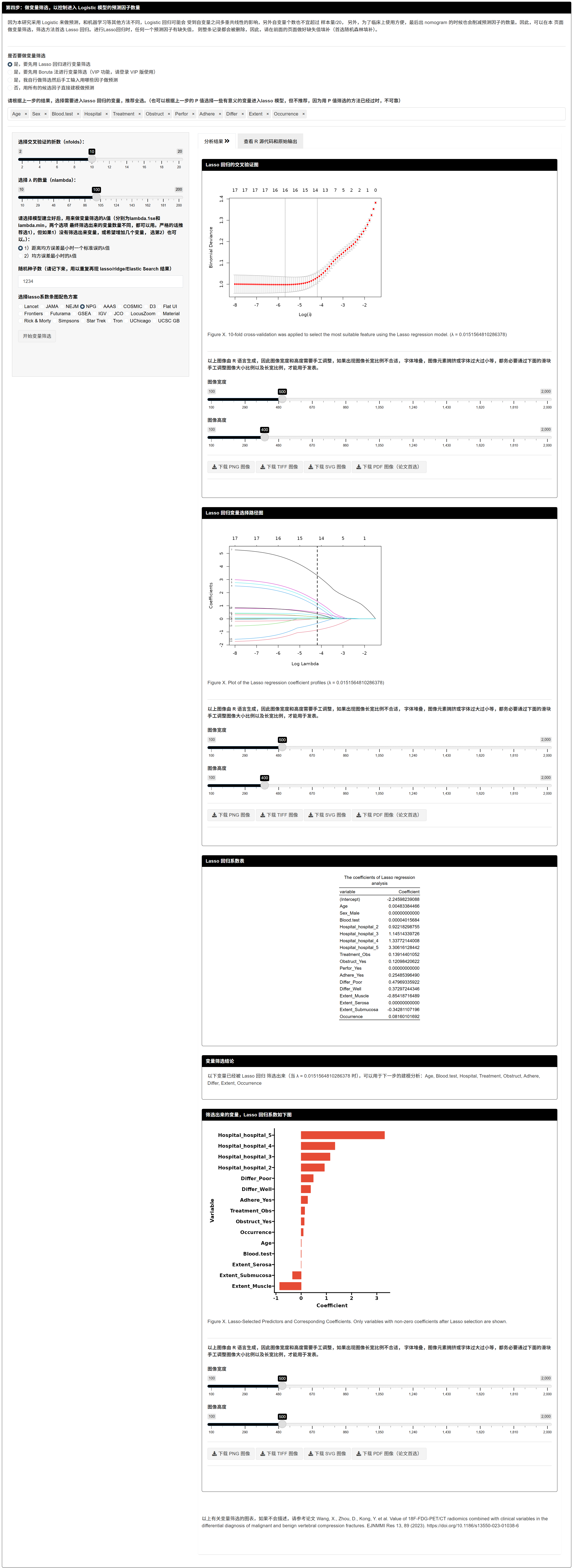
- 选择筛选方式:Lasso(默认)/ Boruta(VIP)/ 人工 / 不筛选。
- Lasso 提醒:若候选变量中有任一缺失,该行将被整体删除;请优先在前置模块做好缺失填补。
- 输出:交叉验证曲线、系数路径图、筛选出的变量与系数表、文字结论(可参考他文写法)。
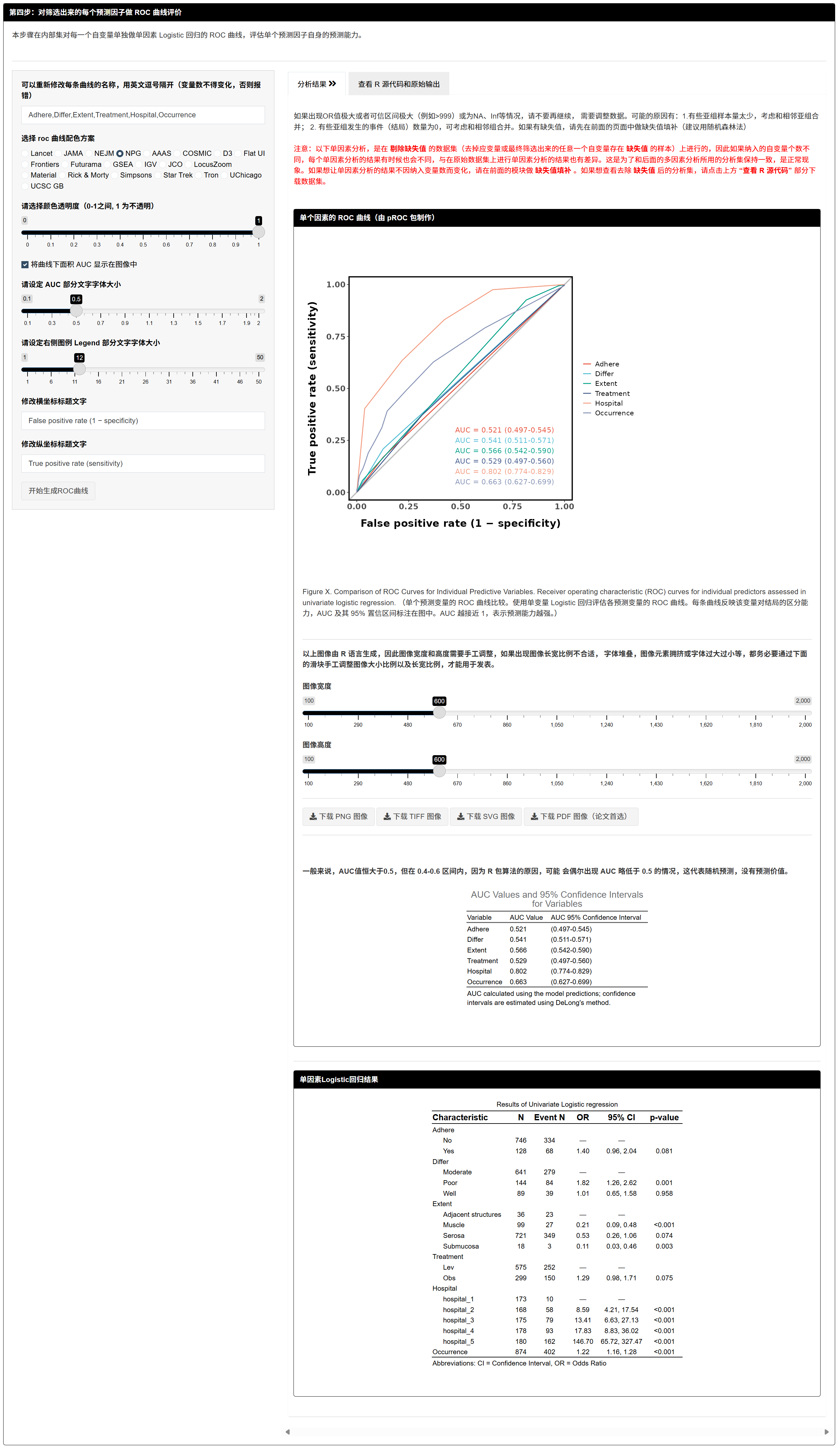
7.1.8 对每个入选预测因子做 ROC(单因素 Logistic 预测值)
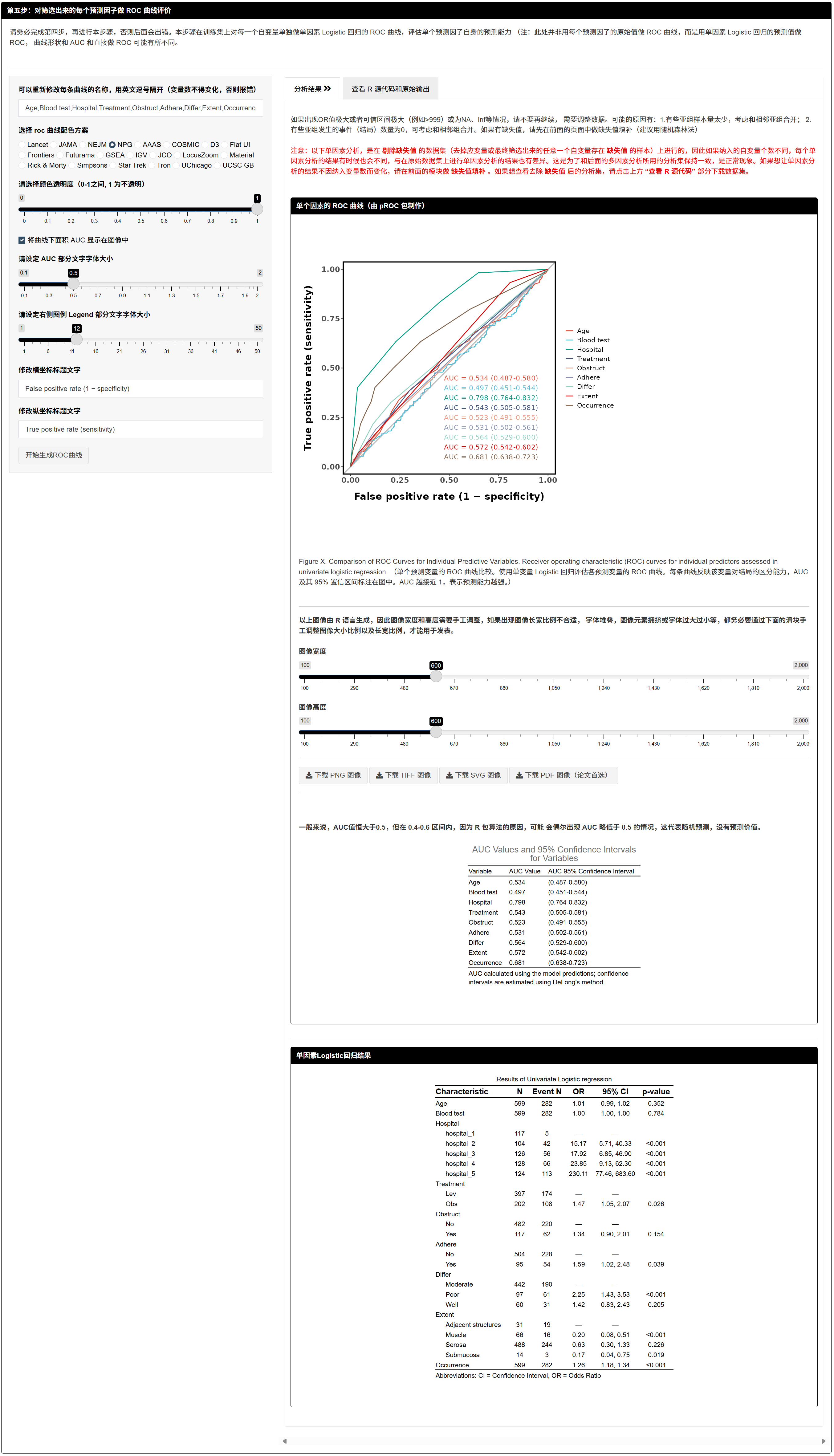
- 这是单因素 Logistic 的预测概率去画 ROC(非原始取值),用于衡量单一变量的判别力。
- 可自定义曲线名称、调色板、透明度、AUC 标注、坐标标题与字体大小。
- 输出:多曲线 ROC 图 + AUC 表。
如报错,多由某数据集中某亚组 0% 或 100% 事件引起;请合并稀有水平或调数据拆分。
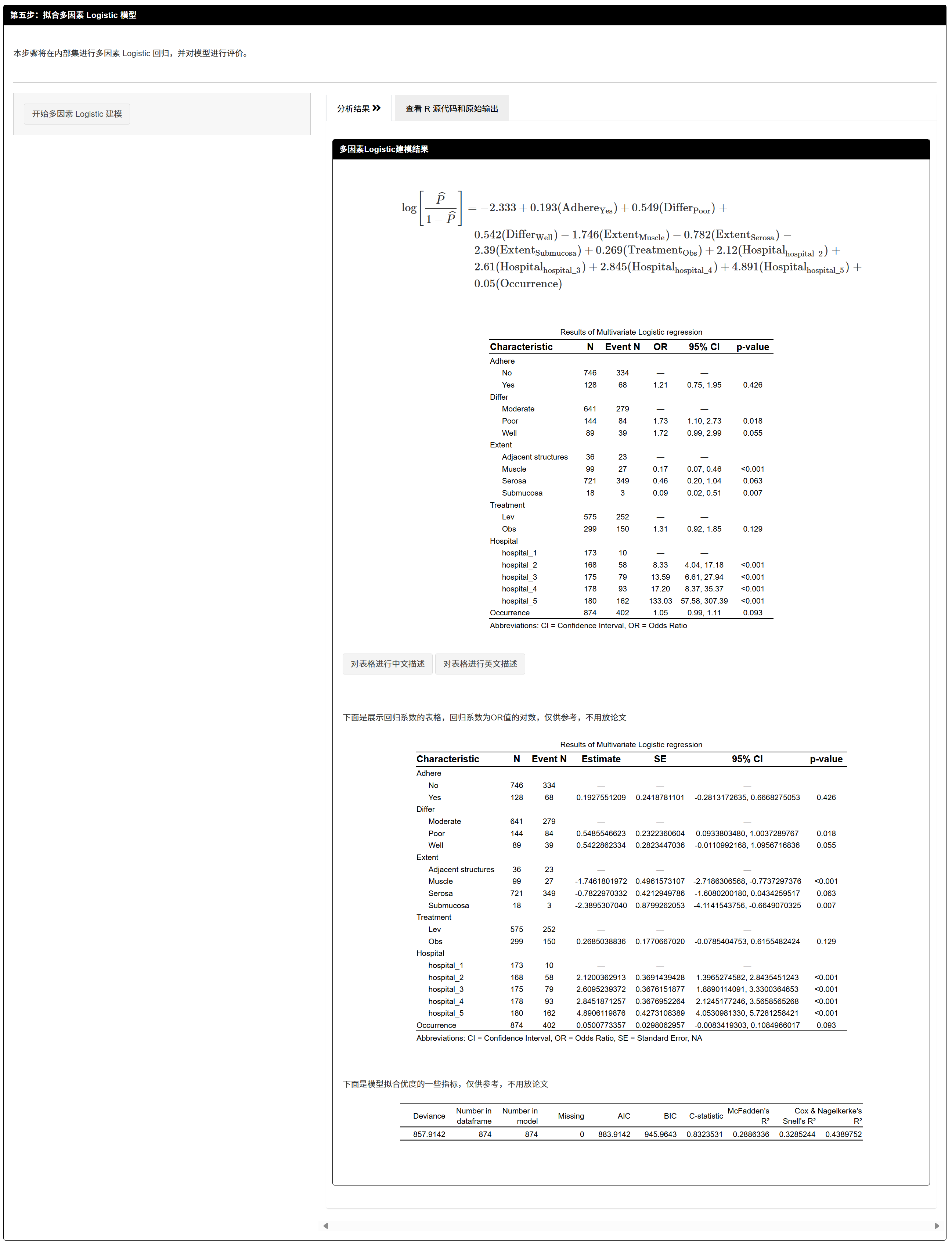
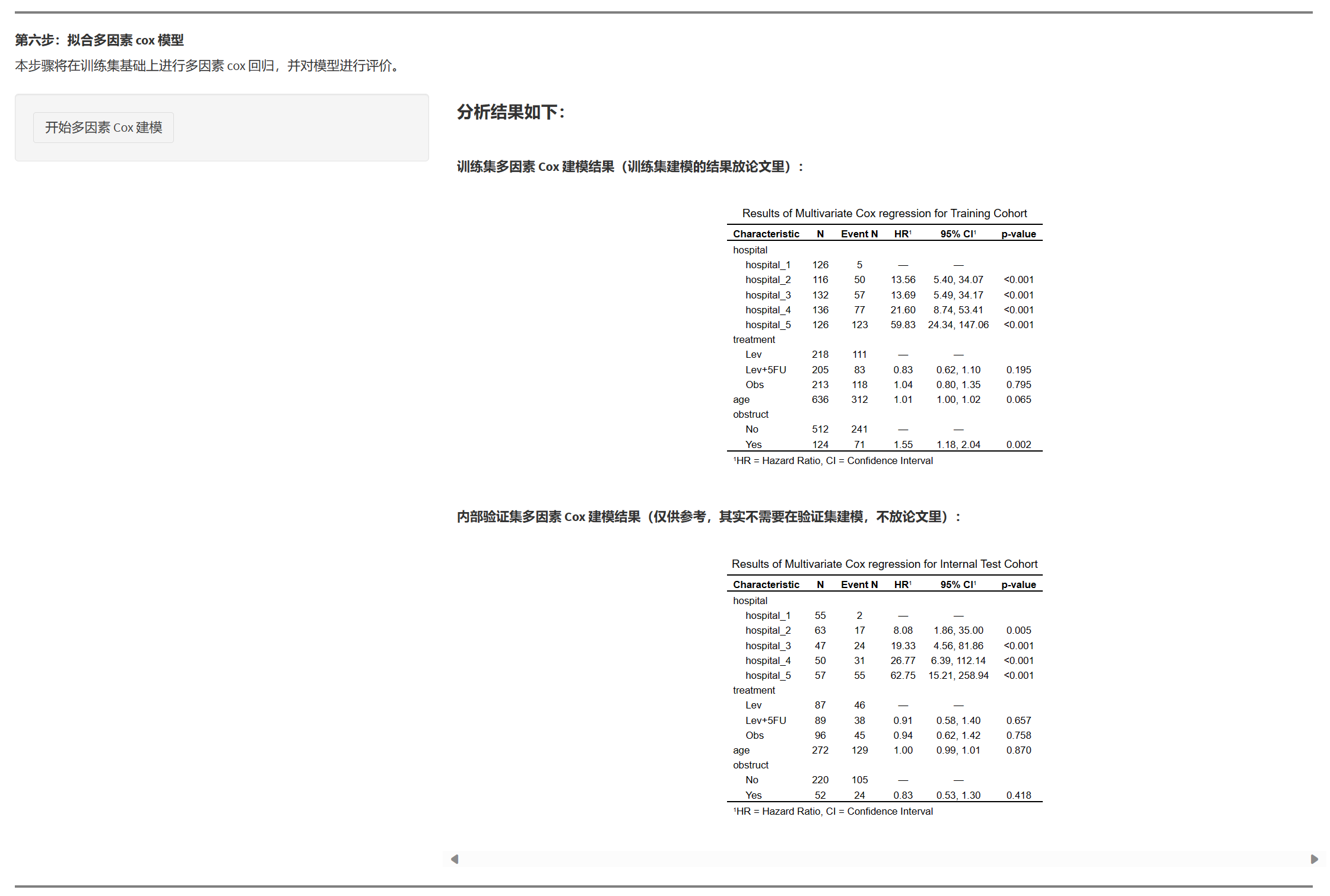
7.1.9 拟合多因素 Logistic 模型
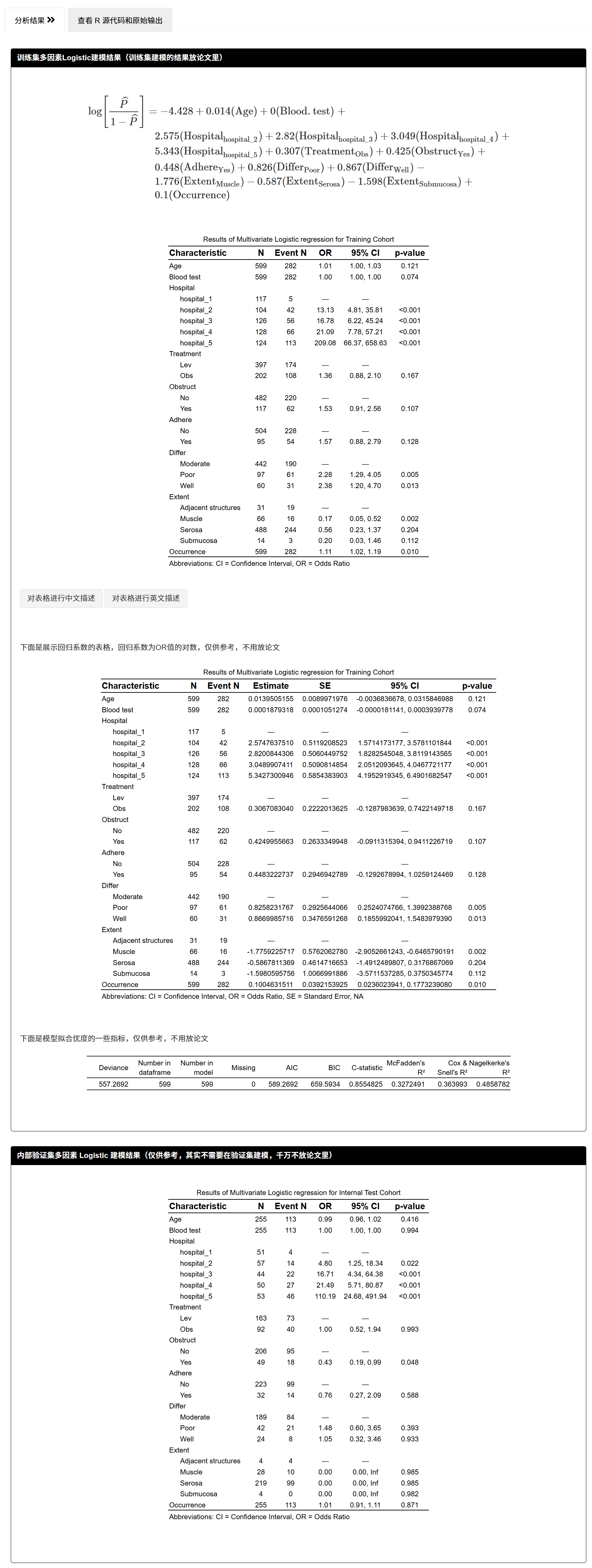
- 在训练集上拟合多变量模型;系统同时在验证/外部集上展示对应回归结果(不建议写入论文)。
- 输出:
- 训练集:模型公式(LaTeX 形式)、OR(95%CI、P)、样本与事件数;
- (可选)系数表(非 OR,用于内部参考)与拟合优度指标(内部参考)。
论文中只需展示训练集建模结果;验证/外部集的“重新拟合”不应报道。
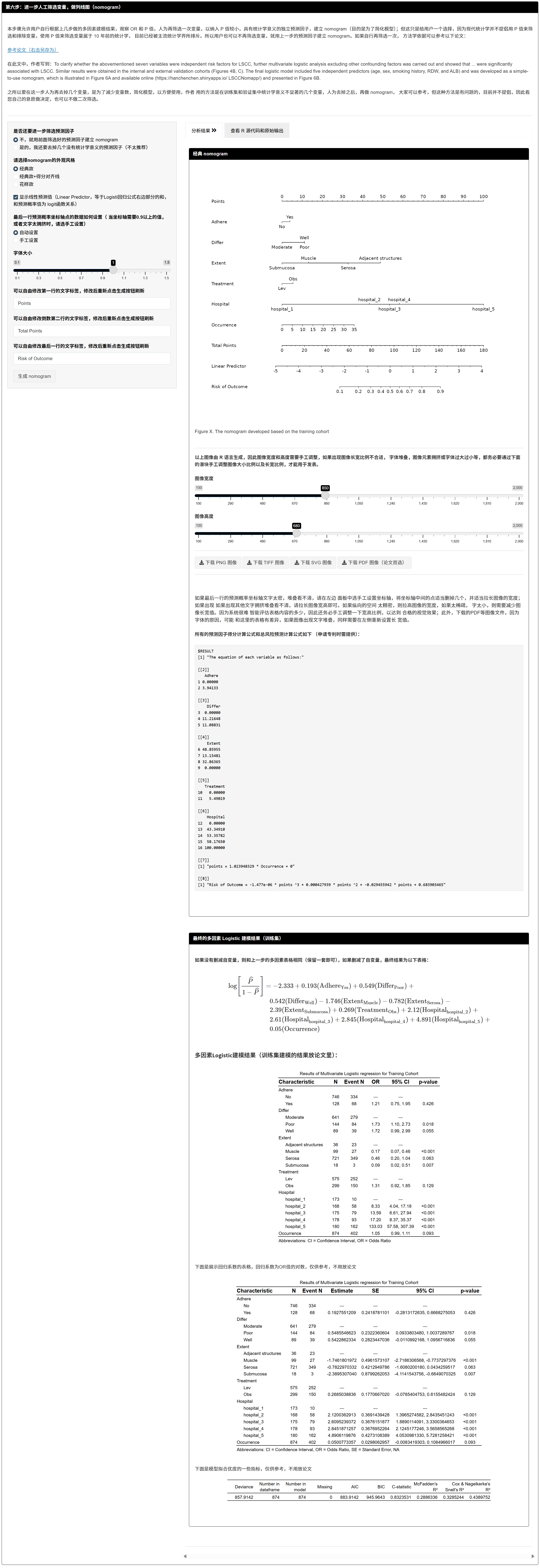
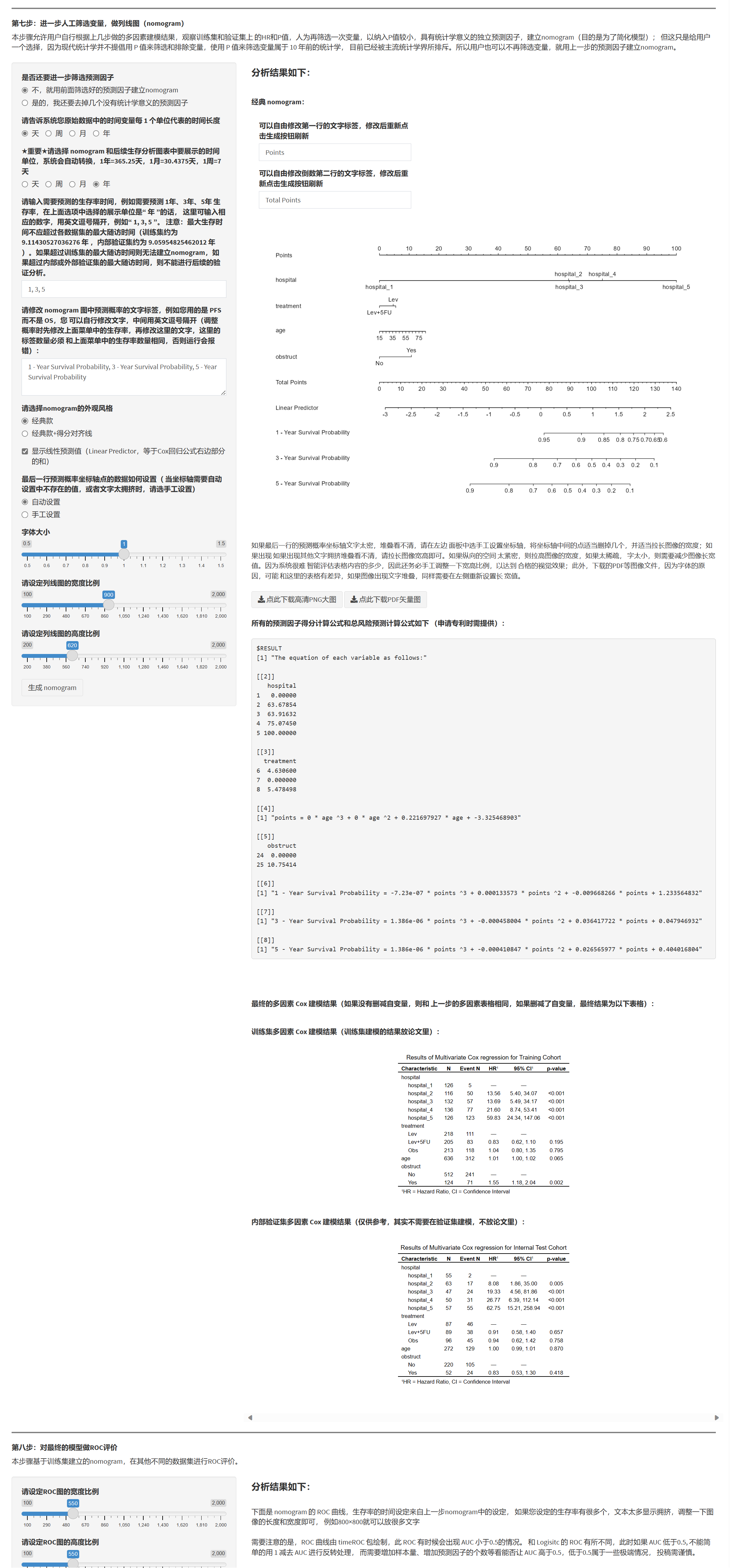
7.1.10 进一步人工精简并绘制 nomogram
- 可选择是否进一步删减变量以简化模型(非必须)。
- 可选风格(经典/带对齐线)、是否显示 Linear Predictor,以及概率刻度自动/手动设置与标签文字、字号。
- 输出:
- 列线图(建议按变量数适当调节图宽/高,避免拥挤),
- 得分与总风险计算公式(便于申请专利/落地部署)。
若“概率轴”提示上/下界超出模型范围,请改回自动查看范围后,再手动删去超界刻度。
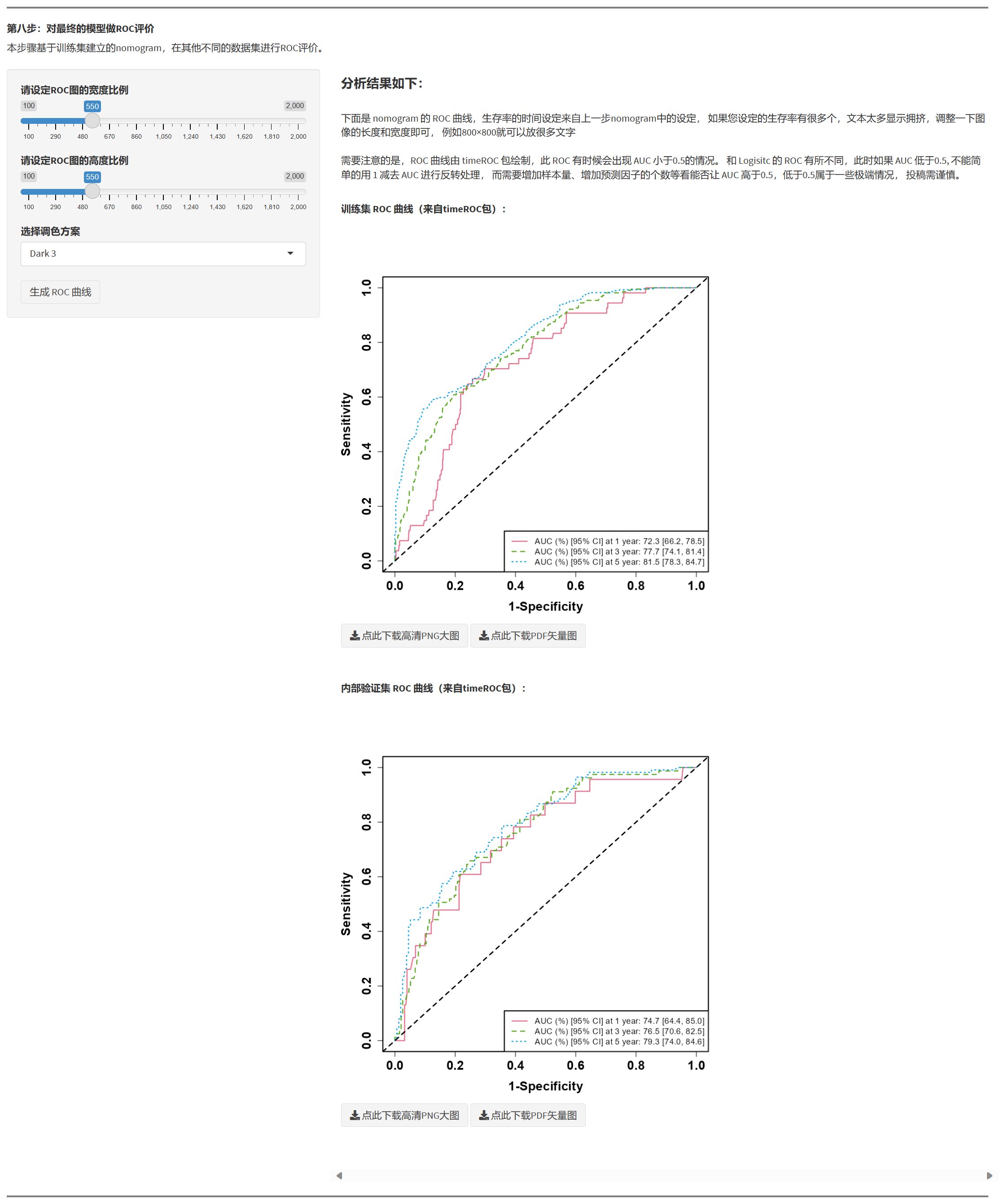
7.1.11 对最终模型做 ROC 评价(跨数据集)

- 使用训练集拟合的最终模型在训练/内部验证/外部验证上分别预测并计算 AUC。
- 可进行阈值敏感性分析:将预测概率转为分类(如 0.5 阈值或自定义区间)后计算灵敏度/特异度/精确率/召回率等。
Nomogram 输出的是概率,并非必须做分类指标;若做分类,请明确阈值与其临床意义。
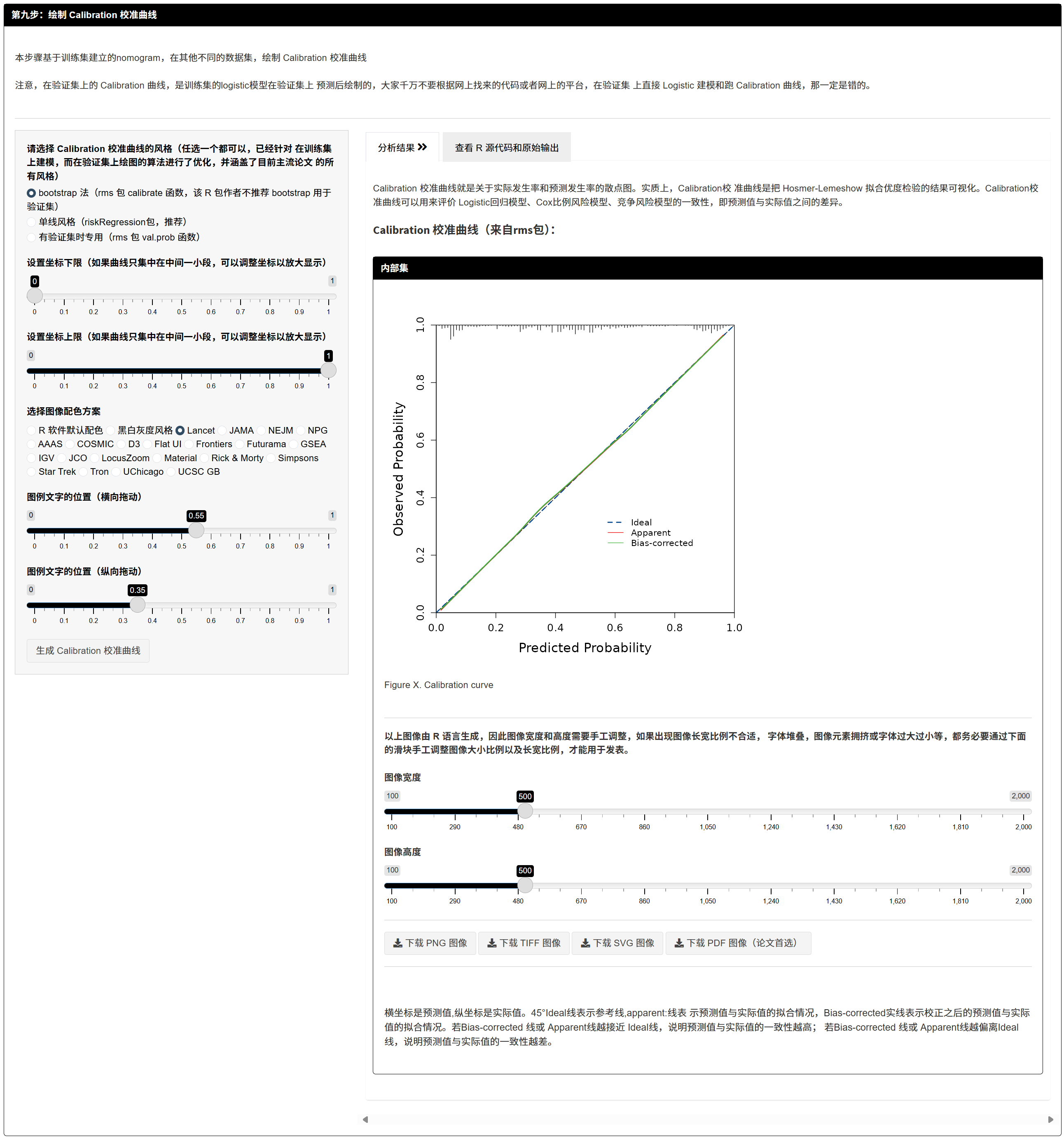
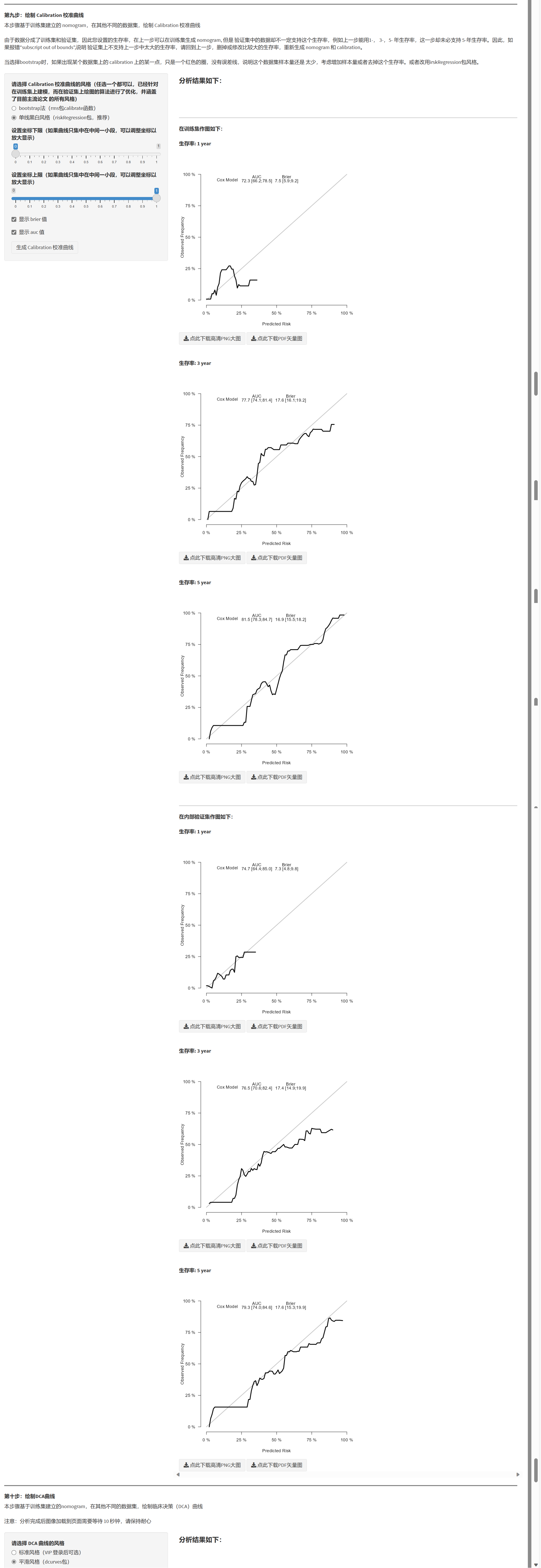
7.1.12 绘制 Calibration 校准曲线
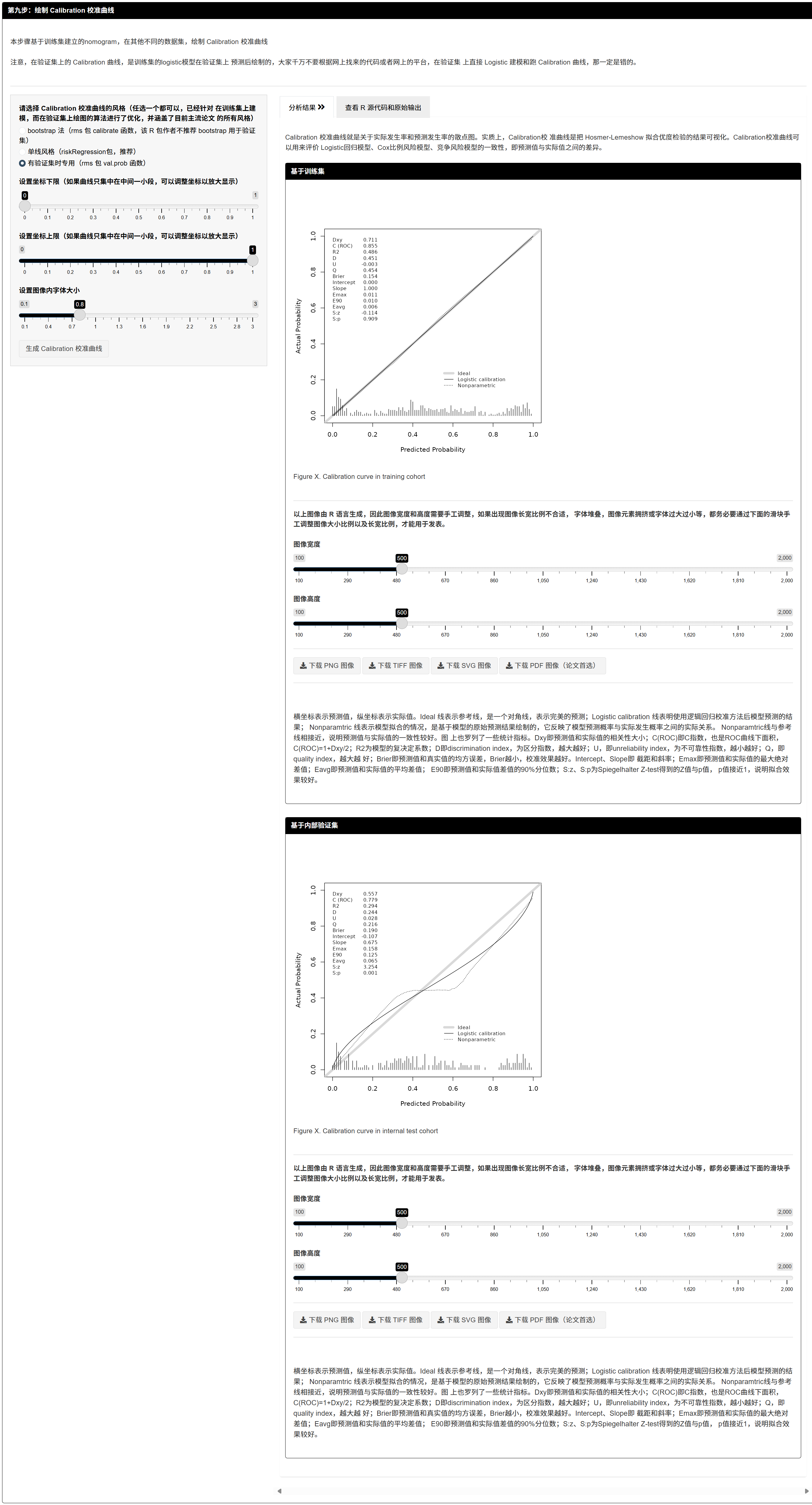
- 在不同数据集上绘制校准曲线(基于训练集模型的预测值),可选展示 Brier 分数、点大小与图例位置。
- 目的:评估预测概率与真实结局的一致性(越贴近 45° 线越好)。
7.1.14 下载与论文生成功能
- 下载 Word 报告:包含主要图表与结果,请用 Microsoft Word 打开(不建议 WPS)。
- 生成 SCI 论文初稿:填写题目/研究对象/变量含义等信息并勾选确认项,即可生成英文/(VIP)中文论文草稿;完成后建议拼图排版、补充文献与语言润色/改写以通过查重。
生成论文前,务必确保前述每一步均已成功产出图表与表格。
7.1.14.1 图表导出与代码复现
- 各步骤右侧提供 PNG/PDF 下载按钮与“查看 R 源代码与原始输出”。
- 第一步可下载训练/验证/外部数据子集;记住随机种子便于复现。
- 若想复用图表样式(分辨率/尺寸/配色),请使用模块内置的下载按钮而非截图。
7.1.14.2 常见错误与排查
- 建模或 ROC/Calibration/DCA 报错:多由亚组样本极少或事件为 0/100%导致;请合并水平或调整拆分比例。
- OR → ∞ 或 CI 巨大/为 NA/Inf:提示分离/近分离或强共线性;请合并稀有水平、删除高度相关变量或改用正则化。
- 单因素结果与多因素不一致:单因素在“去除任一纳入变量缺失后的分析集”上进行,为与多因素保持一致;若需稳定样本量,先做缺失填补。
- AUC 偶见 <0.5:算法数值细节所致,提示变量判别力接近随机;不建议纳入。
- 概率轴报错或字挤:回到自动模式查看范围后,手动去掉超界刻度,并调节图宽高。
7.1.14.3 论文写作要点(可参考)
- 方法:说明数据拆分、变量筛选(如 Lasso)、Logistic 建模、Nomogram 构建、评估指标(AUC/Calibration/DCA)与 CI 口径(Wald 或 Profile likelihood)。
- 结果:
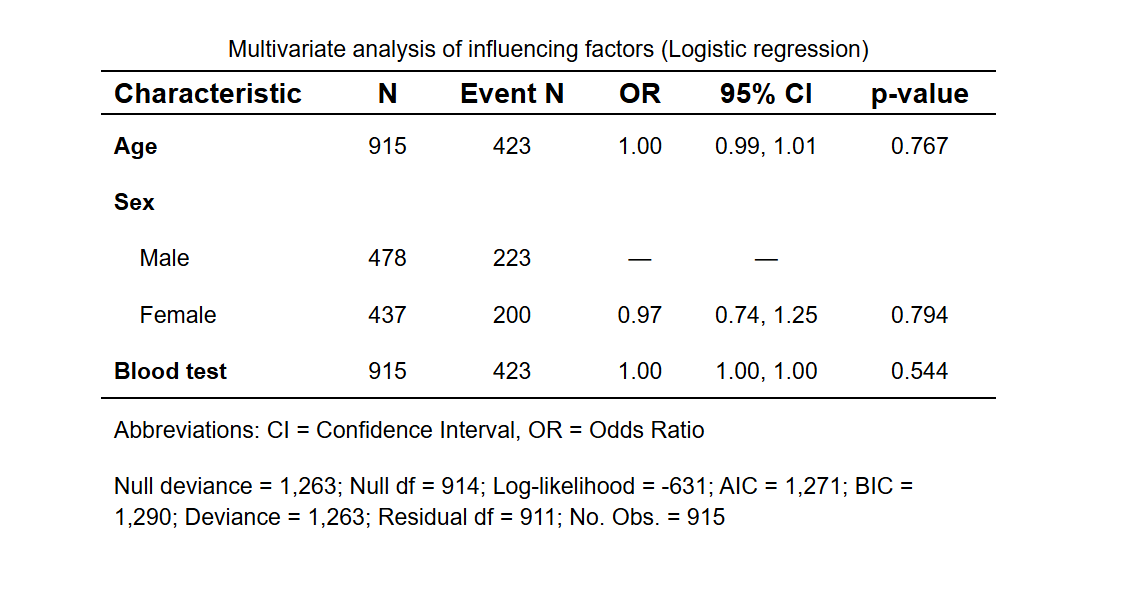
- 报告训练集多因素模型的 OR(95%CI、P),
- 报告模型在训练/验证/外部的 AUC(95%CI),
- 报告校准情况(图示与 Brier,如需),
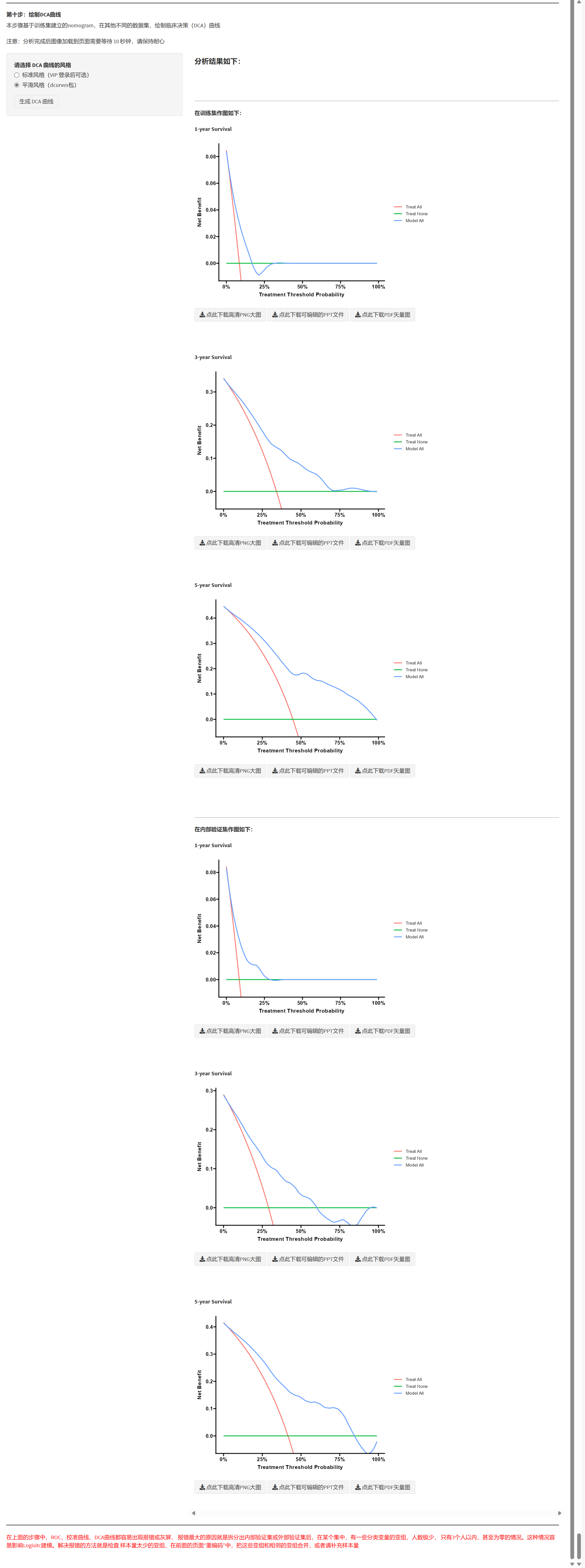
- 报告 DCA 在关键阈值范围内的相对净获益。
- 讨论:说明变量筛选与模型简化的动机(临床可用性)、外部验证的价值、潜在偏倚与局限,并提出推广与落地的路径。
文献引用请按目标期刊规范补充;若采用他人公开套路或范文,请在合适位置致谢与引用。
7.2 nomogram - Logistic - 二分类结局 (不拆分训练集和验证集,采用内部cv或bootstrap验证,列线图/ROC/校准曲线/DCA曲线,一键生成 SCI 论文)
本工具能够一键完成Logistic - nomogram(列线图)的临床预测研究分析,并自动生成一篇 30 多页的 SCI论文初稿。
分析的流程为:上传数据 -> 处理数据 -> 基线特征表 -> Lasso /boruta 变量 -> 评价每个入选因子的 ROC 曲线 -> Logistic 建模 -> 绘制普通 nomogram -> 整体评价ROC ->内部交叉cv验证或bootstrap验证 -> 绘制 calibration 校准曲线 -> 绘制 DCA 曲线 -> 制作一个互动 nomogram 并部署到个人网站 -> AI 撰写论文
整个过程视网络速度情况,从上传数据到论文生成,约5-8分钟完成,点击鼠标20次左右。

Nomogram,也叫作诺模图,是一种图形计算器,用于将数学公式或者复杂的统计模型转化为直观易用的图表。诺模图是一种强大的工具,可以用于可视化复杂模型的预测,通过滑动各变量标尺,就可以直观地得到预测结果,从而可以有效地为决策提供依据。在医学研究中,尤其是临床决策中,使用 nomogram 可以便捷地预测疾病的风险,评估治疗方案的效果等。
例如,在研究糖尿病发生的风险时,我们可以将年龄、性别、体重指数等危险因素作为预测变量,结合 Logistic 回归模型,制作出一个 nomogram。通过该 nomogram,我们可以快速直观地了解不同年龄、性别和体重指数下,糖尿病发生的风险大小。
本软件软件提供了丰富的功能支持,包括:
一键生成基线特征表
一键完成 Logistic 建模
绘制经典 nomogram:本软件 不仅可以实现 Logistic 回归模型的构建和评估,还可以直接生成 nomogram,将复杂的模型转化为易于理解的图形,帮助用户直观地理解和解释模型结果。
绘制网页动态 nomogram:这是一个相对更加现代化的方式,用户可以在网页上交互式地操作 nomogram,调整预测变量的值,并直接看到预测结果的变化。这种方式可以使nomogram 更加动态,有助于更深入地理解模型。
一键部署到用户的个人网站:本软件 还提供了一键部署的功能,用户可以将自己制作的动态 nomogram 部署到自己的个人网站上,提供给其他人使用。而且,用户可以将自己部署nomogram 的网址附在论文里,使得读者能够更方便地使用 nomogram,增强论文的可读性和实用性。
一键完成 ROC 曲线
一键完成内部交叉cv或bootstrap验证
一键完成 Calibration 校准曲线
一键完成 DCA 曲线
一键完成 SCI 论文的撰写
生成 R 源代码供审稿人存档
综上所述,无论是经典的 nomogram 还是动态的 web 版 nomogram,都可以在 本软件 中轻松实现。这无疑使得 本软件 成为了一款强大的统计分析和可视化工具。
7.2.1 数据准备
导入数据后,如果有缺失数据,缺失值在 20% 以下的变量,可以酌情考虑做缺失值填补,这里首选随机森林法进行填补。缺失值 20%-40% 的变量,需要慎重考虑;缺失值 40% 以上的变量,建议不放入模型。
有两种数据模式,有外部验证集和没有外部验证集。
没有外部验证集,只有内部集时,请按照以下方式准备数据:
这里包括二分类的结局 Stroke Status (“Yes”, “No”), 以及多个预测因子。
如果既有内部集,又有外部验证集,请把两个集合在一起准备数据:
这里把内部集和外部集纵向合并起来,并增加一列在末尾,标示出那个是内部集,哪个是外部验证集。
后面分析的时候,系统会按要求将内部集拆分成训练集和内部验证集。然后以训练集、内部验证集、外部验证集三个队列来分别做基线人口学特征表。
7.2.2 进入模块
接下来我们进入模块,点击软件顶部菜单的“预测研究”,然后点击“Logistic - 二分类结局 nomogram (不拆分训练集和验证集,采用内部cv或bootstrap验证,列线图/ROC/校准曲线/DCA曲线,一键生成 SCI 论文)” 进入模块。
下面是使用方法:
步骤1:选择您的数据并加载到本软件。
上传数据后,如果有缺失数据,缺失值在20%以下的变量,可以酌情考虑做缺失值填补,这里首选随机森林法进行填补。缺失值20%-40%的变量,需要慎重考虑;缺失值40%以上的变量,建议不放入模型。
有两种数据模式,有外部验证集和没有外部验证集。
没有外部验证集,只有内部集时,请按照以下方式准备数据:
这里包括二分类的结局 Stroke Status (“Yes”, “No”), 以及多个预测因子。
如果既有内部集,又有外部验证集,请把两个集合在一起准备数据:
这里把内部集和外部集纵向合并起来,并增加一列在末尾,标示出那个是内部集,哪个是外部验证集。
后面分析的时候,系统会按要求将内部集拆分成训练集和内部验证集。然后以训练集、内部验证集、外部验证集三个队列来分别做基线人口学特征表。
步骤2:生成基线表。
步骤3:lasso回归筛选变量

步骤4:对每个入选变量做单独 ROC 评价
步骤5:多因素建模
步骤6:绘制 nomogram
步骤7:对最终模型做 ROC 评价

步骤8:内部cv或bootstrap验证

步骤8:绘制calibration校准曲线
步骤9:绘制DCA曲线

步骤10:生成动态列线图并部署到个人网站

步骤10:下载word报告
步骤11:生成一篇 SCI 论文
7.3 nomogram - Cox - 生存结局(拆分训练集和验证集,列线图/ROC/校准曲线/DCA曲线,一键生成 SCI 论文)
本工具能够一键完成 Cox - nomogram(列线图)的临床预测研究分析,并自动生成一篇 3000 多字的 SCI论文初稿。包括标题、背景、方法、结果、参考文献。除了讨论部分需要用户自行撰写外,其他部分均已经完成初稿。
分析的流程为:上传数据 -> 处理数据 -> 拆分训练集和验证集 -> 基线特征表 -> Lasso 回归筛选变量 -> Cox 建模 -> 绘制普通 nomogram -> 在训练集和验证集整体评价ROC -> 绘制 calibration 校准曲线 -> 绘制 DCA 曲线 -> 制作一个互动 nomogram 并部署到个人网站 -> AI 撰写论文
整个过程视网络速度情况,从上传数据到论文生成,约5-8分钟完成,点击鼠标20次左右。

Nomogram,也叫作诺模图,是一种图形计算器,用于将数学公式或者复杂的统计模型转化为直观易用的图表。诺模图是一种强大的工具,可以用于可视化复杂模型的预测,通过滑动各变量标尺,就可以直观地得到预测结果,从而可以有效地为决策提供依据。在医学研究中,尤其是临床决策中,使用 nomogram 可以便捷地预测疾病的风险,评估治疗方案的效果等。
例如,在研究某种肿瘤的总生存预测时,我们可以将年龄、性别、肿瘤大小、肿瘤分期等因素作为预测变量,结合 Cox 回归模型,制作出一个 nomogram。通过该 nomogram,我们可以快速直观地了解在不同年龄、性别、肿瘤大小和肿瘤分期情况下,患者的总生存预期。
对于如何在 本软件 中实现绘制 Cox 回归的 nomogram,本软件 统计软件提供了丰富的功能支持,包括:
1) 一键拆分训练集和验证集
2)一键生成基线特征表
3)一键完成 Cox 建模
4)绘制经典 nomogram:本软件 不仅可以实现 Cox 回归模型的构建和评估,还可以直接生成 nomogram,将复杂的模型转化为易于理解的图形,帮助用户直观地理解和解释模型结果。
5)绘制网页动态 nomogram:这是一个相对更加现代化的方式,用户可以在网页上交互式地操作 nomogram,调整预测变量的值,并直接看到预测结果的变化。这种方式可以使nomogram 更加动态,有助于更深入地理解模型。
6)一键部署到用户的个人网站:本软件 还提供了一键部署的功能,用户可以将自己制作的动态 nomogram 部署到自己的个人网站上,提供给其他人使用。而且,用户可以将自己部署nomogram 的网址附在论文里,使得读者能够更方便地使用 nomogram,增强论文的可读性和实用性。
7)一键完成 ROC 曲线
8)一键完成 Calibration 校准曲线
9)一键完成 DCA 曲线
10)一键完成 SCI 论文的撰写
综上所述,无论是经典的 nomogram 还是动态的 web 版 nomogram,都可以在 本软件 中轻松实现。这无疑使得 本软件 成为了一款强大的统计分析和可视化工具。
7.3.1 进入模块
接下来我们进入模块,点击软件顶部菜单的“预测研究”,然后点击“Cox - 生存 nomogram (拆分训练集和验证集,列线图/ROC/校准曲线/DCA曲线,一键生成 SCI 论文)” 进入模块。
7.3.2 选择您的数据并加载到本软件
上传数据后,如果有缺失数据,缺失值在20%以下的变量,可以酌情考虑做缺失值填补,这里首选随机森林法进行填补。缺失值20%-40%的变量,需要慎重考虑;缺失值40%以上的变量,建议不放入模型。
有两种数据模式,有外部验证集和没有外部验证集。
没有外部验证集,只有内部集时,请按照以下方式准备数据:
这里包括生存资料的结局 time 和status, 以及多个预测因子。
如果既有内部集,又有外部验证集,请把两个集合在一起准备数据:
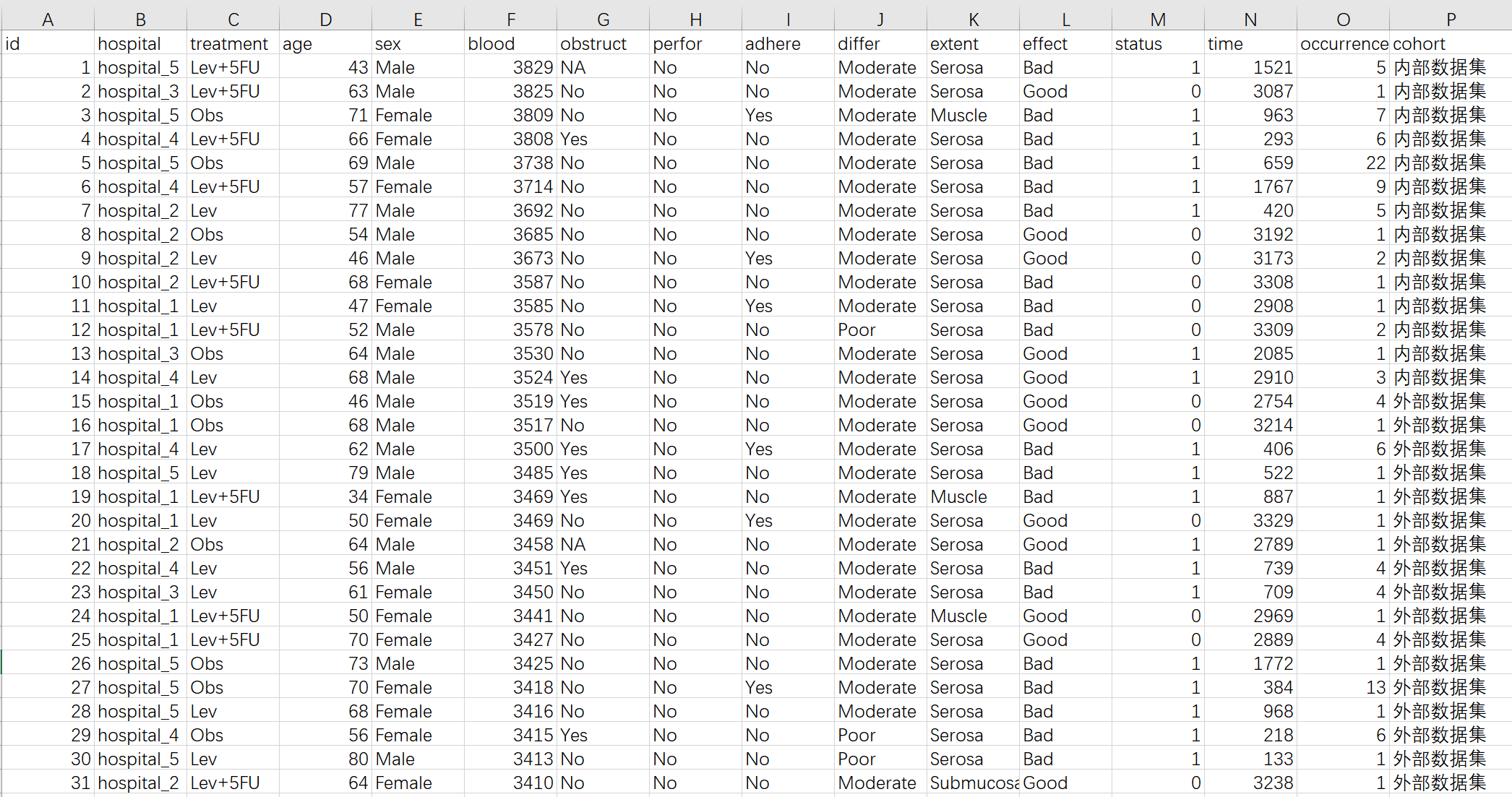
这里把内部集和外部集纵向合并起来,并增加一列在末尾,标示出那个是内部集,哪个是外部验证集。
后面分析的时候,系统会按要求将内部集拆分成训练集和内部验证集。然后以训练集、内部验证集、外部验证集三个队列来分别做基线人口学特征表。
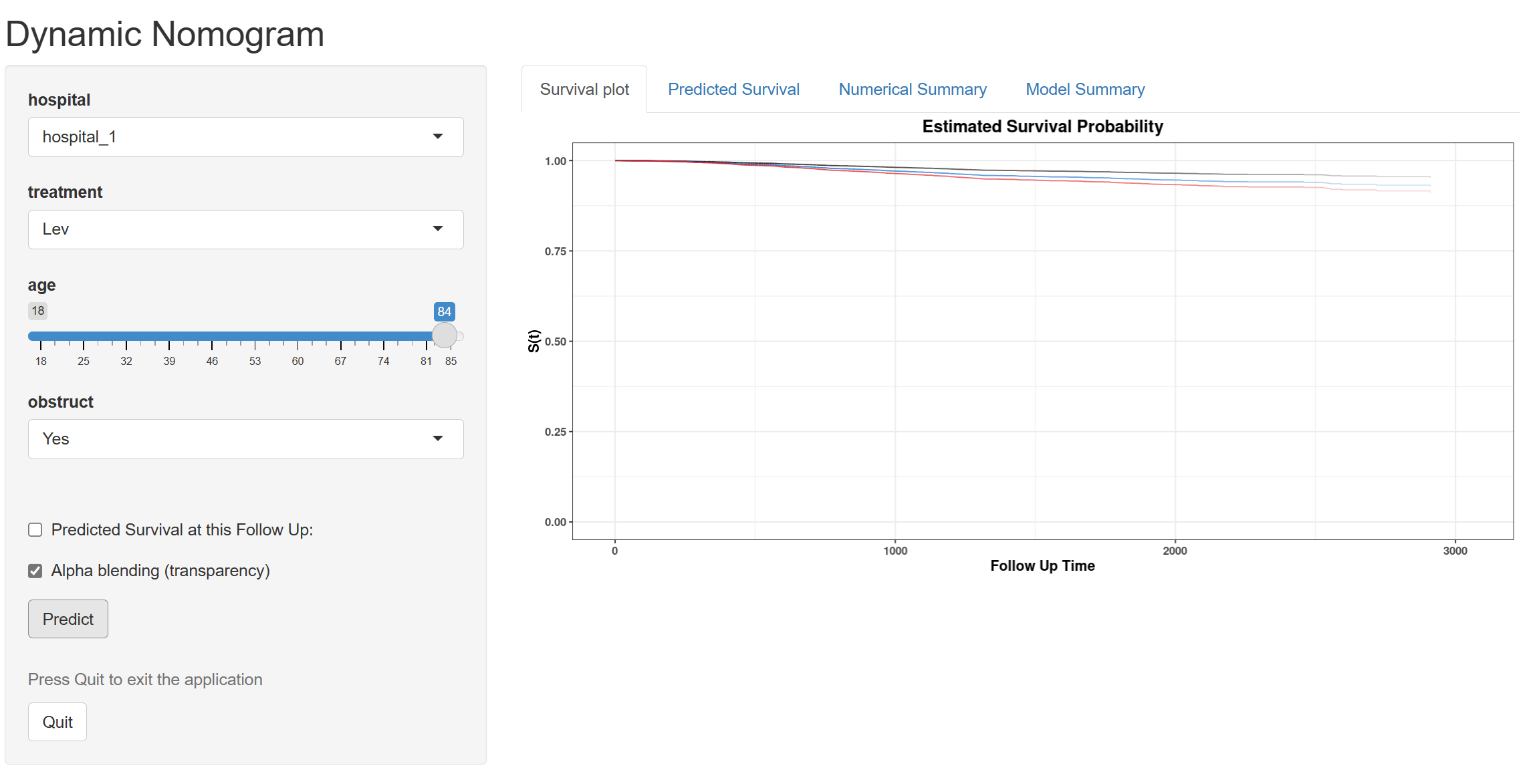
7.4 生成动态 nomogram 并自动搭建一个互动网站(Linear/Logistic/Cox/Poisson回归)
使用方法:将本软件其他预测模型的模块生成的训练集(注意必须是训练集)和筛选出来的预测因子,导入到本模块,然后进行回归建模,再传到网站生成动态 Nomogram 即可。
支持 线性 / Logistic / Cox / Poisson 的 Nomogram
——————————————————————————————————————————————
动态列线图的意思就是,制作一个网页,将您的预测模型放在网页后台,当读者阅读您的论文之后, 就访问您的网站,输入性别年龄临床特征等因子,系统就会实时告诉读者,该患者的风险概率有多大。 目前的SCI论文,通常都需要在文中附上这样一个网页地址,例如以下这篇论文:
以下是一篇5分左右的例文:

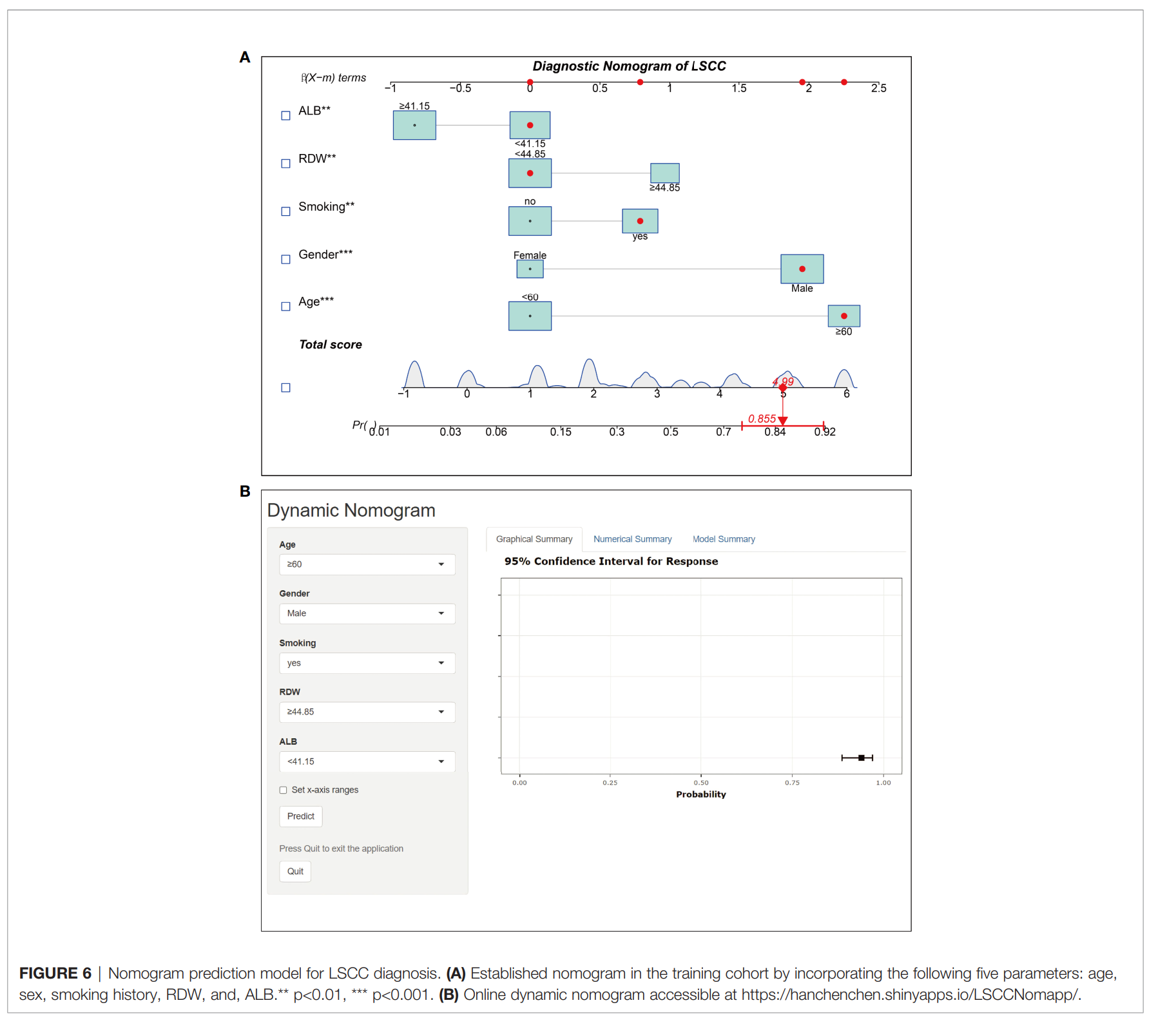
7.4.1 背景与原理
- 动态 nomogram 是什么?
基于回归模型(Linear / Logistic / Cox / Poisson),将模型系数封装为互动网页:用户在网页上输入协变量(可用滑条或数字),即可实时查看预测值(如概率、风险比、生存率、计数率等)及不确定性区间。 - 为什么常用于 SCI 论文?
期刊与读者希望在真实情境下复现模型的个体化预测;在线计算器可直接服务临床决策与外部读者。 - 实现方式(软件栈)
MSTATA 在后端用 R 软件 DynNom 包将拟合好的模型对象 部署到 shinyapps.io,自动得到一个可公开访问的网址。
7.4.2 适用模型与输出解读(速览)
- Logistic 回归(二分类结局):输出发生概率(及 95% CI),常见效应量为 OR。
- Linear 回归(连续结局):输出点预测值及区间估计。
- Cox 回归(生存结局):输出生存概率 / 累积风险等(由 DynNom 自动适配)。
- Poisson 回归(计数结局):输出事件率/期望计数(及 95% CI),效应量为 IRR。
- Offset Poisson(分子/分母,如率、比、百分比):以
log(分母)为 offset,输出比率/率的预测与 IRR。
7.4.3 进入模块
接下来我们进入模块,点击软件顶部菜单的“预测研究”,然后点击“生成动态 nomogram 并自动搭建一个互动网站(Linear/Logistic/Cox/Poisson回归)” 进入模块。
7.4.5 选择回归族(family)
在 “选择结局变量的类型” 中四选一:
- Logistic(二分类)、Linear(连续)、Cox(生存)、Poisson(计数),或 Offset(分子/分母的 Poisson)。
7.4.6 指定结局/时间/状态
根据你选择的家族,界面会自动显示相应控件:
- Logistic
- “请选择结局变量/应变量(二分类)”
- “请下拉选择结局变量的哪个水平表示发生事件”(务必选对事件水平,选中的水平会被编码为 1)
- “请选择结局变量/应变量(二分类)”
- Linear
- “请选择结局变量/应变量(正态连续变量)”
- Cox
- “请选择代表时间的变量”(如 OS、DFS 的随访时长)
- “请选择代表患者最终状态的变量(只能两类)”
- “请下拉选择结局变量的哪个水平表示发生事件(1=事件,0=删失)”
- “请选择代表时间的变量”(如 OS、DFS 的随访时长)
- Poisson
- “请选择结局变量/应变量(计数资料)”(必须为非负整数)
- Offset Poisson
- “请选择结局变量/应变量的分子(非负整数)”
- “请选择结局变量/应变量的分母(非负整数)”(将作为
log(分母)的 offset)
- “请选择结局变量/应变量的分子(非负整数)”
小贴士
- Cox 的 time 必须为非负数;status 仅两类,且需要指定哪个为“事件”。
- Poisson/Offset 的结局与分母列应为非负整数;分母不得为 0。
7.4.7 选择自变量(协变量)
在 “请点击空白框选择要探索的候选影响因素/自变量” 中多选。
- 支持拖拽调整顺序。
- 分类变量必须在定义字段里设为 factor 并设置合理水平。稀有水平应适度合并。
7.4.8 1.4 置信区间算法(可选)
在 “用什么方法计算 95% CI” 中二选一:
- Wald CI(与 SPSS/老版本传统软件一致,稳妥、速度快)
- Profile likelihood CI(更精确,但与基于 Wald 的 p 值可能出现差异;多重填补 MI 时请勿选)

7.4.9 生成结果表
点击 “生成/更新影响因素分析表”。右侧将输出回归表:
- Logistic/Cox/Poisson 显示 OR / HR / IRR 及 95% CI、p 值,并附 N 与事件数。
- Linear 显示 回归系数(Beta) 及 95% CI、p 值,并附 N。
若出现完美分离(OR/HR/IRR 极大/为 ∞)、或标准误巨大:请合并稀有水平、减少共线、检查缺失。
7.4.11 准备部署凭据(Token)
打开 https://www.shinyapps.io 注册并登录(代理上网可能更稳定)。
左侧 Account → Tokens → Add Token,点击 Show 与 Show secret,复制完整命令
rsconnect::setAccountInfo(name='账户名', token='...', secret='...')。注意:
secret='...' 里面的内容可能处于隐藏状态,先要点击解除隐藏后再复制
将该命令原样粘贴到页面的 “请输入…token” 文本框中。
> 仅用于部署,不会上传你的原始数据。请自行妥善保管凭据。
临时体验:可用页面自带的示例 token 测试,部署到
https://mstata.shinyapps.io/dynnomapp(多人同时使用可能冲突,仅供试用)。
7.4.12 设置网站标题与展示样式
- “给您的 nomogram 网站 APP 起一个标题”:仅限字母、数字、空格、下划线。
- “模型概览显示方式(m.summary)”:
- formatted:更美观的摘要
- raw:R 原始文本
- formatted:更美观的摘要
- “连续自变量输入方式(covariate)”:
- slider(滑动条,直观)
- numeric(数字输入,精细)
- slider(滑动条,直观)
7.4.13 点击部署
- 按 “点击开始部署”。系统将:
- 以你在第 1 步拟合好的模型生成 App;
- 执行你粘贴的
rsconnect::setAccountInfo();
- 部署到shinyapps.io。
- 以你在第 1 步拟合好的模型生成 App;
- 首次部署通常需 3–5 分钟。部署完成后:
- 若使用本软件测试 token:访问
https://mstata.shinyapps.io/dynnomapp测试;
- 若使用你的账号:访问
https://你的账户名.shinyapps.io/dynnomapp。
- 若使用本软件测试 token:访问
论文中引用:建议在方法或结果部分提供上述网址,并在补充材料放一张网页截图(示例输入与输出)。
7.4.14 网页端的使用与解读(给读者/审稿人)
- 在网页上逐一输入(或拖动滑条设置)协变量;
- 点击 Predict / Update(页面按钮由 DynNom 自动生成);
- 页面根据模型类型自动显示:
- Logistic:个体化发生概率(及 95% CI)、可能附 ROC 相关指标的参考说明;
- Linear:预测的连续值(点估计与区间);
- Cox:给定时间点的生存概率 / 累积风险等交互输出;
- Poisson/Offset:期望计数/比率/率与区间;
- Logistic:个体化发生概率(及 95% CI)、可能附 ROC 相关指标的参考说明;
- 页面还会提供模型概要(
m.summary),便于快速审阅。
7.4.15 常见问题与排查
- 部署失败(token 无效/权限不足)
- 重新在 shinyapps.io 生成 Token & Secret;确保完整粘贴
rsconnect::setAccountInfo(...)。
- 企业/校园网可能拦截外网端口,请在稳定网络下重试。
- 重新在 shinyapps.io 生成 Token & Secret;确保完整粘贴
- 网页能打开但点击预测后灰屏/报错
- 多因模型数据问题:如极端共线、完美分离、分母含 0、Cox 的 time/status 异常、Poisson 非整数。
- 回到“回归建模”修正后重新部署(会覆盖旧版本)。
- 多因模型数据问题:如极端共线、完美分离、分母含 0、Cox 的 time/status 异常、Poisson 非整数。
- Logistic 结果方向反了
- 多为“事件水平”选错。请在 “请下拉选择…表示发生事件” 里重新指定并再部署。
- 计数/率模型报错
- Poisson:结局必须为非负整数;
- Offset:分子、分母均应为非负整数,分母不能为 0。
- Poisson:结局必须为非负整数;
- Cox 报错
- time 非负;status 二分类且明确事件水平;极端分层/稀有事件请合并水平或精简变量。
- 多人共用示例 token 冲突
- 自己注册 shinyapps.io 账户并用个人 token部署到你自己的命名空间。
7.5 生成动态多模型比较预测程序并自动搭建一个互动网站(多模型 Linear/Logistic/Cox/Poisson回归)
7.5.1 用途与概述
本模块用于:在同一数据集上一次性拟合多个回归模型(Linear / Logistic / Cox / Poisson/Offset),比较不同自变量组合的建模结果,并一键部署成可在线互动的预测网站。
- 数据准备已略过:请直接使用你在前序模块已经清洗好的训练集与筛选出的候选因子。
- 核心流程:选择结局类型 → 指定结局/时间/状态 → 设定「要比较的模型数量」与各模型自变量 → 选择置信区间算法 → 生成回归表 → 一键部署到 shinyapps.io。
与「单模型动态 Nomogram」模块相互呼应:此处生成的是多模型对比的交互式预测网站(支持切换模型进行预测),常用于方法比较与敏感性分析的在线展示。
7.5.2 背景与原理
- 为什么需要多模型比较? 同一研究往往存在不同的变量选择策略(比如“临床首选集”“统计筛选集”“去除共线集”等)。将它们并排上线,读者和审稿人可直观看到不同模型下对同一患者的个体化预测差异。
- 实现方式(软件栈):后台基于 R 拟合多个模型对象,调用 R 包 shinyPredict 生成交互页面,再部署到 shinyapps.io,得到公开可访问的网址。
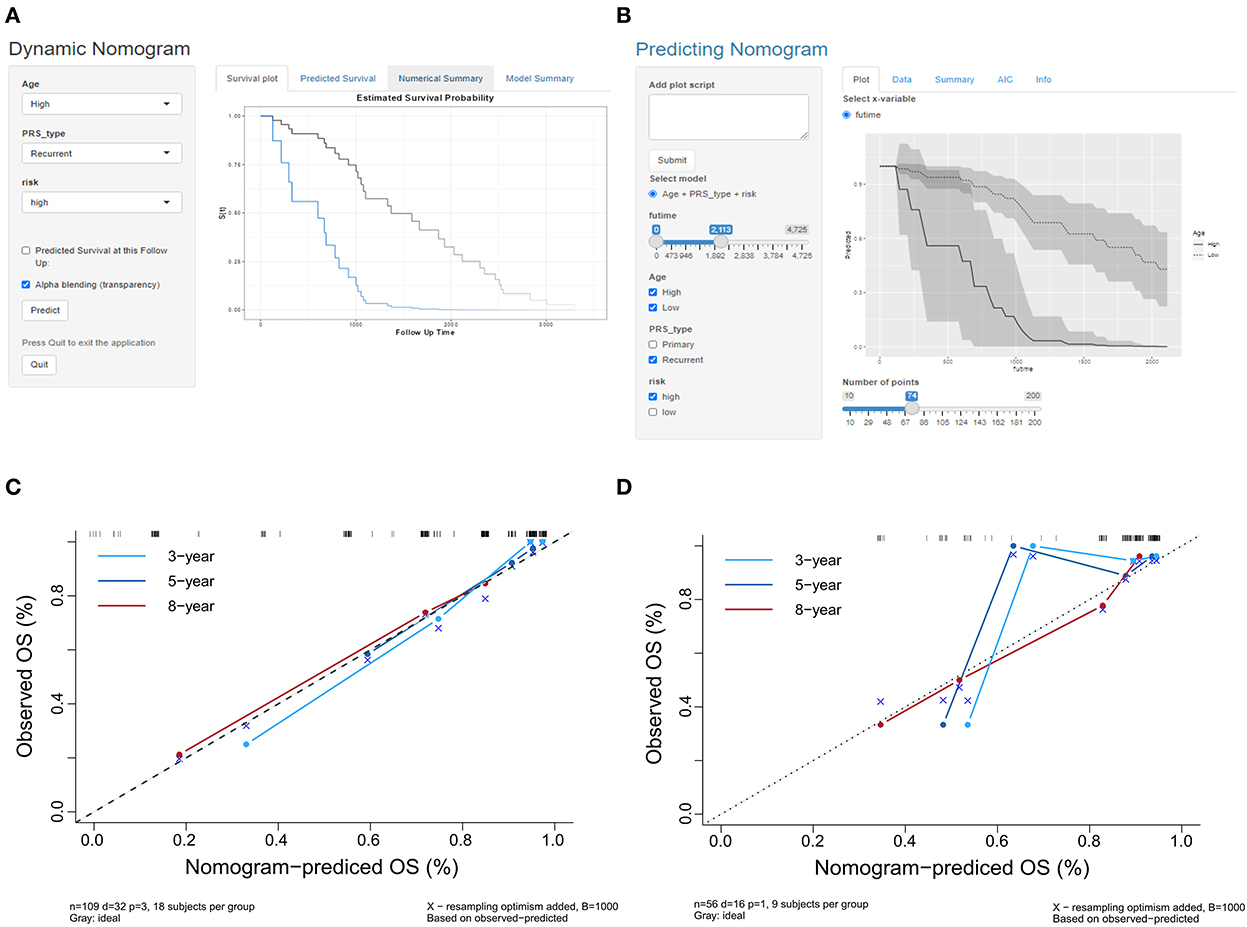
上图论文示例:左图 A 为单模型动态 Nomogram;右图 B 为多模型动态预测,与本模块一致。
7.5.5 选择回归族(family)
在 “选择结局变量的类型” 中四选一(另含 Offset 选项):
- Logistic(二分类)
- Linear(连续)
- Cox(生存:需要时间与状态)
- Poisson(计数:非负整数)
- Offset Poisson(分子/分母形式的率、比、百分比;以
log(分母)为 offset)
7.5.6 指定结局/时间/状态
根据所选族,系统会显示相应控件:
- Logistic
- “请选择结局变量/应变量(二分类)”
- “请下拉选择结局变量的哪个水平表示发生事件”(务必选对;被选水平会编码为 1)
- “请选择结局变量/应变量(二分类)”
- Linear
- “请选择结局变量/应变量(正态连续变量)”
- Cox
- “请选择代表时间的变量”(如 OS、DFS 的随访时长)
- “请选择代表患者最终状态的变量(仅两类)”
- “请下拉选择哪个水平表示发生事件(1=事件,0=删失)”
- “请选择代表时间的变量”(如 OS、DFS 的随访时长)
- Poisson
- “请选择结局变量/应变量(计数资料)”(非负整数)
- Offset Poisson
- “请选择结局变量/应变量的分子(非负整数)”
- “请选择结局变量/应变量的分母(非负整数)”(将作为
log(分母)的 offset)
- “请选择结局变量/应变量的分子(非负整数)”
小贴士
- Cox:time ≥ 0;status仅两类,并明确“事件”水平。
- Poisson/Offset:结局与分母应为非负整数;分母不得为 0。
7.5.8 为每个模型选择自变量(不得留空)
- 在 “模型 i:请选择要纳入多因素分析的自变量(不得留空)” 中多选协变量;可拖拽调整顺序。
- 分类变量需在“定义字段”页设为
factor且水平合理;稀有水平应适度合并。 - 防重复与留空检查:
- 若有模型自变量选择完全相同,顶部会出现红色警告提示重复。
- 若某个模型留空,会提示“不得留空”,请补选自变量。
- 若有模型自变量选择完全相同,顶部会出现红色警告提示重复。
7.5.9 置信区间算法(可选)
在 “用什么方法计算 95% CI” 中二选一:
- Wald CI:与 SPSS/传统软件一致,计算快、与常见 p 值一致。
- Profile likelihood CI:更精确,但可能与基于 Wald 的 p 值略有不一致;多重填补 MI 时请勿选。
7.5.10 生成回归结果表
点击 “生成/更新回归分析表”,右侧输出两类表格:
- 正式回归表格(每个模型一张)
- Logistic / Cox / Poisson / Offset:显示 OR / HR / IRR 及 95% CI、p 值,并附 N 与事件数。
- Linear:显示 回归系数(Beta) 及 95% CI、p 值,并附 N。
- 附录:回归系数表(含标准误)
- 展示 估计值(Estimate) 与 Std. Error(不做指数化),供方法学核查或补充材料使用。
结果解读与排错
- 完美分离/巨大或无穷区间:合并稀有水平、减少共线、检查缺失。
- 不同模型 N 不一致:协变量缺失不同导致。建议在前序模块进行缺失值填补后重算。
- 亚组顺序不理想:回到“调整因子顺序”模块拖拽重排,再生成表格。
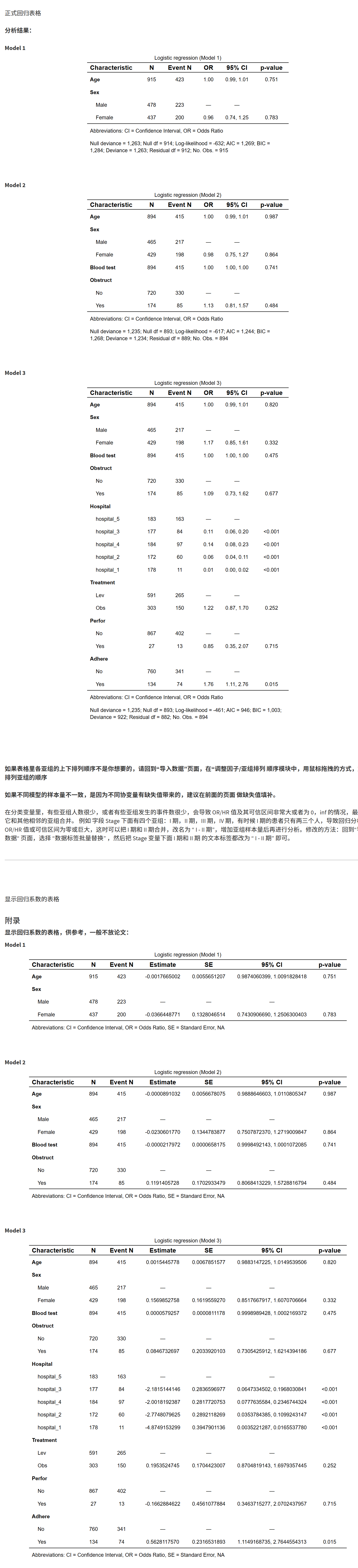
7.5.11 一键部署「多模型比较互动预测网站」
切换到 “部署列线图到公开网站” 页签,依次完成下列步骤。
7.5.11.1 准备部署凭据(Token)
- 打开 https://www.shinyapps.io 注册并登录(必要时使用稳定外网)。
- 左侧 Account → Tokens → Add Token,点击 Show 与 Show secret,复制完整命令
rsconnect::setAccountInfo(name='账户名', token='...', secret='...')
注意:secret可能默认隐藏,请先点击显示再复制。
- 将该命令原样粘贴到页面的 “请输入…token” 文本框中。
> 仅用于部署认证,不会上传你的原始数据;请妥善保管 Token。
临时体验:可使用页面自带示例 Token,将示例网站部署为
https://mstata.shinyapps.io/predict(多人同时测试可能冲突,仅供试用)。
7.5.12 网页端使用与解读(给读者/审稿人)
- 在网页中选择或切换模型(Model 1 / Model 2 / … / Model k)。
- 按需输入(或滑动设定)各协变量的数值/水平。
- 点击 Predict/Update(页面按钮由
shinyPredict自动生成)。
- 页面会根据模型类型自动显示个体化预测与不确定性:
- Logistic:发生概率(及 95% CI)。
- Linear:预测连续值(点估计与区间)。
- Cox:指定时间点的生存概率 / 累积风险等交互输出。
- Poisson/Offset:期望计数/比率/率(及 95% CI)。
- Logistic:发生概率(及 95% CI)。
7.5.13 常见问题与排查
部署失败:Token 无效/权限不足
重新在 shinyapps.io 生成 Token & Secret 并完整粘贴rsconnect::setAccountInfo(...)。在稳定网络下重试。网页打开但预测时灰屏/报错
多为模型/数据问题:完美分离、严重共线、Offset 分母含 0、Poisson 非整数、Cox 的time/status异常等。
回到“回归建模”修正后重新部署(会覆盖旧版本)。Logistic 方向不对
多因“事件水平”选错。请在 “请下拉选择…表示发生事件” 里重新指定并再部署。多人共用示例 Token 冲突
自行注册 shinyapps.io 并用个人 Token部署到你自己的命名空间。